1.大模型开发范式



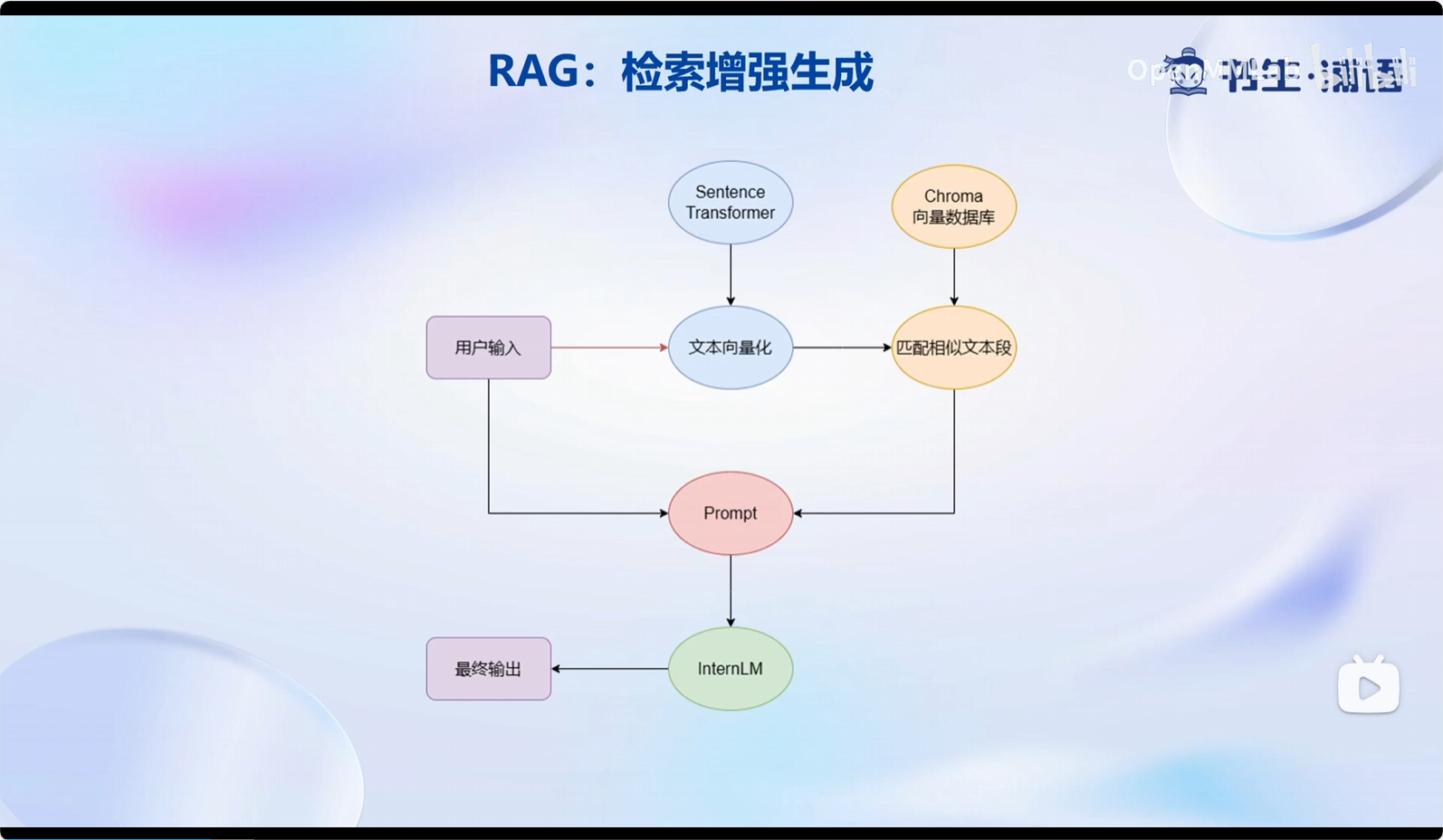
RAG(Retrieval-Augmented Generation 检索增强生成):通过给大模型外挂一个知识库,在每次提问生成中,会首先从知识库中匹配到提问对应回答的相关文档,之后将文档和提问一起交给大模型进行生成回答,从而提高大模型的知识储备
Finetune(模型微调):在一个新的较小的训练集上,进行轻量级的训练微调,从而提升模型在中国新数据集上的能力
优劣势对比
| RAG | Finetune | |
|---|---|---|
| 优势: | 成本低且可实时更新 | 可个性化微调,知识覆盖面广 |
| 劣势: | 受到基座模型影响大,且单次回答知识有限 | 成本高昂,无法实时更新 |
2.LangChain 简介

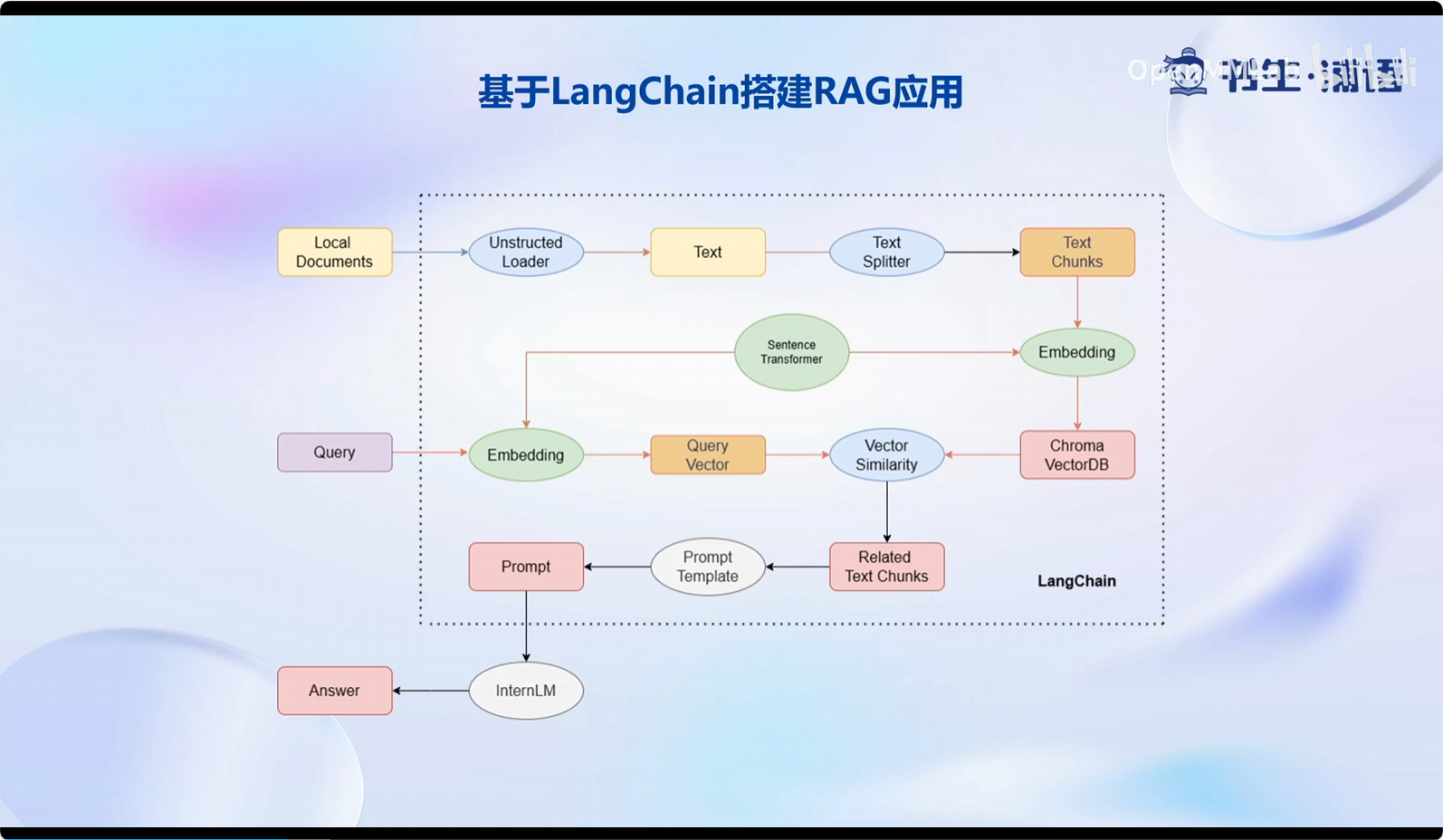
3.构建向量数据库

4.搭建知识库助手


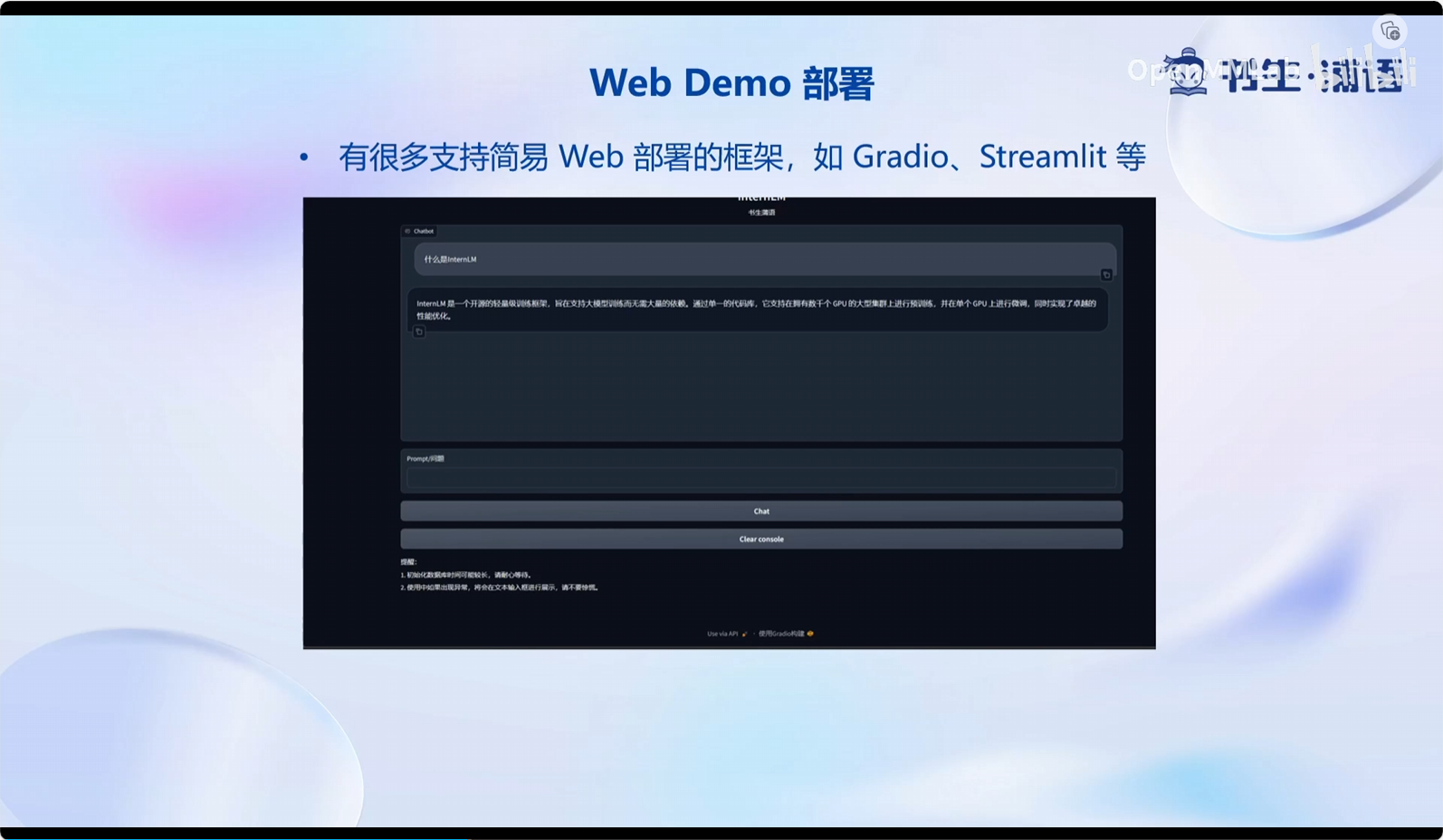
- Web Demo 部署
6 .动手实战环节
6.1环境配置
配置一个新的conda环境,并装一些基础包
bash
/root/share/install_conda_env_internlm_base.sh InternLM
conda activate InternLM
# 升级pip
python -m pip install --upgrade pip
pip install modelscope==1.9.5
pip install transformers==4.35.2
pip install streamlit==1.24.0
pip install sentencepiece==0.1.99
pip install accelerate==0.24.16.1.2模型下载
在本地的 /root/share/temp/model_repos/internlm-chat-7b 目录下已存储有所需的模型文件参数,可以直接拷贝到个人目录的模型保存地址:
mkdir -p /root/data/model/Shanghai_AI_Laboratory
cp -r /root/share/temp/model_repos/internlm-chat-7b /root/data/model/Shanghai_AI_Laboratory/internlm-chat-7b6.1.3 LangChain 相关环境配置
在已完成 InternLM 的部署基础上,还需要安装以下依赖包:
pip install langchain==0.0.292
pip install gradio==4.4.0
pip install chromadb==0.4.15
pip install sentence-transformers==2.2.2
pip install unstructured==0.10.30
pip install markdown==3.3.7同时,我们需要使用到开源词向量模型 Sentence Transformer:(我们也可以选用别的开源词向量模型来进行 Embedding,目前选用这个模型是相对轻量、支持中文且效果较好的,同学们可以自由尝试别的开源词向量模型)
首先需要使用 huggingface 官方提供的 huggingface-cli 命令行工具。安装依赖:
pip install -U huggingface_hub然后在和 /root/data 目录下新建python文件 download_hf.py,填入以下代码:
- resume-download:断点续下
- local-dir:本地存储路径。(linux环境下需要填写绝对路径)
import os
# 下载模型
os.system('huggingface-cli download --resume-download sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 --local-dir /root/data/model/sentence-transformer')但是,使用 huggingface 下载可能速度较慢,我们可以使用 huggingface 镜像下载。与使用hugginge face下载相同,只需要填入镜像地址即可。
将 download_hf.py 中的代码修改为以下代码:
import os
# 设置环境变量
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
# 下载模型
os.system('huggingface-cli download --resume-download sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 --local-dir /root/data/model/sentence-transformer')然后,在 /root/data 目录下执行该脚本即可自动开始下载:
python download_hf.py
6.1.4 下载 NLTK 相关资源
我们在使用开源词向量模型构建开源词向量的时候,需要用到第三方库 nltk 的一些资源。正常情况下,其会自动从互联网上下载,但可能由于网络原因会导致下载中断,此处我们可以从国内仓库镜像地址下载相关资源,保存到服务器上。
我们用以下命令下载 nltk 资源并解压到服务器上:
cd /root
git clone https://gitee.com/yzy0612/nltk_data.git --branch gh-pages
cd nltk_data
mv packages/* ./
cd tokenizers
unzip punkt.zip
cd ../taggers
unzip averaged_perceptron_tagger.zip之后使用时服务器即会自动使用已有资源,无需再次下载。
6.1.5 下载本项目代码
下载提供的脚本库
cd /root/data
git clone https://github.com/InternLM/tutorial6.2 知识库搭建
6.2.1 数据收集
我们选择由上海人工智能实验室开源的一系列大模型工具开源仓库作为语料库来源,下载相关仓库
# 进入到数据库盘
cd /root/data
# clone 上述开源仓库
git clone https://gitee.com/open-compass/opencompass.git
git clone https://gitee.com/InternLM/lmdeploy.git
git clone https://gitee.com/InternLM/xtuner.git
git clone https://gitee.com/InternLM/InternLM-XComposer.git
git clone https://gitee.com/InternLM/lagent.git
git clone https://gitee.com/InternLM/InternLM.git6.2.2 知识库搭建
在/root/data/demo下创建create_db.py
# 首先导入所需第三方库
from langchain.document_loaders import UnstructuredFileLoader
from langchain.document_loaders import UnstructuredMarkdownLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
from tqdm import tqdm
import os
# 获取文件路径函数
def get_files(dir_path):
# args:dir_path,目标文件夹路径
file_list = []
for filepath, dirnames, filenames in os.walk(dir_path):
# os.walk 函数将递归遍历指定文件夹
for filename in filenames:
# 通过后缀名判断文件类型是否满足要求
if filename.endswith(".md"):
# 如果满足要求,将其绝对路径加入到结果列表
file_list.append(os.path.join(filepath, filename))
elif filename.endswith(".txt"):
file_list.append(os.path.join(filepath, filename))
return file_list
# 加载文件函数
def get_text(dir_path):
# args:dir_path,目标文件夹路径
# 首先调用上文定义的函数得到目标文件路径列表
file_lst = get_files(dir_path)
# docs 存放加载之后的纯文本对象
docs = []
# 遍历所有目标文件
for one_file in tqdm(file_lst):
file_type = one_file.split('.')[-1]
if file_type == 'md':
loader = UnstructuredMarkdownLoader(one_file)
elif file_type == 'txt':
loader = UnstructuredFileLoader(one_file)
else:
# 如果是不符合条件的文件,直接跳过
continue
docs.extend(loader.load())
return docs
# 目标文件夹
tar_dir = [
"/root/data/InternLM",
"/root/data/InternLM-XComposer",
"/root/data/lagent",
"/root/data/lmdeploy",
"/root/data/opencompass",
"/root/data/xtuner"
]
# 加载目标文件
docs = []
for dir_path in tar_dir:
docs.extend(get_text(dir_path))
# 对文本进行分块
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500, chunk_overlap=150)
split_docs = text_splitter.split_documents(docs)
# 加载开源词向量模型
embeddings = HuggingFaceEmbeddings(model_name="/root/data/model/sentence-transformer")
# 构建向量数据库
# 定义持久化路径
persist_directory = 'data_base/vector_db/chroma'
# 加载数据库
vectordb = Chroma.from_documents(
documents=split_docs,
embedding=embeddings,
persist_directory=persist_directory # 允许我们将persist_directory目录保存到磁盘上
)
# 将加载的向量数据库持久化到磁盘上
vectordb.persist()保存运行后,demo目录下会生成一个data_base目录
6.3 InternLM 接入 LangChain
在/root/data/demo下创建LLM.py
from langchain.llms.base import LLM
from typing import Any, List, Optional
from langchain.callbacks.manager import CallbackManagerForLLMRun
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
class InternLM_LLM(LLM):
# 基于本地 InternLM 自定义 LLM 类
tokenizer : AutoTokenizer = None
model: AutoModelForCausalLM = None
def __init__(self, model_path :str):
# model_path: InternLM 模型路径
# 从本地初始化模型
super().__init__()
print("正在从本地加载模型...")
self.tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
self.model = AutoModelForCausalLM.from_pretrained(model_path, trust_remote_code=True).to(torch.bfloat16).cuda()
self.model = self.model.eval()
print("完成本地模型的加载")
def _call(self, prompt : str, stop: Optional[List[str]] = None,
run_manager: Optional[CallbackManagerForLLMRun] = None,
**kwargs: Any):
# 重写调用函数
system_prompt = """You are an AI assistant whose name is InternLM (书生·浦语).
- InternLM (书生·浦语) is a conversational language model that is developed by Shanghai AI Laboratory (上海人工智能实验室). It is designed to be helpful, honest, and harmless.
- InternLM (书生·浦语) can understand and communicate fluently in the language chosen by the user such as English and 中文.
"""
messages = [(system_prompt, '')]
response, history = self.model.chat(self.tokenizer, prompt , history=messages)
return response
@property
def _llm_type(self) -> str:
return "InternLM"
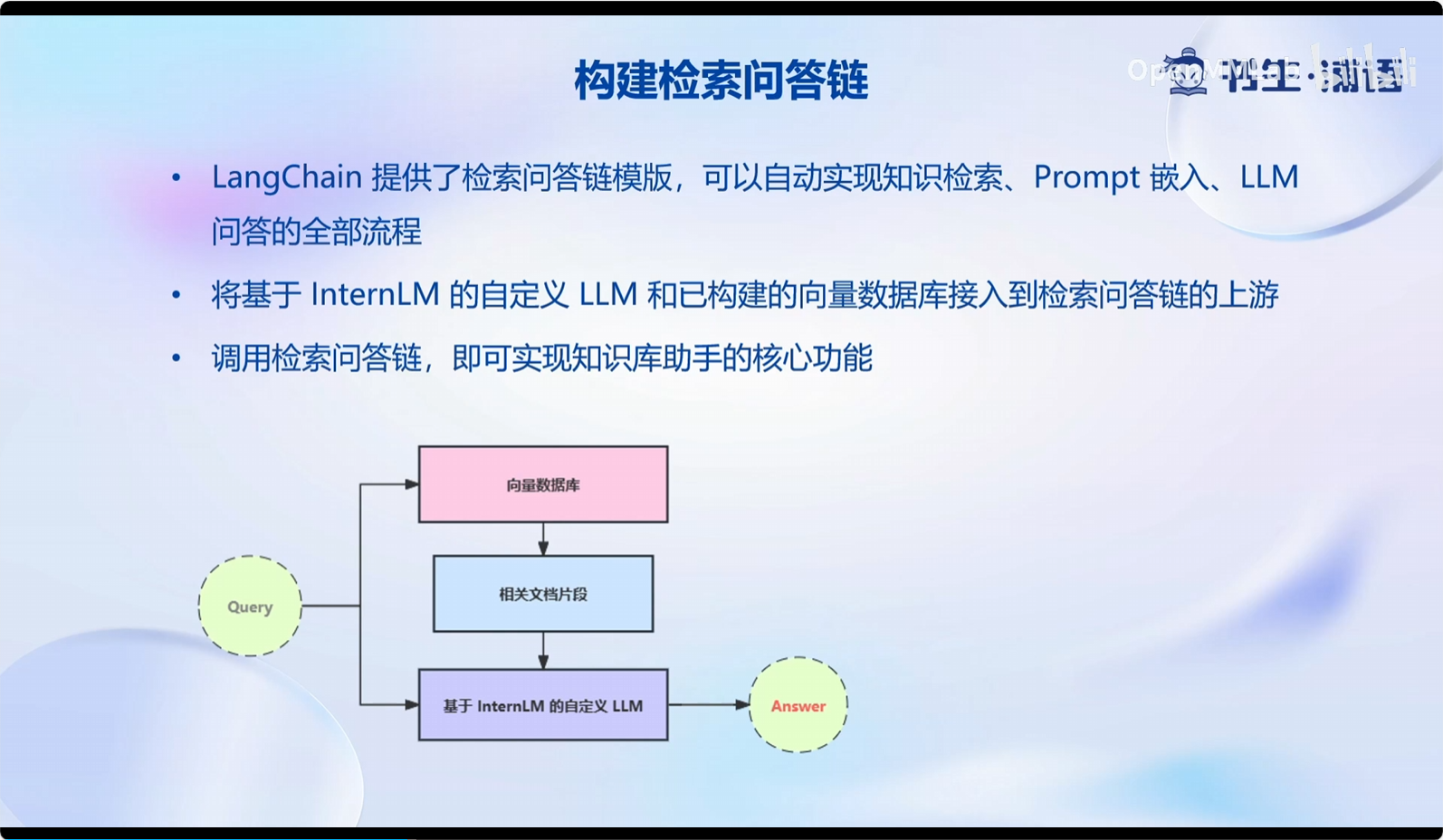
6.4 构建检索问答链
在/root/data/demo下创建web_demo.py
from langchain.vectorstores import Chroma
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
import os
from LLM import InternLM_LLM
from langchain.prompts import PromptTemplate
from langchain.chains import RetrievalQA
import gradio as gr
def load_chain():
# 加载问答链
# 定义 Embeddings
embeddings = HuggingFaceEmbeddings(model_name="/root/data/model/sentence-transformer")
# 向量数据库持久化路径
persist_directory = 'data_base/vector_db/chroma'
# 加载数据库
vectordb = Chroma(
persist_directory=persist_directory, # 允许我们将persist_directory目录保存到磁盘上
embedding_function=embeddings
)
# 加载自定义 LLM
llm = InternLM_LLM(model_path = "/root/data/model/Shanghai_AI_Laboratory/internlm-chat-7b")
# 定义一个 Prompt Template
template = """使用以下上下文来回答最后的问题。如果你不知道答案,就说你不知道,不要试图编造答
案。尽量使答案简明扼要。总是在回答的最后说“谢谢你的提问!”。
{context}
问题: {question}
有用的回答:"""
QA_CHAIN_PROMPT = PromptTemplate(input_variables=["context","question"],template=template)
# 运行 chain
qa_chain = RetrievalQA.from_chain_type(llm,retriever=vectordb.as_retriever(),return_source_documents=True,chain_type_kwargs={"prompt":QA_CHAIN_PROMPT})
return qa_chain
class Model_center():
"""
存储检索问答链的对象
"""
def __init__(self):
# 构造函数,加载检索问答链
self.chain = load_chain()
def qa_chain_self_answer(self, question: str, chat_history: list = []):
"""
调用问答链进行回答
"""
if question == None or len(question) < 1:
return "", chat_history
try:
chat_history.append(
(question, self.chain({"query": question})["result"]))
# 将问答结果直接附加到问答历史中,Gradio 会将其展示出来
return "", chat_history
except Exception as e:
return e, chat_history
# 实例化核心功能对象
model_center = Model_center()
# 创建一个 Web 界面
block = gr.Blocks()
with block as demo:
with gr.Row(equal_height=True):
with gr.Column(scale=15):
# 展示的页面标题
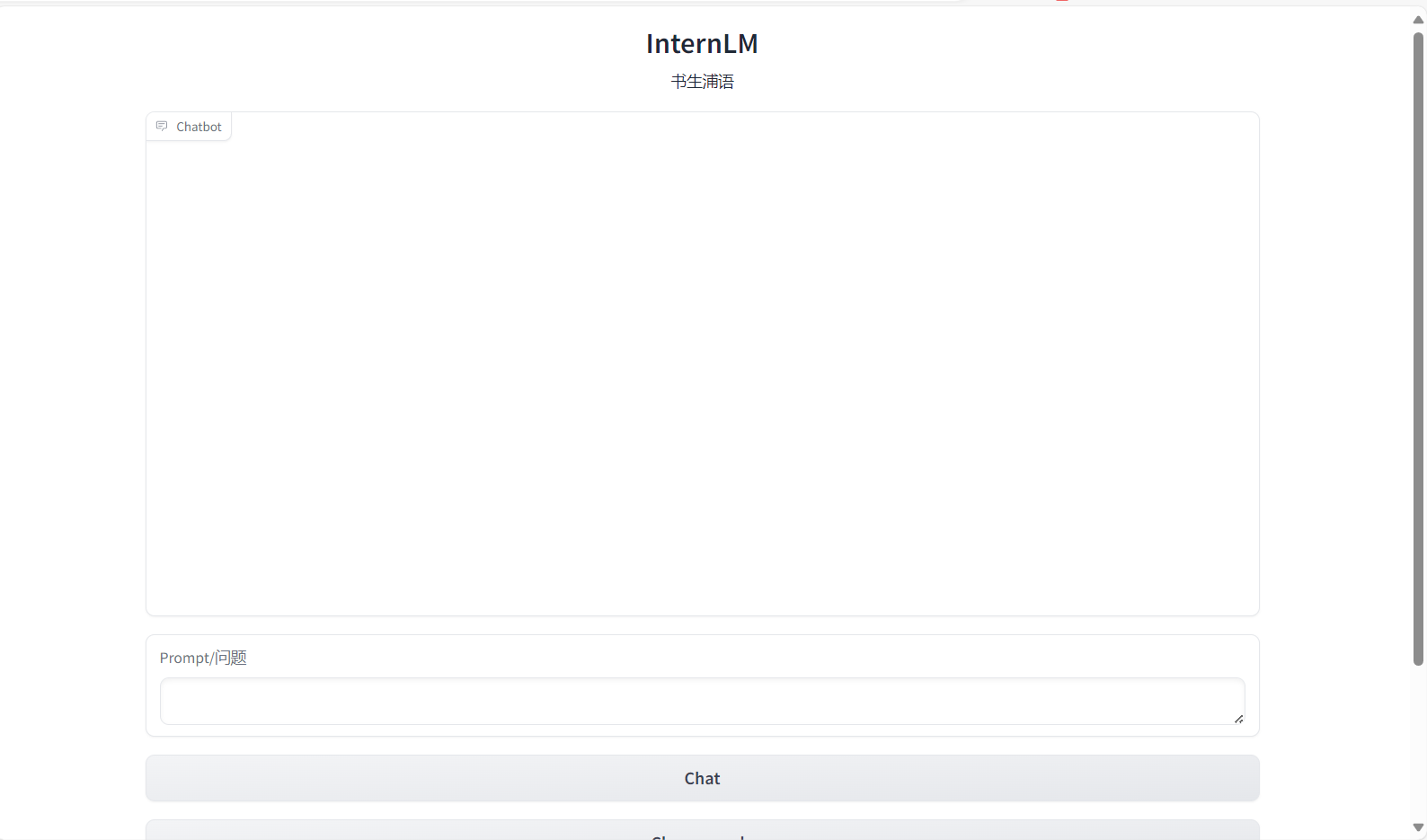
gr.Markdown("""<h1><center>InternLM</center></h1>
<center>书生浦语</center>
""")
with gr.Row():
with gr.Column(scale=4):
# 创建一个聊天机器人对象
chatbot = gr.Chatbot(height=450, show_copy_button=True)
# 创建一个文本框组件,用于输入 prompt。
msg = gr.Textbox(label="Prompt/问题")
with gr.Row():
# 创建提交按钮。
db_wo_his_btn = gr.Button("Chat")
with gr.Row():
# 创建一个清除按钮,用于清除聊天机器人组件的内容。
clear = gr.ClearButton(
components=[chatbot], value="Clear console")
# 设置按钮的点击事件。当点击时,调用上面定义的 qa_chain_self_answer 函数,并传入用户的消息和聊天历史记录,然后更新文本框和聊天机器人组件。
db_wo_his_btn.click(model_center.qa_chain_self_answer, inputs=[
msg, chatbot], outputs=[msg, chatbot])
gr.Markdown("""提醒:<br>
1. 初始化数据库时间可能较长,请耐心等待。
2. 使用中如果出现异常,将会在文本输入框进行展示,请不要惊慌。 <br>
""")
gr.close_all()
# 直接启动
demo.launch()运行脚本,成功运行后,访问http://127.0.0.1:7860
Comments NOTHING