背景
首先,随着AI领域的发展,大模型逐渐成为发展通用人工智能的重要途经
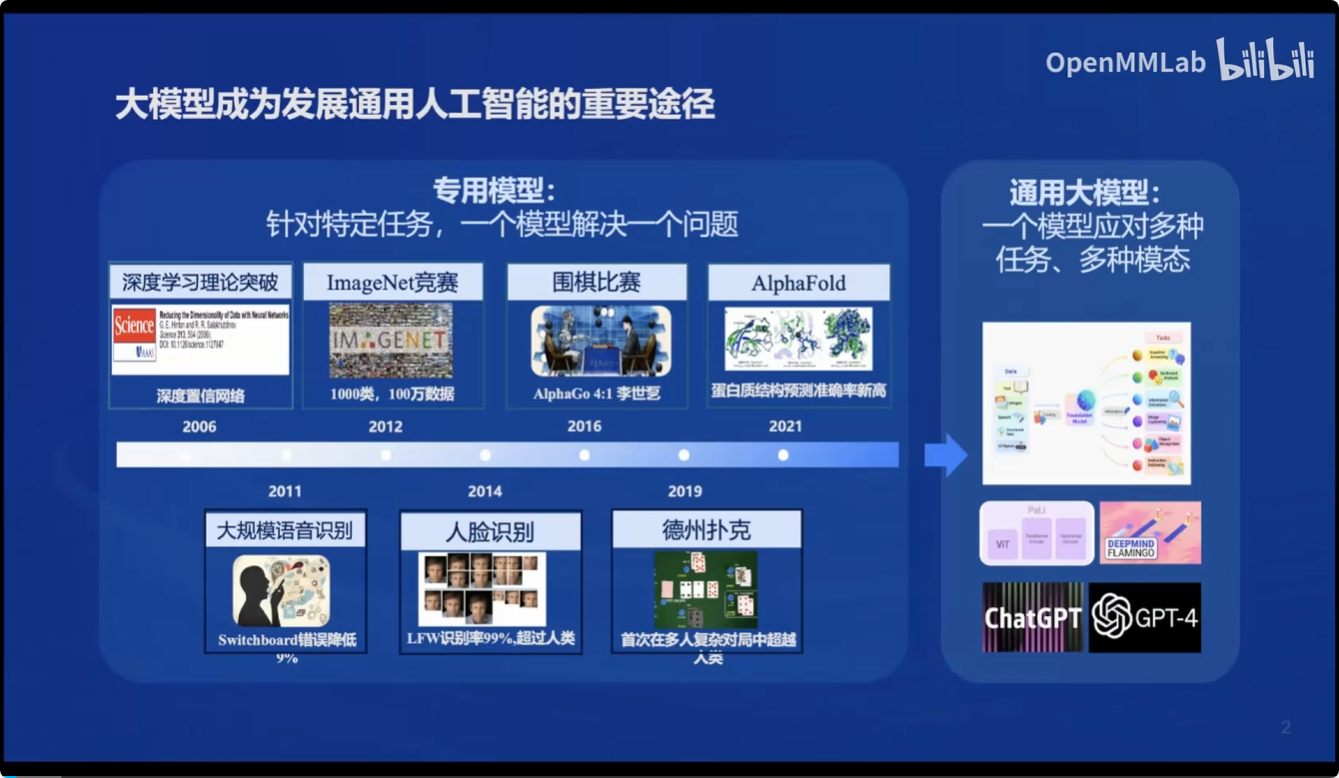
而书生·浦语大模型也从2023年开始逐步推动其大模型的开源
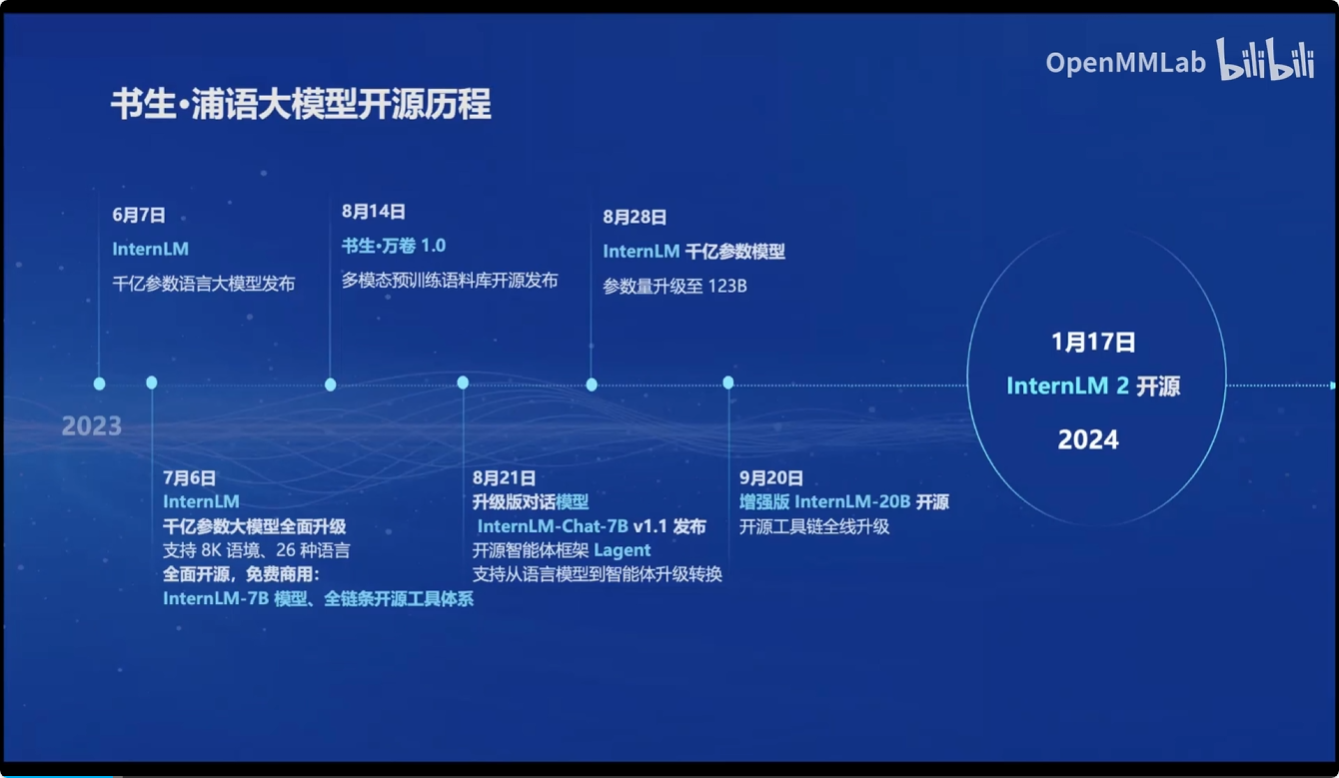
目前最新的书生·浦语2.0版本:
- InternLM2-Base
- InternLM2
- InternLM2-Chat

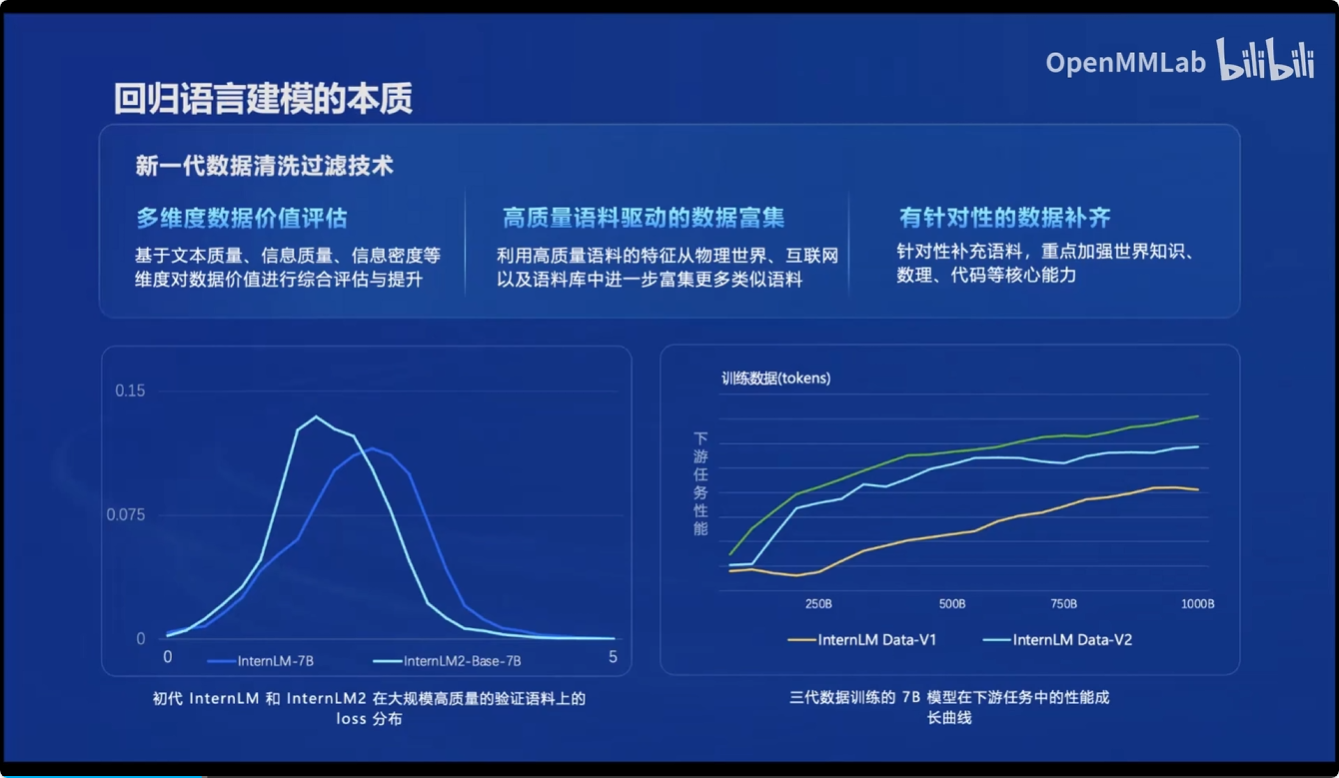
并且通过新一代的数据清洗过滤技术,使得InternLM2相比前一代的InternLM,在大规模高质量验证语料和下游任务中都得到了进一步提高
InternLM2主要有以下亮点:

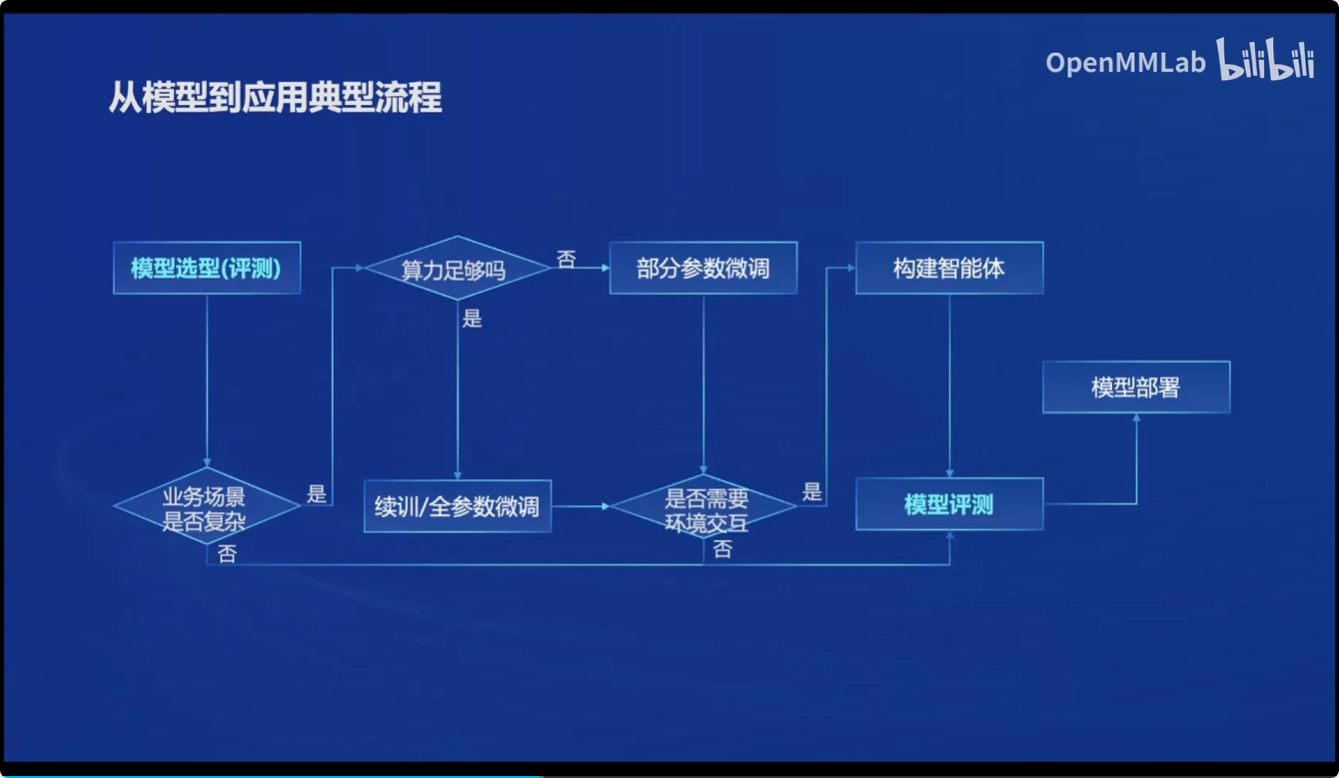
接下来,介绍了一个如何选型模型到应用的经典流程
全链路开源体系
书生·浦语也为此开发了一套从数据到应用的开源开放体系

数据方面:
提供了开放的高质量语料数据---书生万卷

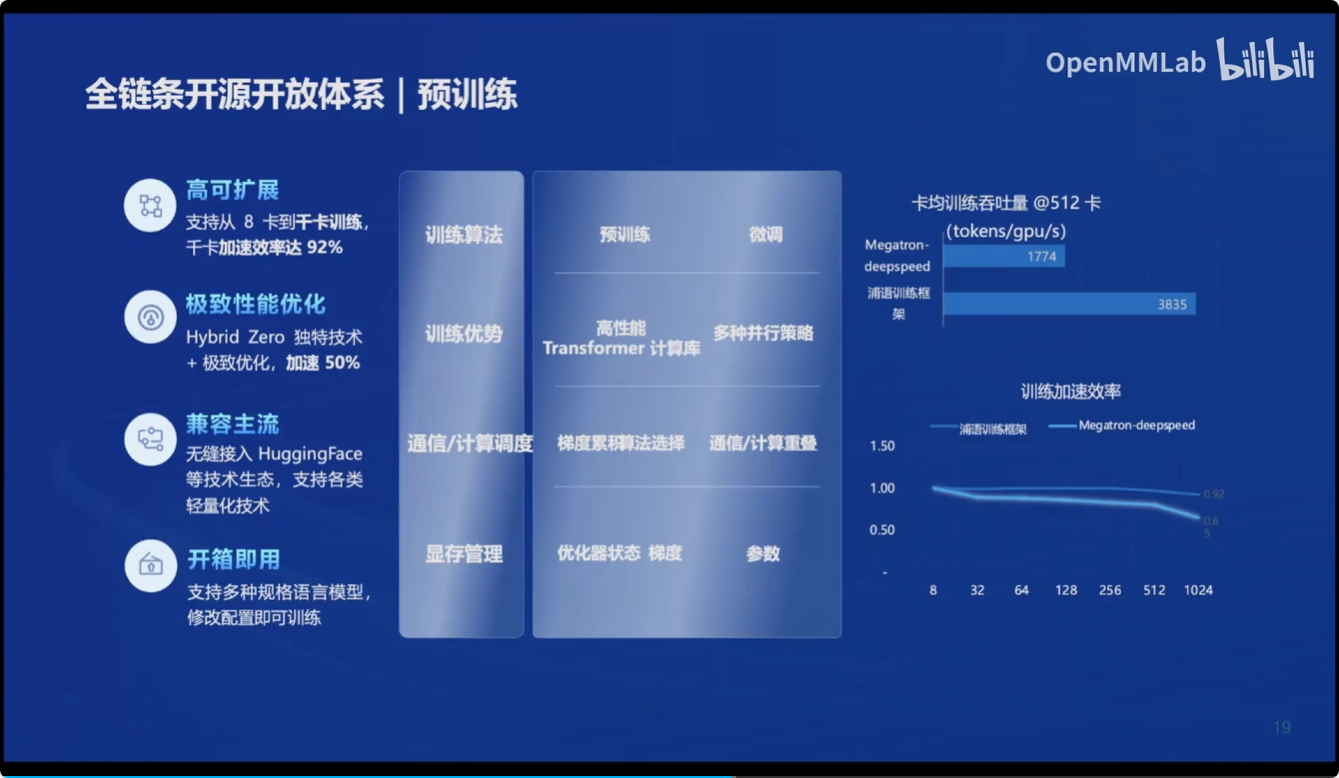
预训练:
提供了
- 高可扩展
- 性能优化
- 兼容主流模型
- 开箱即用
的预训练体系
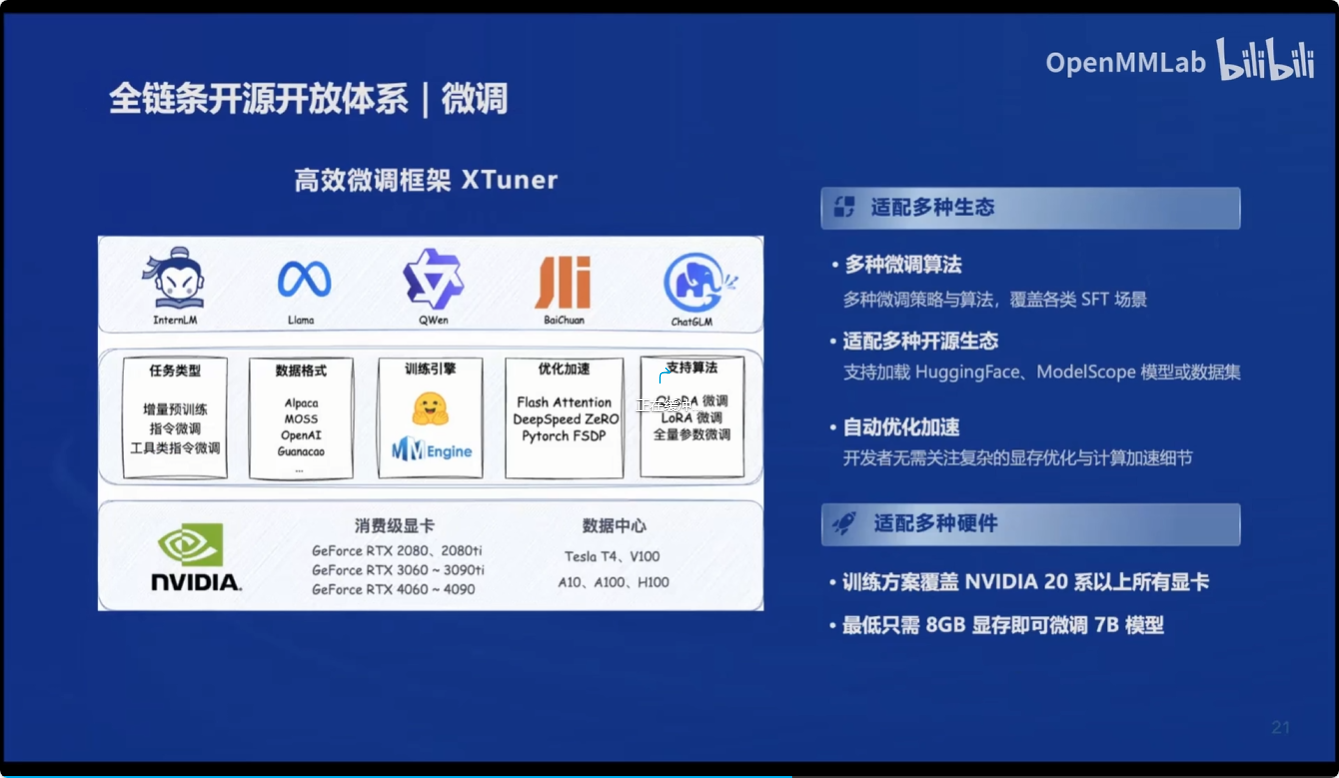
微调:
也提供了高效微调框架 XTuner

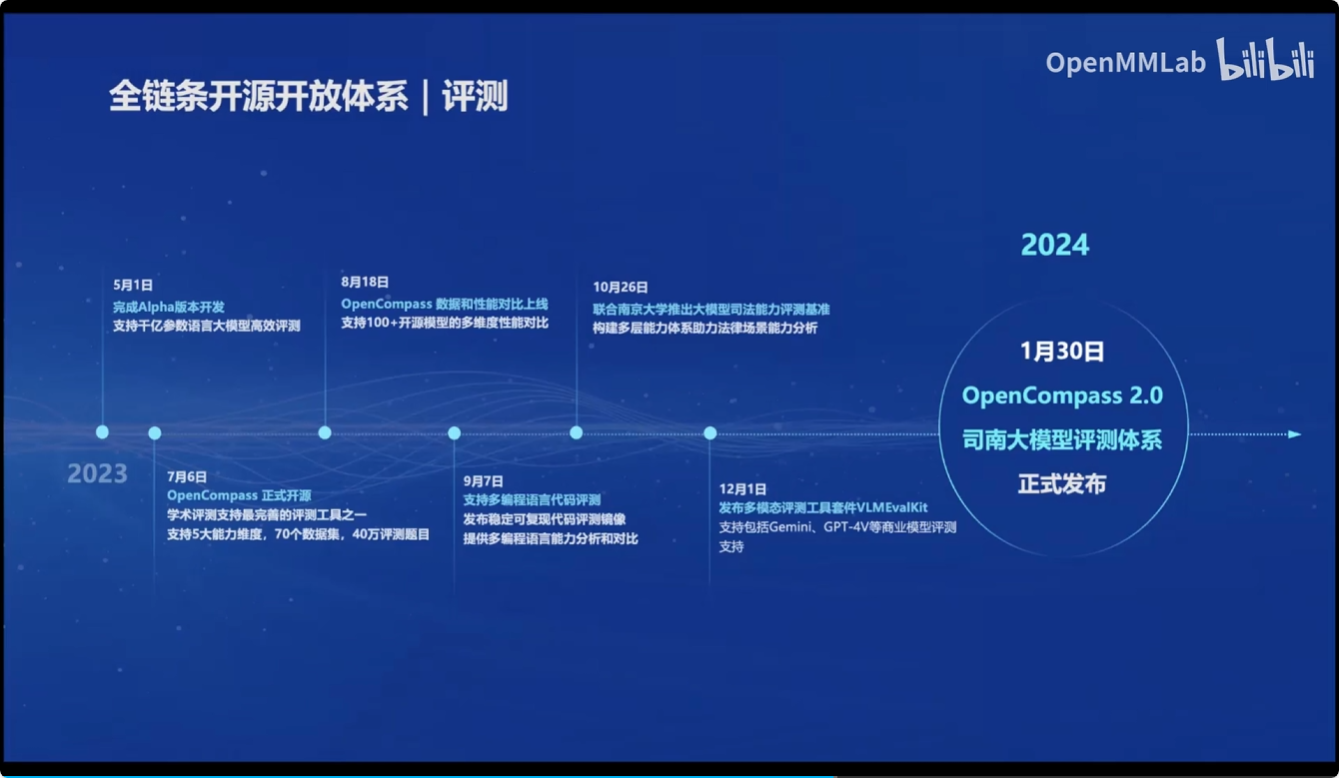
评测体系:
于2024年推出了最新的 OpenCompass 2.0司南大模型评测体系
其中包含
- CompassRank: 中立全面的性能榜单
- CompassKit: 大模型评测全栈工具链
- CompassHub :高质量评测基准社区
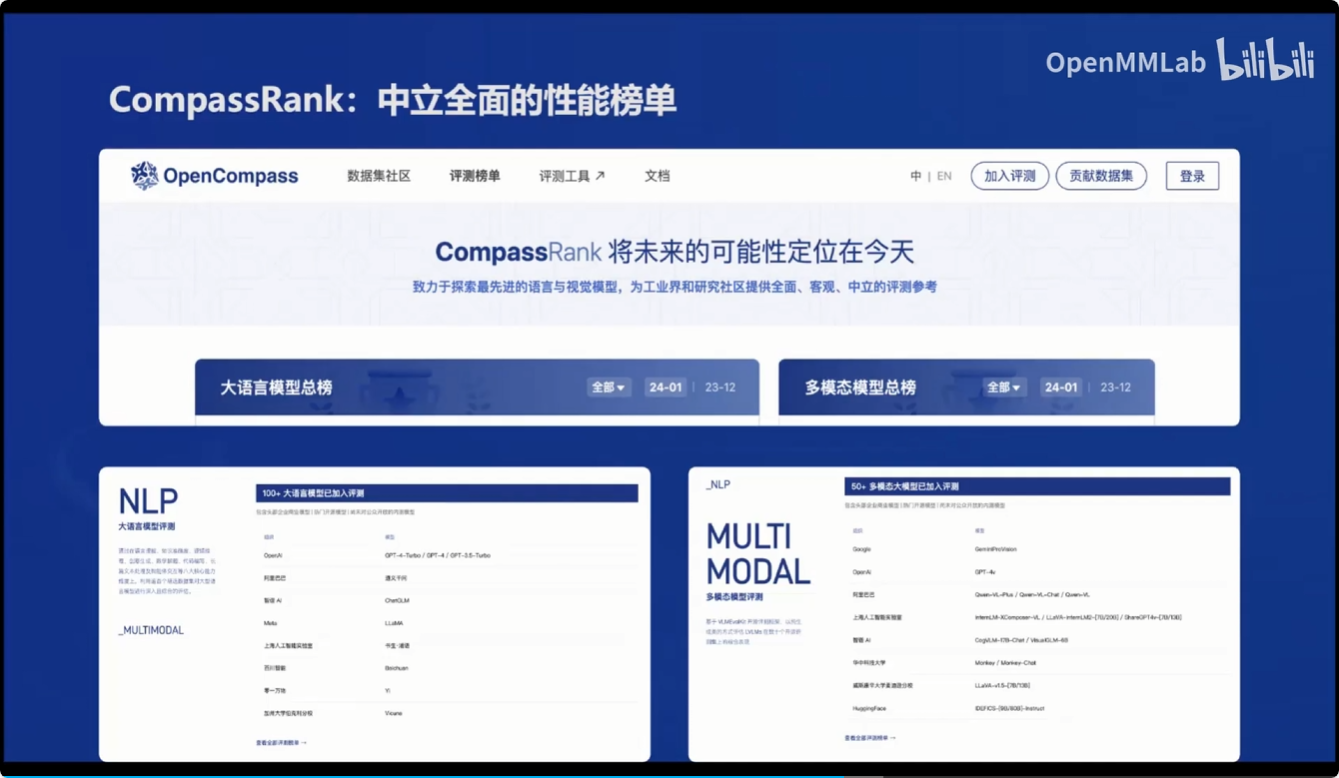

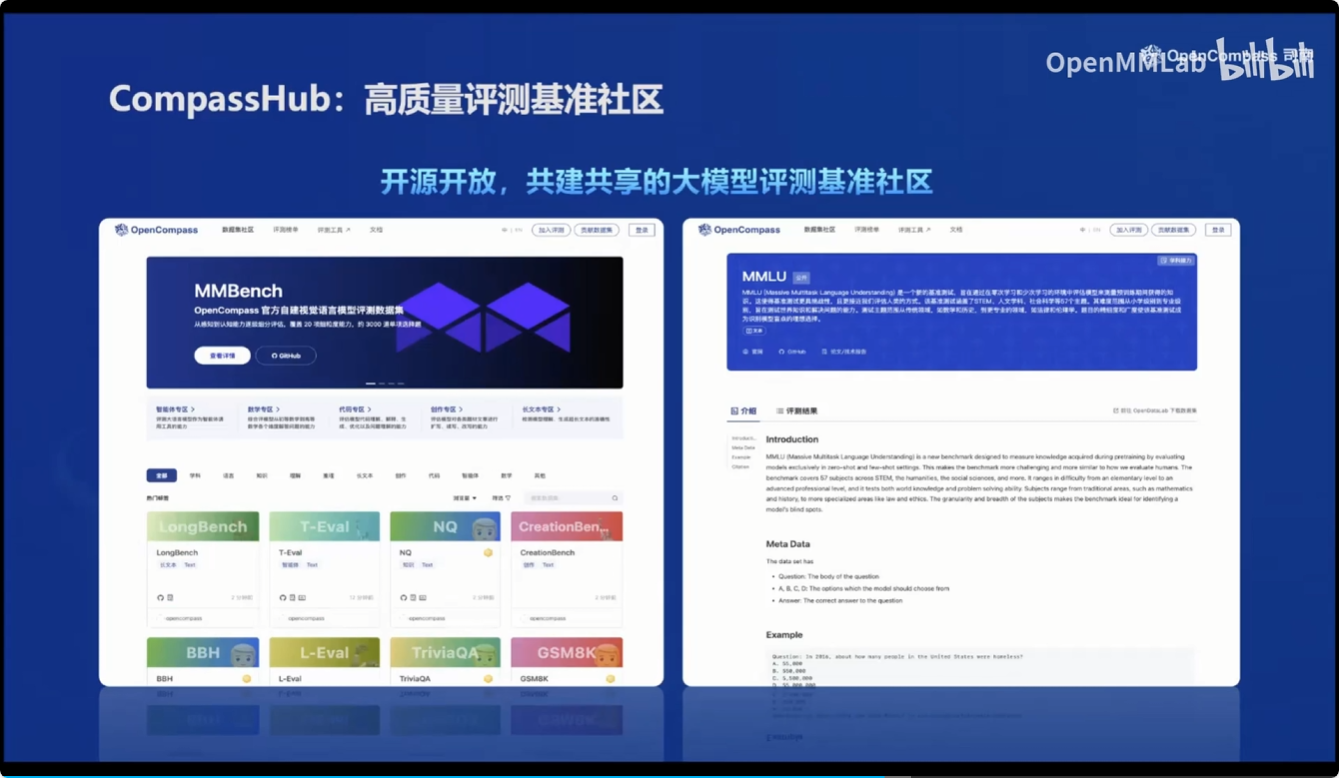

同时基于OpenCompass 2.0司南大模型评测体系,对市面上的大模型进行了性能评测
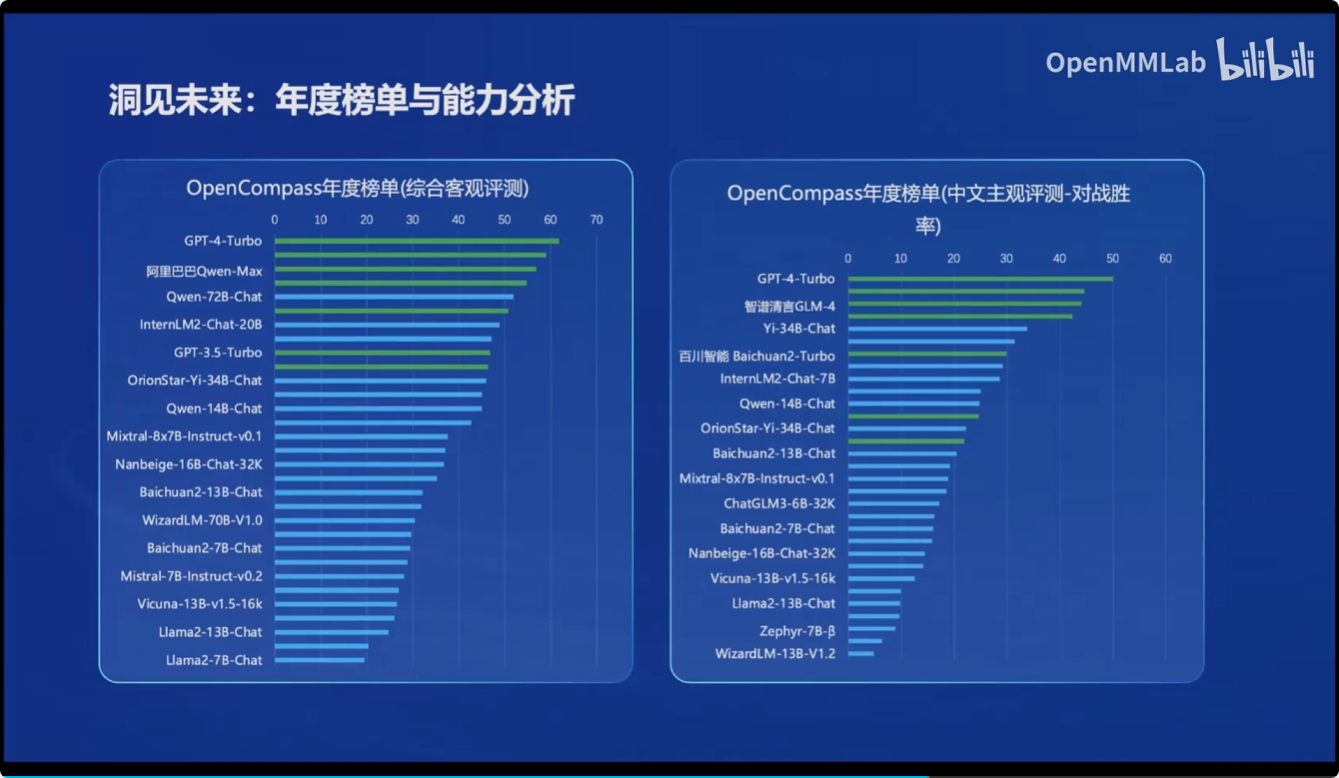
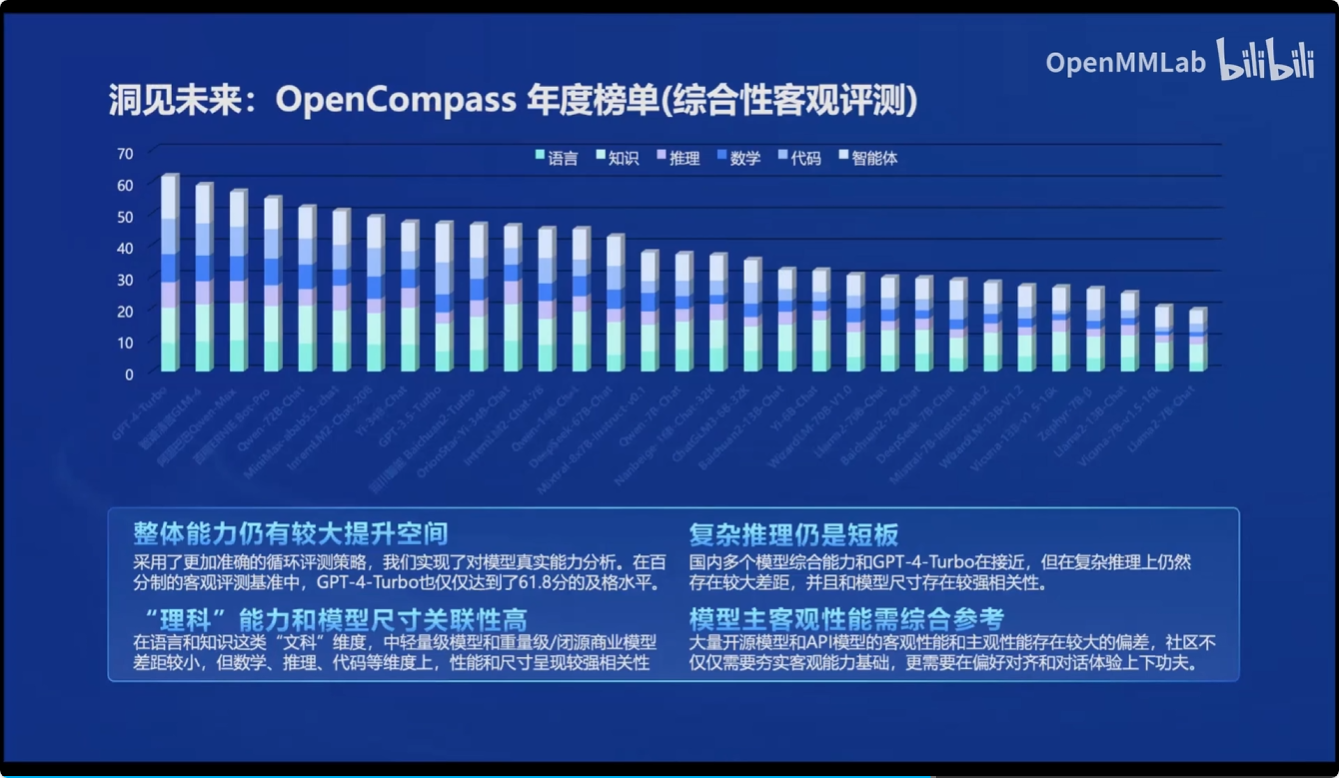
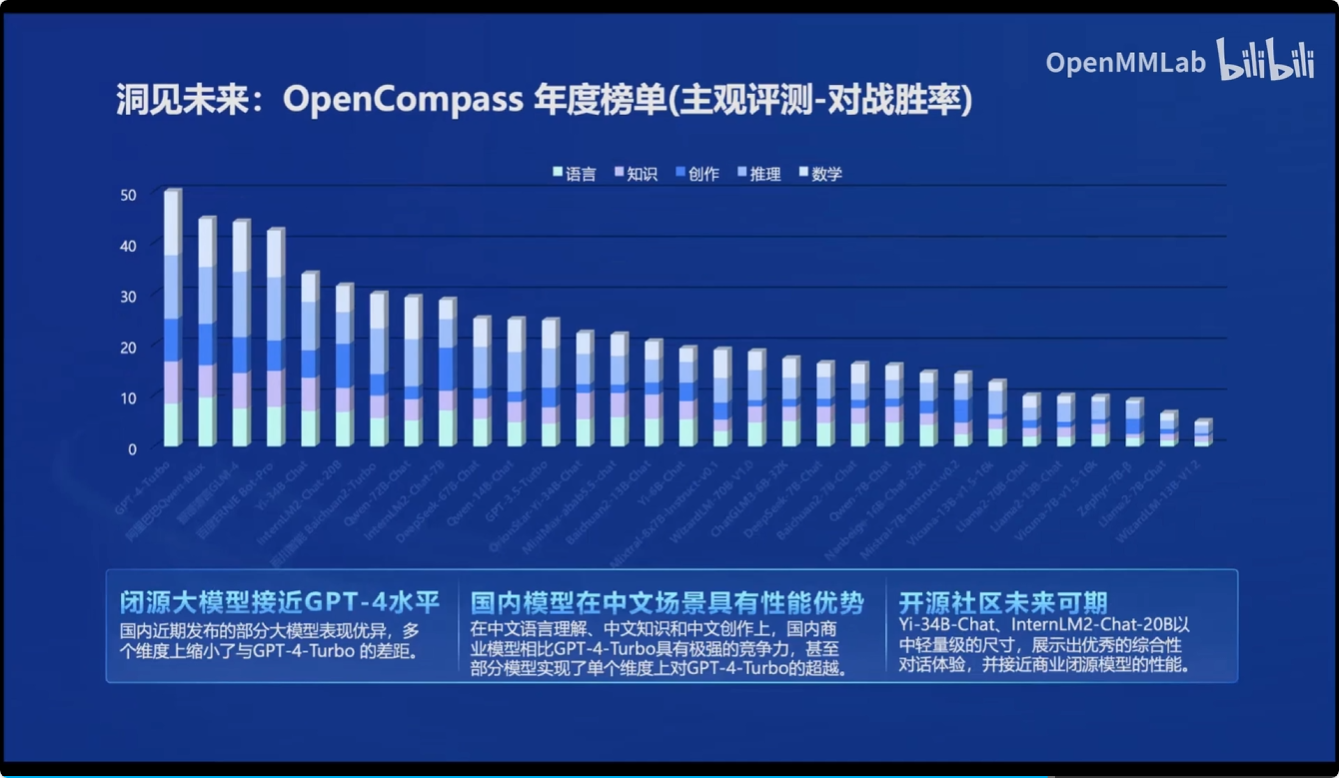
部署:
推出了LMDeploy ,提供大模型在GPU上部署的全流程解决方案,包括模型轻量化、推理和服务。

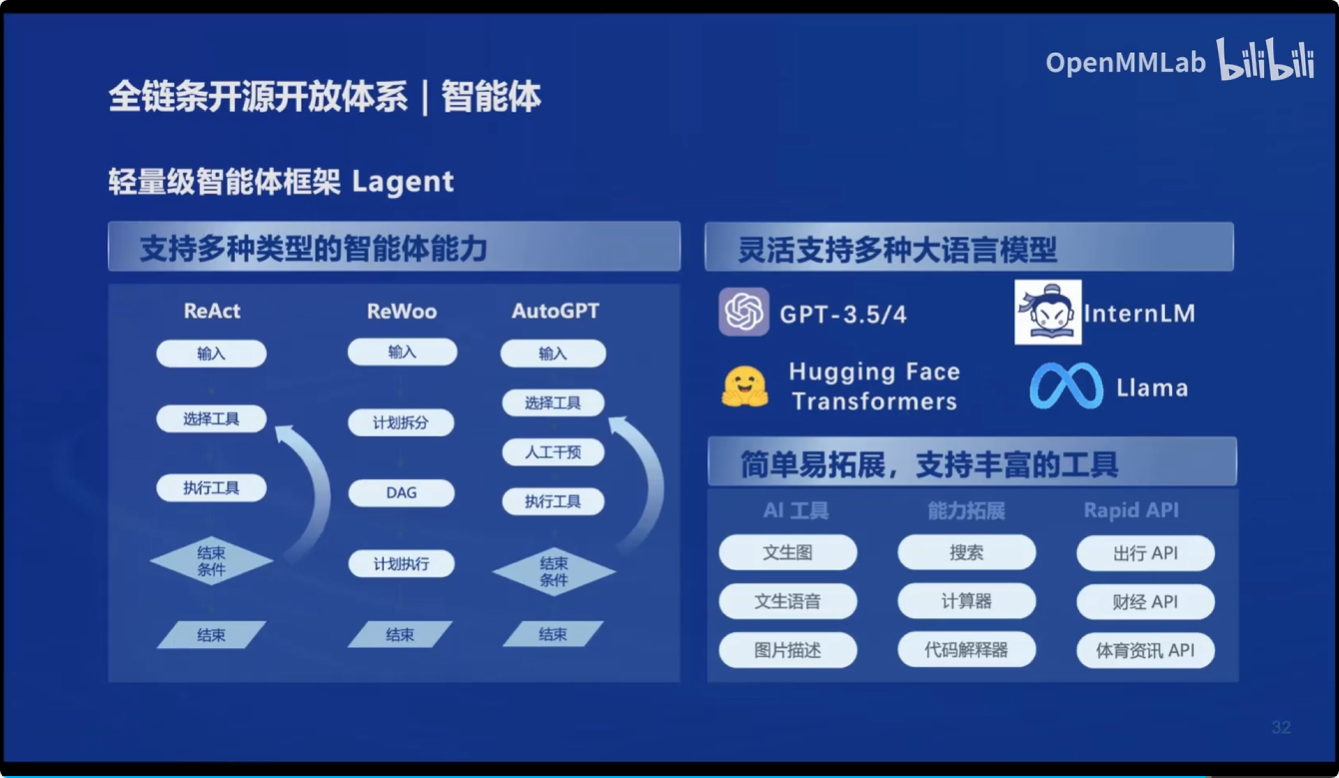
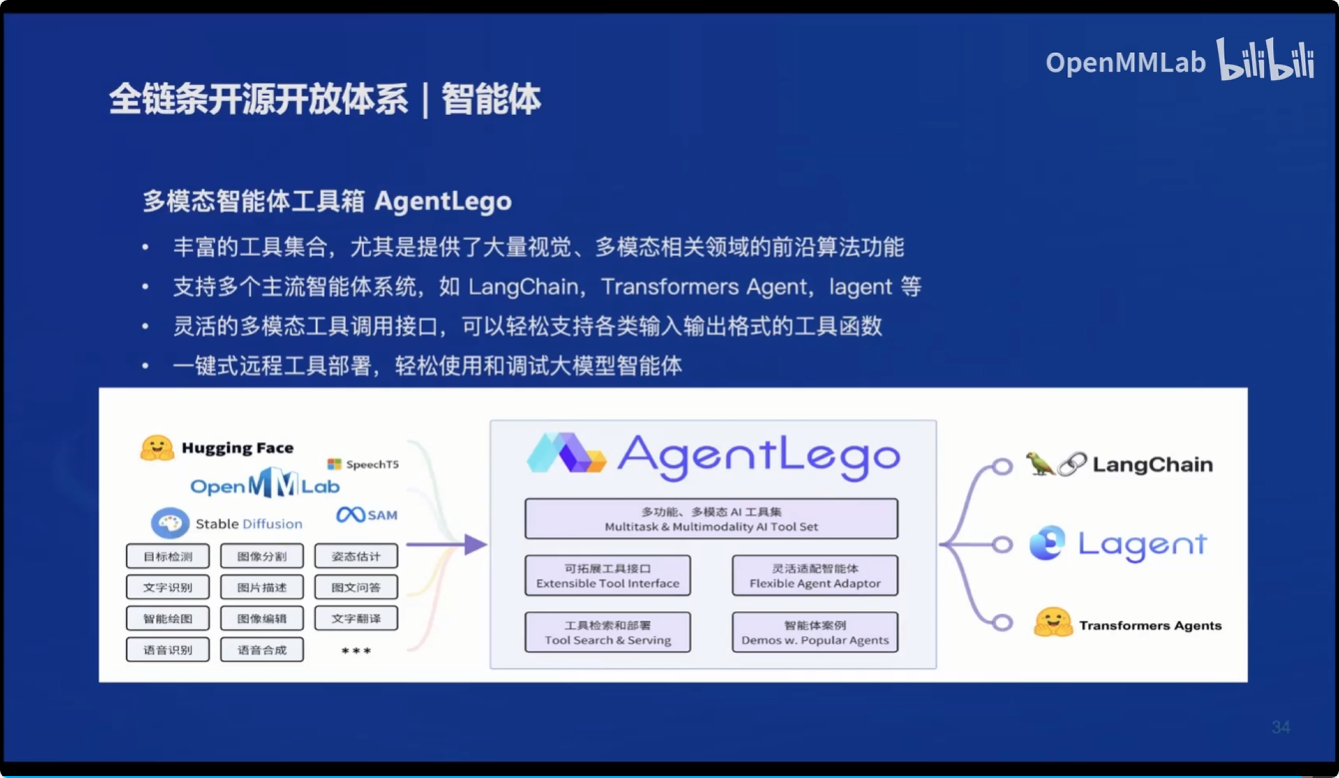
智能体:
- 轻量级智能体框架 Lagent
- 多模态智能体工具箱 AgentLego
InternLM2 技术报告笔记
InternLM2 技术报告(EN):下载链接
InternLM2 技术报告(机翻):下载链接
InternLM2的特点:
- 提供不同规模版本的模型
- 具有200k的token长度
- 全面的数据集
- 创新的RLHF技术
InternLM2基于InternEvo训练框架进行训练,InternLM2使用InternEvo训练框架能在上百张显卡训练中,可以达到惊人的53%MFU以上
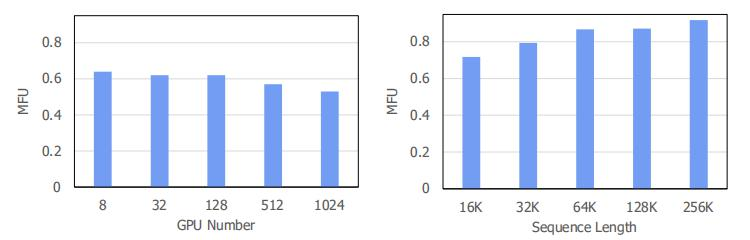
说明InternEvo在多张显卡协同训练时,能够
- 减少通信开销
- 优化协调通信与计算
- 针对长序列训练,自动搜索最优执行计划,以及使用内存管理技术来减少GPU内存碎片
- 通过诊断大模型相关的故障并自动恢复来提高容错性;以及一个为评估任务设计的解耦调度系统,提供及时的模型性能反馈。
Comments NOTHING