api接入参考教程 第二章 使用 LLM API 开发应用
1. 使用 ChatGPT
这里我以openAI为例
(因国内无法正常使用,故使用第三方代理接口,我用都是api2d,与原生openai接口使用方式差不多)
注册好api2d,我们需要在.env中填写我们的接口地址和密钥
# OPENAI API 访问密钥配置
OPENAI_API_KEY = "你的api key"
#C2所需api域名变量
OPENAI_BASE_URL = "https://oa.api2d.net/v1"
下面是读取 .env 文件的代码:
import os
from dotenv import load_dotenv, find_dotenv
# 读取本地/项目的环境变量。
# find_dotenv() 寻找并定位 .env 文件的路径
# load_dotenv() 读取该 .env 文件,并将其中的环境变量加载到当前的运行环境中
# 如果你设置的是全局的环境变量,这行代码则没有任何作用。
_ = load_dotenv(find_dotenv())
# 如果你需要通过代理端口访问,还需要做如下配置(我们设置了第三方api接口,故不用设置)
# os.environ['HTTPS_PROXY'] = 'http://127.0.0.1:7890'
# os.environ["HTTP_PROXY"] = 'http://127.0.0.1:7890'1.2 调用 OpenAI API
调用 ChatGPT 需要使用 ChatCompletion API,该 API 提供了 ChatGPT 系列模型的调用,包括 ChatGPT-3.5,GPT-4 等。
ChatCompletion API 调用方法如下:
from openai import OpenAI
client = OpenAI(
# This is the default and can be omitted
api_key=os.environ.get("OPENAI_API_KEY"),
)
# 导入所需库
# 注意,此处我们假设你已根据上文配置了 OpenAI API Key,如没有将访问失败
completion = client.chat.completions.create(
# 调用模型:ChatGPT-3.5
model="gpt-3.5-turbo",
# messages 是对话列表
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello!"}
]
)Copy to clipboardErrorCopied调用该 API 会返回一个 ChatCompletion 对象,其中包括了回答文本、创建时间、id 等属性。我们一般需要的是回答文本,也就是回答对象中的 content 信息。
completionChatCompletion(id='chatcmpl-9IAyjWaeTnRtX3kbVhtEV0cFNFsRB', choices=[Choice(finish_reason='stop', index=0, logprobs=None, message=ChatCompletionMessage(content='Hello! How can I assist you today?', role='assistant', function_call=None, tool_calls=None))], created=1714119133, model='gpt-3.5-turbo-0125', object='chat.completion', system_fingerprint='fp_3b956da36b', usage=CompletionUsage(completion_tokens=9, prompt_tokens=19, total_tokens=28, pre_token_count=16384, pre_total=124, adjust_total=123, final_total=1))print(completion.choices[0].message.content)Copy to clipboardErrorCopiedHello! How can I assist you today?Copy to clipboardErrorCopied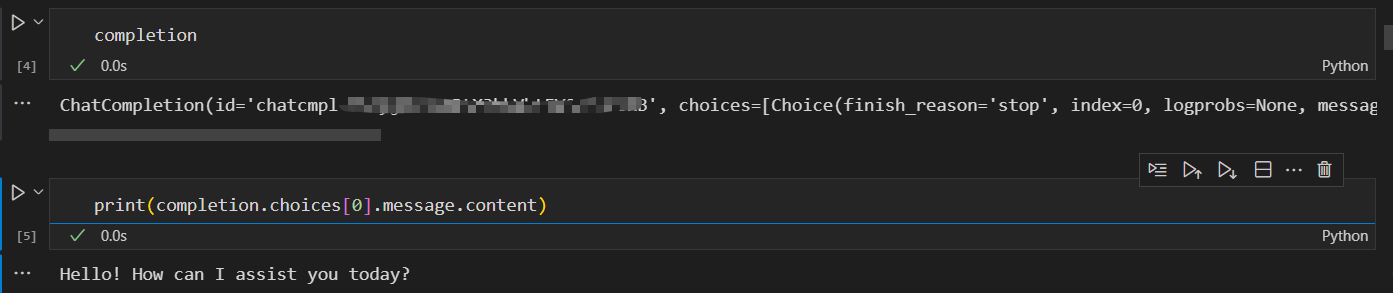
此处我们详细介绍调用 API 常会用到的几个参数:
· model,即调用的模型,一般取值包括“gpt-3.5-turbo”(ChatGPT-3.5)、“gpt-3.5-turbo-16k-0613”(ChatGPT-3.5 16K 版本)、“gpt-4”(ChatGPT-4)。注意,不同模型的成本是不一样的。
· messages,即我们的 prompt。ChatCompletion 的 messages 需要传入一个列表,列表中包括多个不同角色的 prompt。我们可以选择的角色一般包括 system:即前文中提到的 system prompt;user:用户输入的 prompt;assistant:助手,一般是模型历史回复,作为提供给模型的参考内容。
· temperature,温度。即前文中提到的 Temperature 系数。
· max_tokens,最大 token 数,即模型输出的最大 token 数。OpenAI 计算 token 数是合并计算 Prompt 和 Completion 的总 token 数,要求总 token 数不能超过模型上限(如默认模型 token 上限为 4096)。因此,如果输入的 prompt 较长,需要设置较大的 max_token 值,否则会报错超出限制长度。OpenAI 提供了充分的自定义空间,支持我们通过自定义 prompt 来提升模型回答效果,如下是一个简单的封装 OpenAI 接口的函数,支持我们直接传入 prompt 并获得模型的输出:
from openai import OpenAI
client = OpenAI(
# This is the default and can be omitted
api_key=os.environ.get("OPENAI_API_KEY"),
)
def gen_gpt_messages(prompt):
'''
构造 GPT 模型请求参数 messages
请求参数:
prompt: 对应的用户提示词
'''
messages = [{"role": "user", "content": prompt}]
return messages
def get_completion(prompt, model="gpt-3.5-turbo", temperature = 0):
'''
获取 GPT 模型调用结果
请求参数:
prompt: 对应的提示词
model: 调用的模型,默认为 gpt-3.5-turbo,也可以按需选择 gpt-4 等其他模型
temperature: 模型输出的温度系数,控制输出的随机程度,取值范围是 0~2。温度系数越低,输出内容越一致。
'''
response = client.chat.completions.create(
model=model,
messages=gen_gpt_messages(prompt),
temperature=temperature,
)
if len(response.choices) > 0:
return response.choices[0].message.content
return "generate answer error"Copy to clipboardErrorCopied
get_completion("你好")Copy to clipboardErrorCopied
'你好!有什么可以帮助你的吗?'Copy to clipboardErrorCopied在上述函数中,我们封装了 messages 的细节,仅使用 user prompt 来实现调用。在简单场景中,该函数足够满足使用需求。
这里我以文心一言的api示例为演示
2. 使用文心一言
文心一言,由百度于 2023 年 3 月 27 日推出的中文大模型,是目前国内大语言模型的代表产品。受限于中文语料质量差异及国内计算资源、计算技术瓶颈,文心一言在整体性能上距离 ChatGPT 仍有一定差异,但在中文语境下已展现出了较为优越的性能。文心一言所考虑的落地场景包括多模态生成、文学创作等多种商业场景,其目标是在中文语境下赶超 ChatGPT。当然,要真正战胜 ChatGPT,百度还有很长的路要走;但在生成式 AI 监管较为严格的国内,作为第一批被允许向公众开放的生成式 AI 应用,文心一言相对无法被公开使用的 ChatGPT 还是具备一定商业上的优势。
百度同样提供了文心一言的 API 接口,其在推出大模型的同时,也推出了 文心千帆 企业级大语言模型服务平台,包括了百度整套大语言模型开发工作链。对于不具备大模型实际落地能力的中小企业或传统企业,考虑文心千帆是一个可行的选择。当然,本教程仅包括通过文心千帆平台调用文心一言 API,对于其他企业级服务不予讨论。
2.1 API 申请指引
[获取密钥](https://datawhalechina.github.io/llm-universe/#/C2/2. 使用 LLM API?id=获取密钥)
百度智能云千帆大模型平台提供了多种语言的千帆 SDK,开发者可使用 SDK,快捷地开发功能,提升开发效率。
在使用千帆 SDK 之前,需要先获取文心一言调用密钥,在代码中需要配置自己的密钥才能实现对模型的调用,下面我们以 Python SDK为例,介绍通过千帆 SDK 调用文心模型的流程。
首先需要有一个经过实名认证的百度账号,每一个账户可以创建若干个应用,每个应用会对应一个 API_Key 和 Secret_Key。
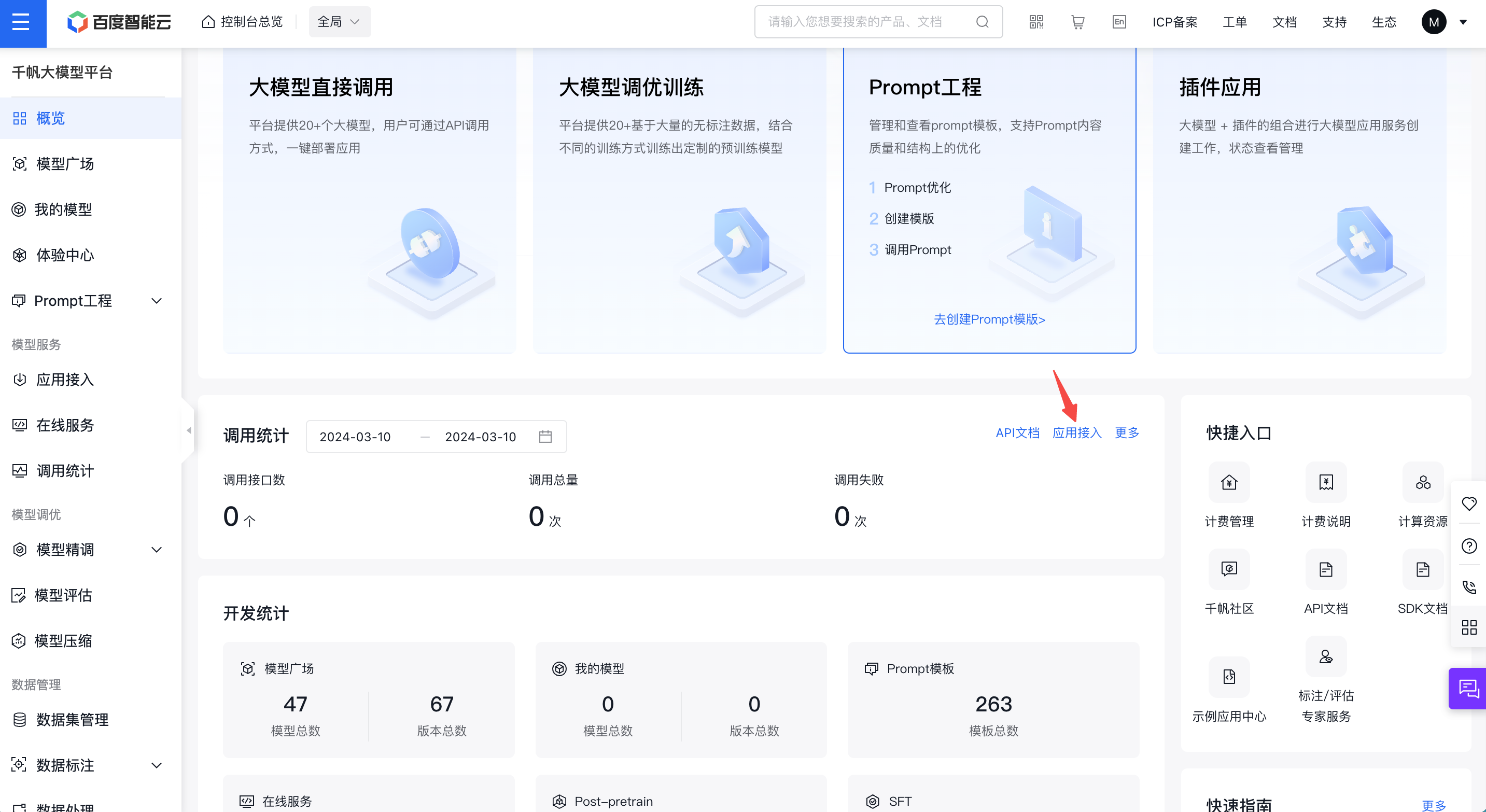
进入文心千帆服务平台,点击上述应用接入按钮,创建一个调用文心大模型的应用。
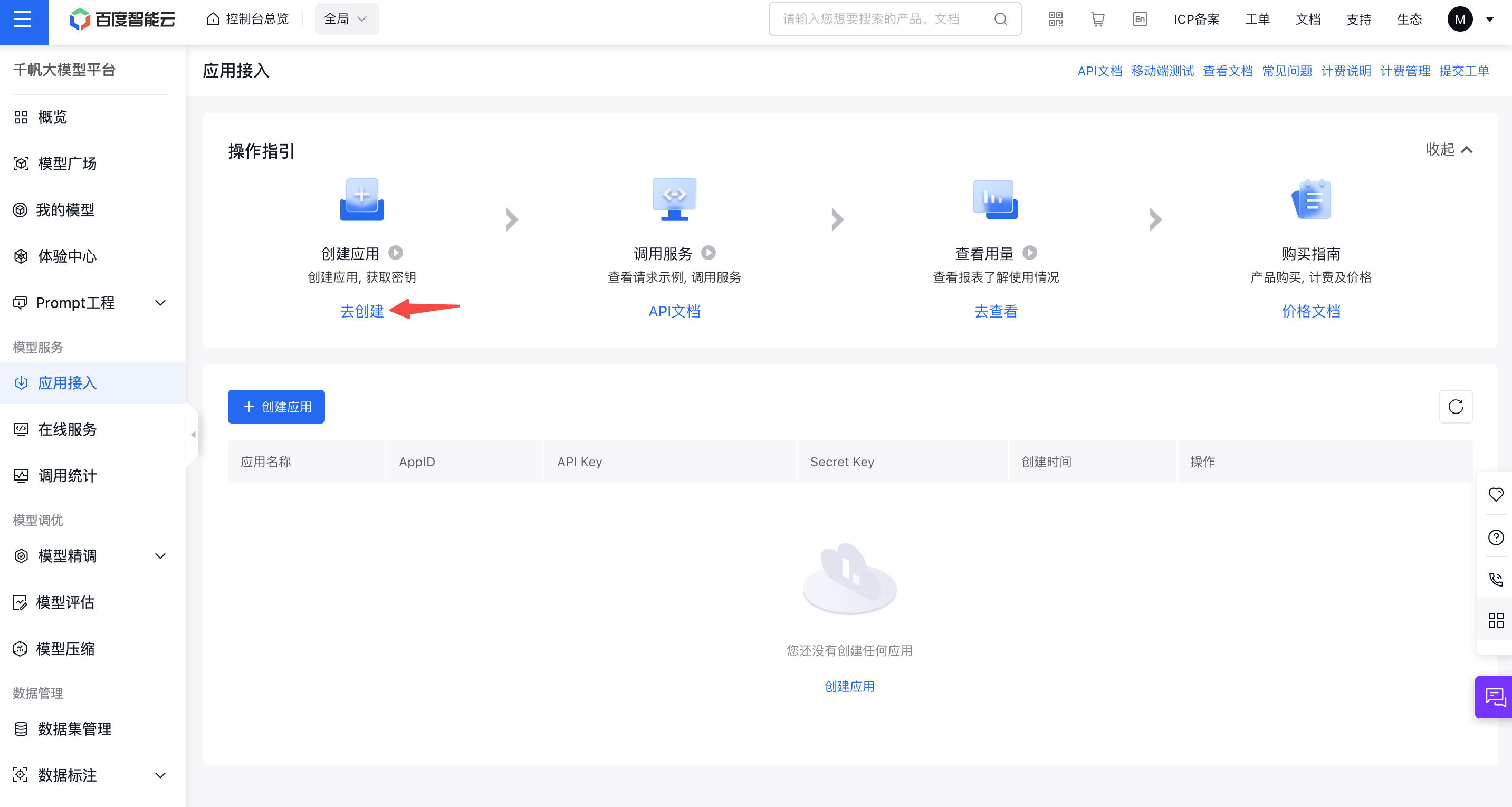
接着点击去创建按钮,进入应用创建界面:
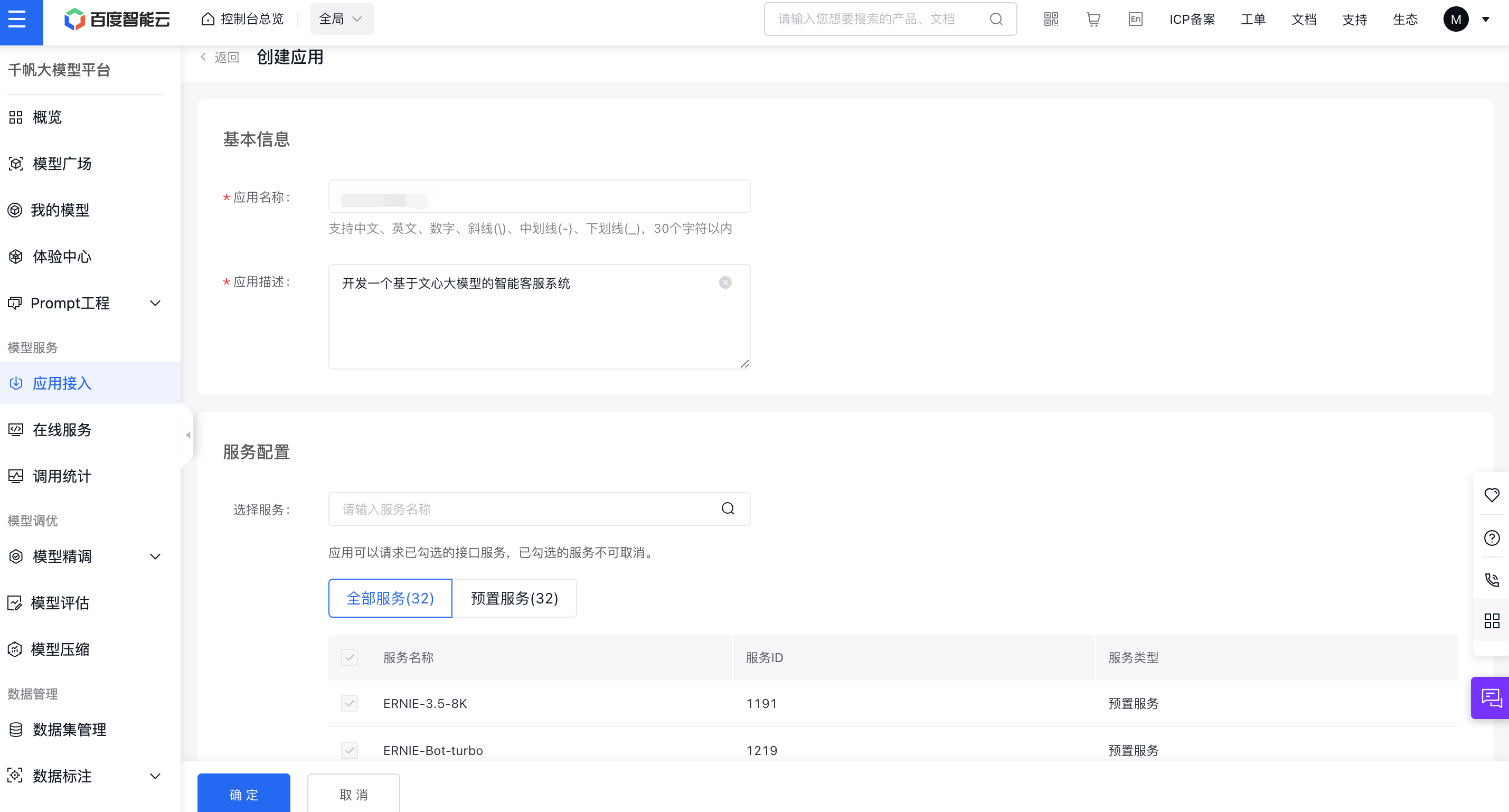
简单输入基本信息,选择默认配置,创建应用即可。
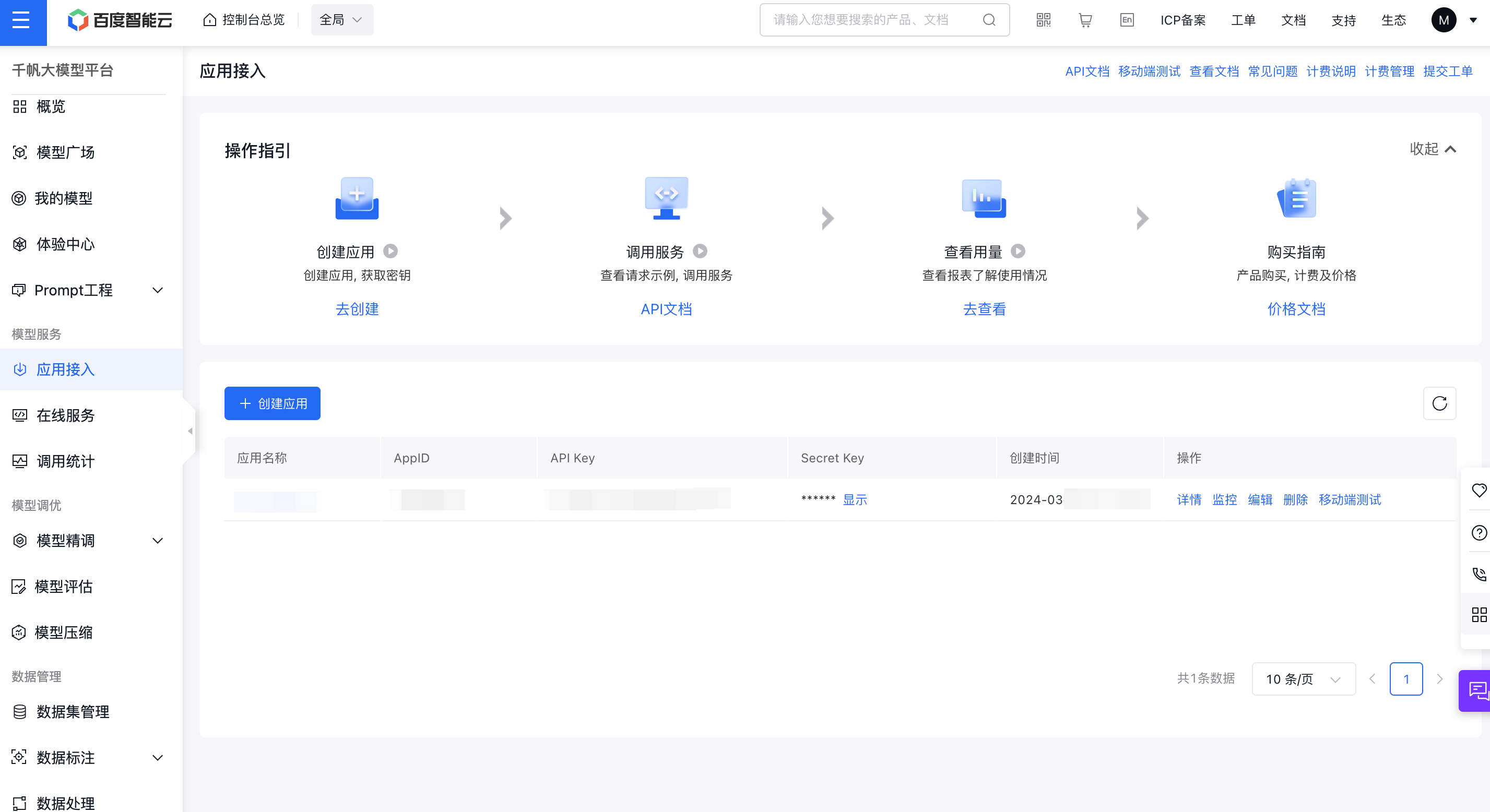
创建完成后,我们可以在控制台看到创建的应用的 API Key、Secret Key。
需要注意的是,千帆目前只有 Prompt模板、Yi-34B-Chat 和 Fuyu-8B公有云在线调用体验服务这三个服务是免费调用的,如果你想体验其他的模型服务,需要在计费管理处开通相应模型的付费服务才能体验。
我们将这里获取到的 API Key、Secret Key 填写至 .env 文件的 QIANFAN_AK 和 QIANFAN_SK 参数。如果你使用的是安全认证的参数校验,需要在百度智能云控制台-用户账户-安全认证页,查看 Access Key、Secret Key,并将获取到的参数相应的填写到 .env 文件的 QIANFAN_ACCESS_KEY、QIANFAN_SECRET_KEY。
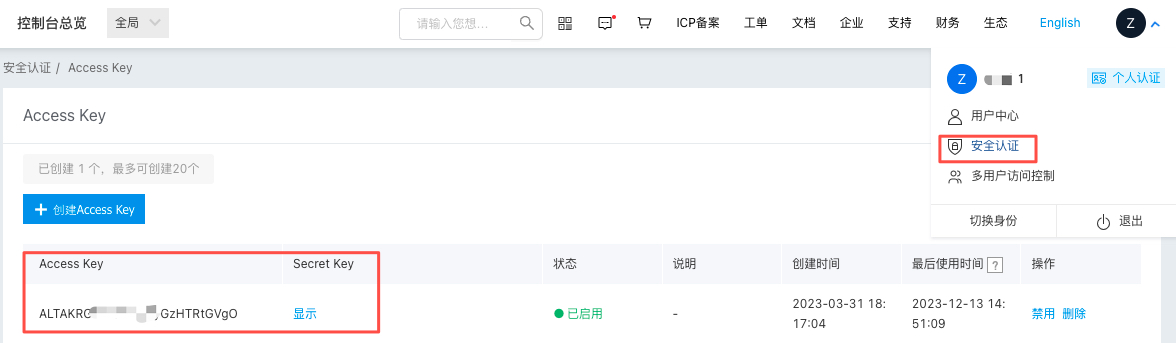
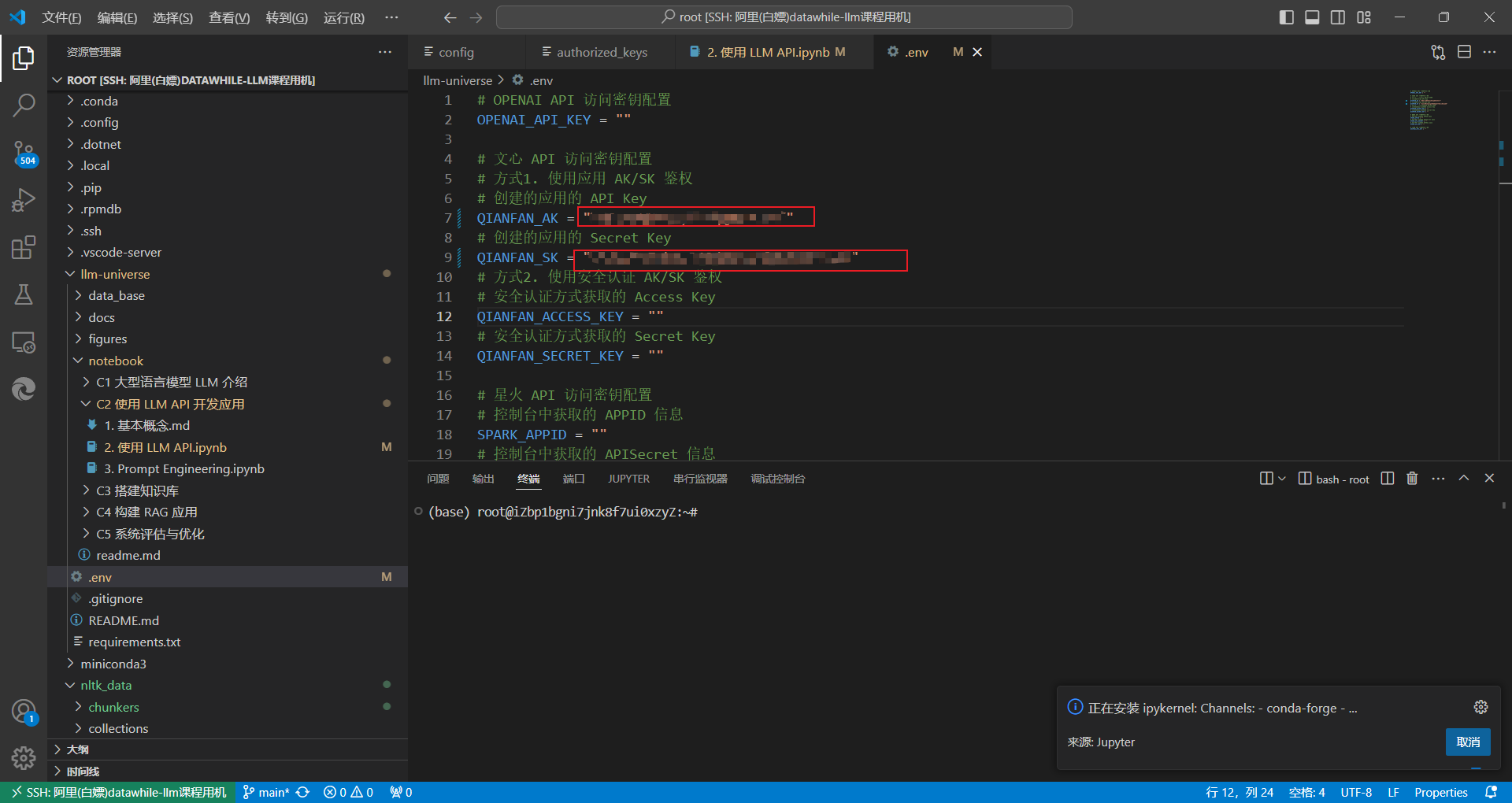
然后执行以下代码,将密钥加载到环境变量中。
from dotenv import load_dotenv, find_dotenv
# 读取本地/项目的环境变量。
# find_dotenv() 寻找并定位 .env 文件的路径
# load_dotenv() 读取该 .env 文件,并将其中的环境变量加载到当前的运行环境中
# 如果你设置的是全局的环境变量,这行代码则没有任何作用。
_ = load_dotenv(find_dotenv())2.2 调用文心千帆 API
百度文心同样支持在传入参数的 messages 字段中配置 user、assistant 两个成员角色的 prompt,但与 OpenAI 的 prompt 格式不同的是,模型人设是通过另一个参数 system 字段传入的,而不是在 messages 字段中。
下面我们使用 SDK,封装一个 get_completion 函数供后续使用。
再次提醒读者:如果账户中没有免费的或者购买的额度,在执行下述代码调用文心 ERNIE-Bot 时,会有如下报错:error code: 17, err msg: Open api daily request limit reached。
点击模型服务可以查看千帆支持的全部模型列表。
import qianfan
def gen_wenxin_messages(prompt):
'''
构造文心模型请求参数 messages
请求参数:
prompt: 对应的用户提示词
'''
messages = [{"role": "user", "content": prompt}]
return messages
def get_completion(prompt, model="ERNIE-Bot", temperature=0.01):
'''
获取文心模型调用结果
请求参数:
prompt: 对应的提示词
model: 调用的模型,默认为 ERNIE-Bot,也可以按需选择 ERNIE-Bot-4 等其他模型
temperature: 模型输出的温度系数,控制输出的随机程度,取值范围是 0~1.0,且不能设置为 0。温度系数越低,输出内容越一致。
'''
chat_comp = qianfan.ChatCompletion()
message = gen_wenxin_messages(prompt)
resp = chat_comp.do(messages=message,
model=model,
temperature = temperature,
system="你是一名个人助理-小鲸鱼")
return resp["result"]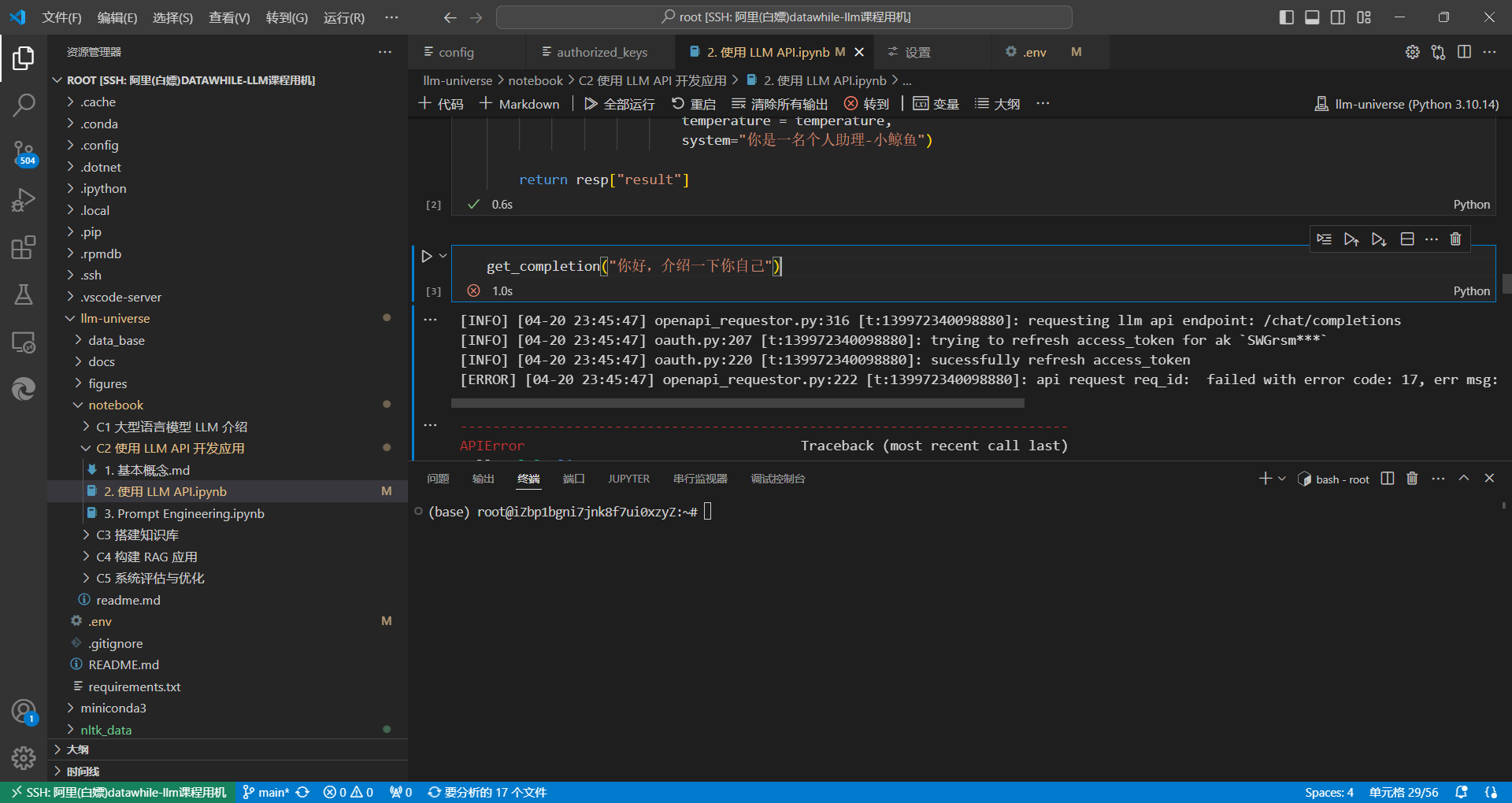
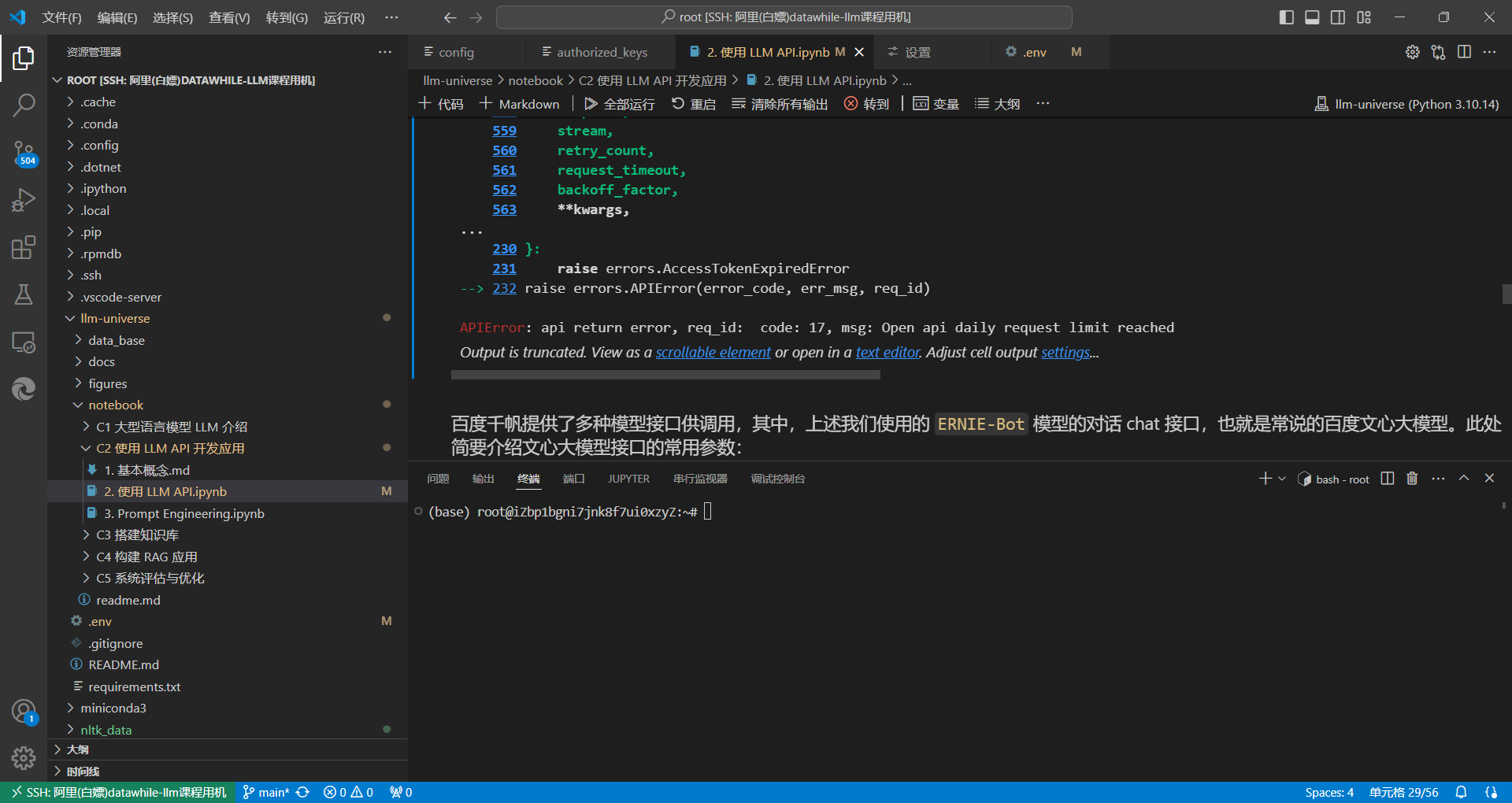
因为你是免费用户,在使用上述函数时,可以在入参中指定一个免费的模型(例如 Yi-34B-Chat)再运行:
get_completion("你好,介绍一下你自己", model="Yi-34B-Chat")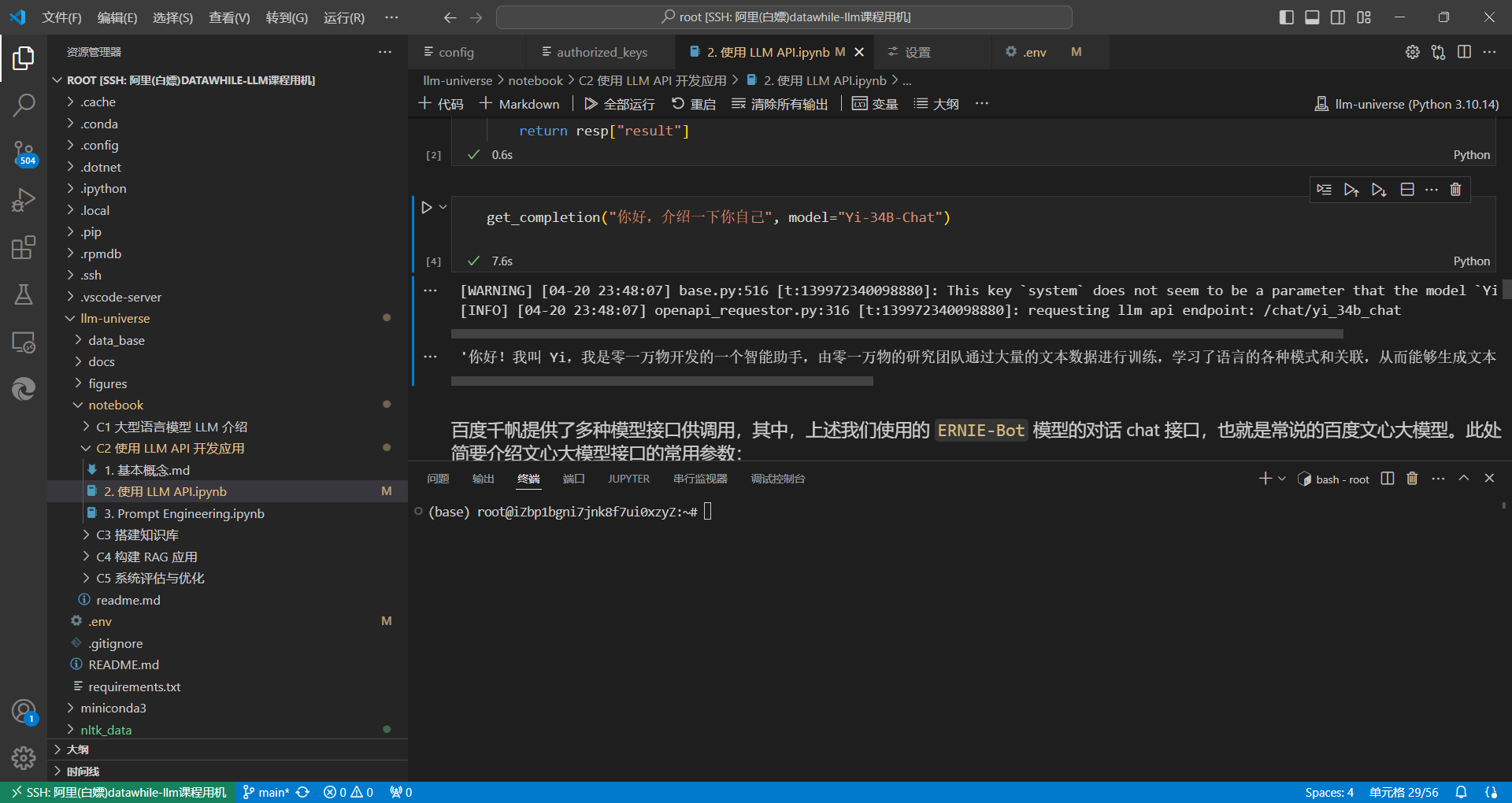
于是终于不报错啦!正常返回回复
百度千帆提供了多种模型接口供调用,其中,上述我们使用的 ERNIE-Bot 模型的对话 chat 接口,也就是常说的百度文心大模型。此处简要介绍文心大模型接口的常用参数:
· messages,即调用的 prompt。文心的 messages 配置与 ChatGPT 有一定区别,其不支持 max_token 参数,由模型自行控制最大 token 数,messages 中的 content 总长度、functions 和 system 字段总内容不能超过 20480 个字符,且不能超过 5120 tokens,否则模型就会自行对前文依次遗忘。文心的 messages 有以下几点要求:① 一个成员为单轮对话,多个成员为多轮对话;② 最后一个 message 为当前对话,前面的 message 为历史对话;③ 成员数目必须为奇数,message 中的 role 必须依次是 user、assistant。注:这里介绍的是 ERNIE-Bot 模型的字符数和 tokens 限制,而参数限制因模型而异,请在文心千帆官网查看对应模型的参数说明。
· stream,是否使用流式传输。
· temperature,温度系数,默认 0.8,文心的 temperature 参数要求范围为 (0, 1.0],不能设置为 0。Prompt Engineering
1. Prompt Engineering 的意义
LLM 时代 prompt 这个词对于每个使用者和开发者来说已经听得滚瓜烂熟,那么到底什么是 prompt 呢?简单来说,prompt(提示)就是用户与大模型交互输入的代称。即我们给大模型的输入称为 Prompt,而大模型返回的输出一般称为 Completion。
对于具有较强自然语言理解、生成能力,能够实现多样化任务处理的大语言模型(LLM)来说,一个好的 Prompt 设计极大地决定了其能力的上限与下限。如何去使用 Prompt,以充分发挥 LLM 的性能?首先我们需要知道设计 Prompt 的原则,它们是每一个开发者设计 Prompt 所必须知道的基础概念。本节讨论了设计高效 Prompt 的两个关键原则:编写清晰、具体的指令和给予模型充足思考时间。掌握这两点,对创建可靠的语言模型交互尤为重要。
2. Prompt 设计的原则及使用技巧
2.1 原则一:编写清晰、具体的指令
首先,Prompt 需要清晰明确地表达需求,提供充足上下文,使语言模型能够准确理解我们的意图。并不是说 Prompt 就必须非常短小简洁,过于简略的 Prompt 往往使模型难以把握所要完成的具体任务,而更长、更复杂的 Prompt 能够提供更丰富的上下文和细节,让模型可以更准确地把握所需的操作和响应方式,给出更符合预期的回复。
所以,记住用清晰、详尽的语言表达 Prompt,“Adding more context helps the model understand you better.”。
从该原则出发,我们提供几个设计 Prompt 的技巧。
2.1.1 使用分隔符清晰地表示输入的不同部分
在编写 Prompt 时,我们可以使用各种标点符号作为“分隔符”,将不同的文本部分区分开来。分隔符就像是 Prompt 中的墙,将不同的指令、上下文、输入隔开,避免意外的混淆。你可以选择用 ```,""",< >, ,: 等做分隔符,只要能明确起到隔断作用即可。
在以下的例子中,我们给出一段话并要求 LLM 进行总结,在该示例中我们使用 ``` 来作为分隔符:
- 首先,让我们调用文心一言 的 API ,封装一个对话函数,使用 Yi-34B-Chat 这个模型。
注:如果你使用的是其他模型 API,请参考[第二节内容](https://datawhalechina.github.io/llm-universe/#/2. 使用 LLM API.ipynb)修改下文的 get_completion 函数。
import os
from openai import OpenAI
from dotenv import load_dotenv, find_dotenv
# 如果你设置的是全局的环境变量,这行代码则没有任何作用。
_ = load_dotenv(find_dotenv())
client = OpenAI(
# This is the default and can be omitted
# 获取环境变量 OPENAI_API_KEY
api_key=os.environ.get("OPENAI_API_KEY"),
)
# 如果你需要通过代理端口访问,还需要做如下配置
os.environ['HTTPS_PROXY'] = 'http://127.0.0.1:7890'
os.environ["HTTP_PROXY"] = 'http://127.0.0.1:7890'
# 一个封装 文心一言 接口的函数,参数为 Prompt,返回对应结果
def get_completion(prompt, model="Yi-34B-Chat", temperature=0.01):
'''
获取文心模型调用结果
请求参数:
prompt: 对应的提示词
model: 调用的模型,默认为 ERNIE-Bot,也可以按需选择 ERNIE-Bot-4 等其他模型
temperature: 模型输出的温度系数,控制输出的随机程度,取值范围是 0~1.0,且不能设置为 0。温度系数越低,输出内容越一致。
'''
chat_comp = qianfan.ChatCompletion()
message = gen_wenxin_messages(prompt)
resp = chat_comp.do(messages=message,
model=model,
temperature = temperature,
system="你是一名个人助理-小鲸鱼")
return resp["result"]
Comments NOTHING