本系列笔记是学习 黑马程序员大数据入门到实战教程,大数据开发必会的Hadoop、Hive,云平台实战 过程中自己总结和记录的笔记,分享出来方便大家学习
数据库操作
1.创建库的语法为
CREATE DATABASE [IF NOT EXISTS] db_name [LOCATION position];2.删除库的语法为
DROP DATABASE db_name [CASCADE];3.数据库和HDFS的关系
Hive的库在HDFS上就是一个以.db结尾的目录
默认存储在:/user/hive/warehouse内
可以通过LOCATION关键字在创建的时候指定存储目录
数据表操作
内部表操作
内部表和外部表
内部表(CREATE TABLE table_name ……)
未被external关键字修饰的即是内部表, 即普通表。 内部表又称管理表,内部表数据存储的位置由hive.metastore.warehouse.dir参数决定(默认:/user/hive/warehouse),删除内部表会直接删除元数据(metadata)及存储数据,因此内部表不适合和其他工具共享数据。
外部表(CREATE EXTERNAL TABLE table_name ……LOCATION……)
被external关键字修饰的即是外部表, 即关联表。
外部表是指表数据可以在任何位置,通过LOCATION关键字指定。 数据存储的不同也代表了这个表在理念是并不是Hive内部管理的,而是可以随意临时链接到外部数据上的。
所以,在删除外部表的时候, 仅仅是删除元数据(表的信息),不会删除数据本身。
| 创建 | 存储位置 | 删除数据 | 理念 | |
|---|---|---|---|---|
| 内部表 | CREATE TABLE …… | Hive管理,默认/user/hive/warehouse | 删除 元数据(表信息)删除 数据 | Hive管理表持久使用 |
| 外部表 | CREATE EXTERNAL TABLE …… | 随意,LOCATION关键字指定 | 仅删除 元数据(表信息)保留 数据 | 临时链接外部数据用 |
创建内部表
内部表的创建语法就是标准的:
CREATE TABLE table_name......创建一个基础的表
create database if not exists myhive;
use myhive;
create table if not exists stu(id int,name string);
insert into stu values (1,"zhangsan"), (2, "wangwu");
select * from stu;查看表的数据存储
在HDFS上,查看表的数据存储文件
[hadoop@node1 etc]$ hdfs dfs -ls /user/hive/warehouse/myhive.db/stu
Found 1 items
-rw-r--r-- 3 hadoop supergroup 20 2024-03-01 18:06 /user/hive/warehouse/myhive.db/stu/000000_0
[hadoop@node1 etc]$ hdfs dfs -ls /user/hive/warehouse/myhive.db/stu/*
-rw-r--r-- 3 hadoop supergroup 20 2024-03-01 18:06 /user/hive/warehouse/myhive.db/stu/000000_0
[hadoop@node1 etc]$ 数据分隔符
可以看到,数据在HDFS上也是以明文文件存在的。
[hadoop@node1 etc]$ hdfs dfs -cat /user/hive/warehouse/myhive.db/stu/*
1zhangsan
2wangwu
[hadoop@node1 etc]$奇怪的是, 列ID和列NAME,好像没有分隔符,而是挤在一起的。
这是因为,默认的数据分隔符是:”\001”是一种特殊字符,是ASCII值,键盘是打不出来
在某些文本编辑器中是显示为SOH的。
自行指定分隔符
当然,分隔符我们是可以自行指定的。
在创建表的时候可以自己决定:
create table if not exists stu2(id int ,name string) row format delimited fields terminated by '\t';- row format delimited fields terminated by '\t':表示以\t分隔
其它创建内部表的形式
除了标准的CREATE TABLE table_name的形式创建内部表外
我们还可以通过:
CREATE TABLE table_name as,基于查询结果建表
create table stu3 as select * from stu2;CREATE TABLE table_name like,基于已存在的表结构建表
create table stu4 like stu2;也可以使用DESC FORMATTED table_name,查看表类型和详情
DESC FORMATTED stu2;删除内部表
我们是内部表删除后,数据本身也不会保留,让我们试一试吧。
DROP TABLE table_name,删除表
drop table stu2;可以看到,stu2文件夹已经不存在了,数据被删除了。
[hadoop@node1 etc]$ hdfs dfs -ls /user/hive/warehouse/myhive.db
Found 3 items
drwxr-xr-x - hadoop supergroup 0 2024-03-01 18:06 /user/hive/warehouse/myhive.db/stu
drwxr-xr-x - hadoop supergroup 0 2024-03-01 18:38 /user/hive/warehouse/myhive.db/stu3
drwxr-xr-x - hadoop supergroup 0 2024-03-01 18:43 /user/hive/warehouse/myhive.db/stu4
[hadoop@node1 etc]$外部表操作
外部表的创建
| 创建 | 存储位置 | 删除数据 | 理念 | |
|---|---|---|---|---|
| 内部表 | CREATE TABLE …… | Hive管理,默认/user/hive/warehouse | 删除 元数据(表信息)删除 数据 | Hive管理表持久使用 |
| 外部表 | CREATE EXTERNAL TABLE …… | 随意,LOCATION关键字指定 | 仅删除 元数据(表信息)保留 数据 | 临时链接外部数据用 |
外部表,创建表被EXTERNAL关键字修饰,从概念是被认为并非Hive拥有的表,只是临时关联数据去使用。
创建外部表也很简单,基于外部表的特性,可以总结出: 外部表 和 数据 是相互独立的, 即:
- 可以先有表,然后把数据移动到表指定的LOCATION中
- 也可以先有数据,然后创建表通过LOCATION指向数据
1.在Linux上创建新文件
test_external.txt,并填入如下内容:
1 itheima
2 itcast
3 hadoop数据列用’\t’分隔
2.演示先创建外部表,然后移动数据到LOCATION目录
- 首先检查:
hadoop fs -ls /tmp确认不存在/tmp/test_ext1目录

- 创建外部表:
create external table test_ext1(
id int,
name string) row format delimited fields terminated by '\t' location '/ tmp / test_ext1';可以看到,目录/tmp/test_ext1被创建

- 查看
select * from test_ext1空结果,无数据
- 上传数据
hadoop fs -put test_external.txt /tmp/test_ext1/ - 即可看到数据结果:
select * from test_ext1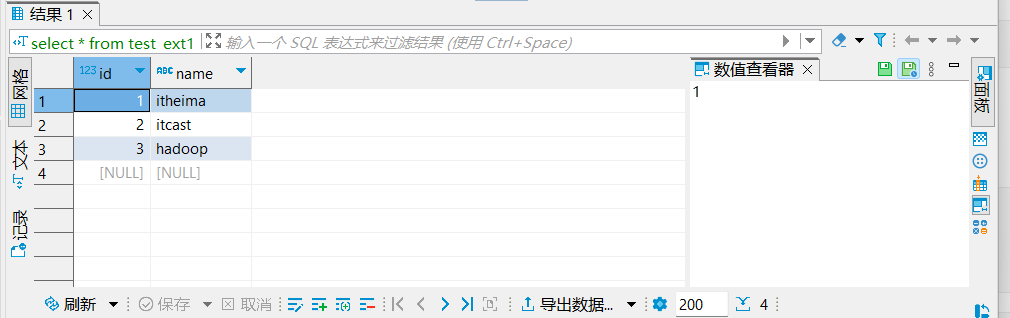
3.演示先存在数据,后创建外部表
hadoop fs -mkdir /tmp/test_ext2
hadoop fs -put test_external.txt /tmp/test_ext2/create external table test_ext2(id int, name string)
row format delimited fields terminated by ‘\t’ location ‘/tmp/test_ext2’;
select * from test_ext2;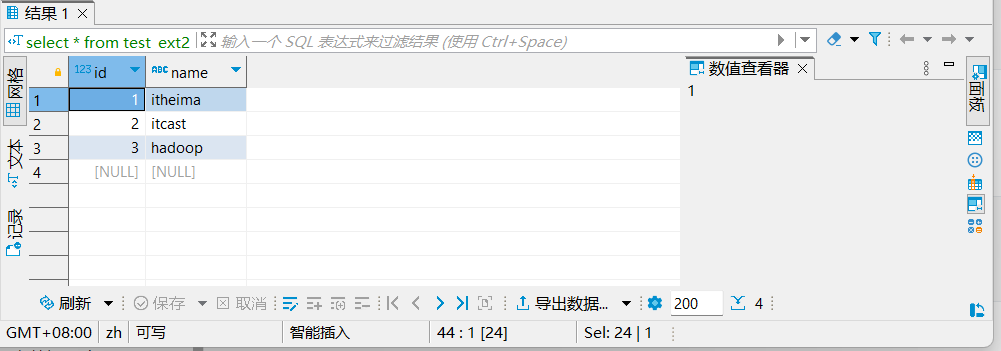
删除外部表
drop table test_ext1;
drop table test_ext2;可以发现,在Hive中通过show table,表不存在了
但是在HDFS中,数据文件依旧保留
内外部表转换
Hive可以很简单的通过SQL语句转换内外部表。
查看表类型:
desc formatted stu;转换
内部表转外部表
alter table stu set tblproperties('EXTERNAL'='TRUE');外部表转内部表
alter table stu set tblproperties('EXTERNAL'='FALSE');通过stu set tblproperties来修改属性
要注意:('EXTERNAL'='FALSE') 或 ('EXTERNAL'='TRUE')为固定写法,区分大小写!!!
数据加载和导出
数据加载 - LOAD语法
我们使用 LOAD 语法,从外部将数据加载到Hive内,语法如下:
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename;LOAD DATA :加载数据
[LOCAL]:数据是否在本地
- 使用local,数据不在HDFS,需使用file://协议指定路径
- 不使用local,数据在HDFS,可以使用HDFS://协议指定路径
INPATH 'filepath':数据路径
[OVERWRITE]:覆盖已存在数据
- 使用OVERWRITE进行覆盖
- 不使用OVERWRITE则不覆盖
INTO TABLE tablename:被加载的内部表(tablename)
建表:
CREATE TABLE myhive.test_load(
dt string comment '时间(时分秒)',
user_id string comment '用户ID',
word string comment '搜索词',
url string comment '用户访问网址'
) comment '搜索引擎日志表' ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';导入数据:
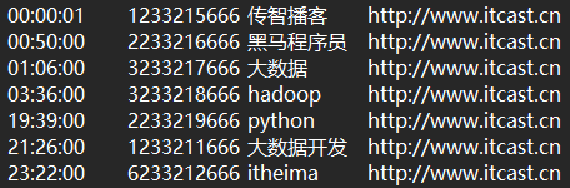
注意,基于HDFS进行load加载数据,源数据文件会消失(本质是被移动到表所在的目录中)!!!
#本地文件导入方法
load data local inpath '/home/hadoop/search_log.txt' into table myhive.test_load;
#HDFS文件导入方法
#注意,基于HDFS进行load加载数据,源数据文件会消失(本质是被移动到表所在的目录中)!!!
load data inpath '/tmp/search_log.txt' overwrite into table myhive.test_load;注意,基于HDFS进行load加载数据,源数据文件会消失(本质是被移动到表所在的目录中)!!!
SQL语句,从其它表中加载数据
除了load加载外部数据外,我们也可以通过SQL语句,从其它表中加载数据。
语法:
INSERT [OVERWRITE | INTO] TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...) [IF NOT EXISTS]] select_statement1 FROM from_statement;
将SELECT查询语句的结果插入到其它表中,被SELECT查询的表可以是内部表或外部表。
示例:
INSERT INTO TABLE tbl1 SELECT * FROM tbl2;
INSERT OVERWRITE TABLE tbl1 SELECT * FROM tbl2;
数据加载 - 两种语法的选择
对于数据加载,我们学习了:LOAD和INSERT SELECT的方式,那么如何选择它们使用呢?
数据在本地
- 推荐 load data local加载
数据在HDFS
- 如果不保留原始文件: 推荐使用LOAD方式直接加载
- 如果保留原始文件: 推荐使用外部表先关联数据,然后通过INSERT SELECT 外部表的形式加载数据
数据已经在表中
- 只可以INSERT SELECT
hive表数据导出 - insert overwrite 方式
将hive表中的数据导出到其他任意目录,例如linux本地磁盘,例如hdfs,例如mysql等等
语法:insert overwrite [local] directory ‘path’ select_statement1 FROM from_statement;
将查询的结果导出到本地 - 使用默认列分隔符
insert overwrite local directory '/home/hadoop/export1' select * from test_load ;将查询的结果导出到本地 - 指定列分隔符
insert overwrite local directory '/home/hadoop/export2' row format delimited fields terminated by '\t' select * from test_load;将查询的结果导出到HDFS上(不带local关键字)
insert overwrite directory '/tmp/export' row format delimited fields terminated by '\t' select * from test_load;hive表数据导出 - hive shell
基本语法:(hive -f/-e 执行语句或者脚本 > file)
bin/hive -e "select * from myhive.test_load;" > /home/hadoop/export3/export4.txt
bin/hive -f export.sql > /home/hadoop/export4/export4.txt分区表
在大数据中,最常用的一种思想就是分治,我们可以把大的文件切割划分成一个个的小的文件,这样每次操作一个小的文件就会很容易了
同样的道理,在hive当中也是支持这种思想的,就是我们可以把大的数据,按照每天,或者每小时进行切分成一个个的小的文件,这样去操作小的文件就会容易得多了
单分区表
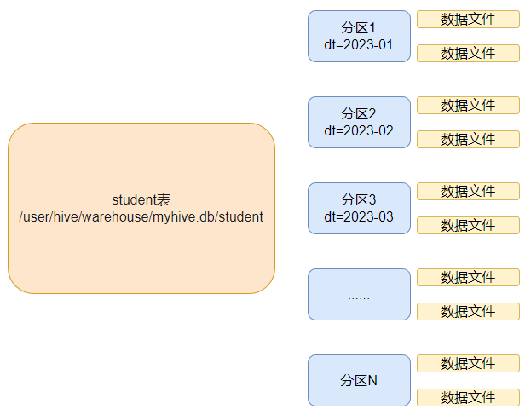
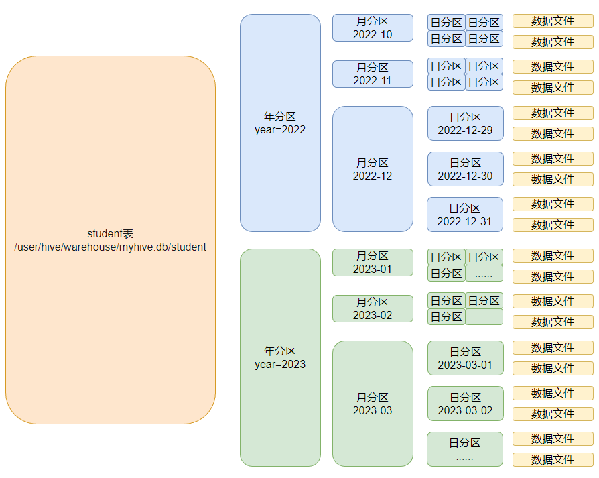
多分区表(三级分区
创建表时使用
#基本语法:
create table tablename(...) partitioned by (分区列 列类型, ......)
row format delimited fields terminated by '';
#查看分区
show partitions score;
#添加一个分区
alter table score add partition(month='202005');
#同时添加多个分区
alter table score add partition(month='202005')partition(month='202006');
#删除分区
alter table score drop partition(month='202005');创建带有分区功能的表(在hdfs 中实际存储为带有分区的文件夹目录)
创建单分区表
示例如下:
#创建一个单分区表,分区是按照月分区partitioned by (month string)
create table myhive.score(id string ,cid string ,score int )partitioned by (month string)
row format delimited fields TERMINATED BY '\t';
#使用load data 加载数据到分区表中
load data local inpath '/home/hadoop/score.txt' into table myhive.score
partition (month='202005');
load data local inpath '/home/hadoop/score.txt' into table myhive.score
partition (month='202006');
SELECT * from score ;查看HDFS中如何存储
hdfs dfs -ls /user/hive/warehouse/myhive.db/score
hdfs dfs -cat /user/hive/warehouse/myhive.db/score/month=202005/score.txt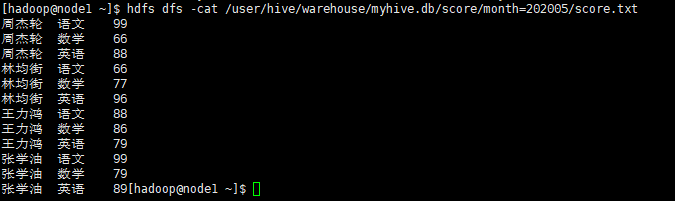
创建多分区表
#创建一个多分区表,分区层次:年,月,日
create table myhive.score2(id string ,cid string ,score int )partitioned by (year string,month string,day string)
row format delimited fields TERMINATED BY '\t';
#查看列
SELECT * from score2 ;
#使用load data 加载数据到分区表中
load data local inpath '/home/hadoop/score.txt' into table myhive.score2
partition (year='2020',month='01',day='10');
SELECT * from score2 ;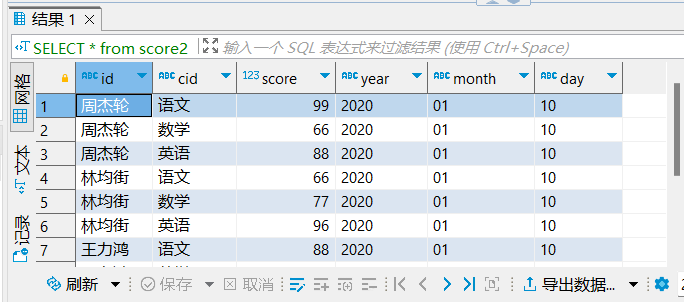
[hadoop@node1 ~]$ hdfs dfs -ls /user/hive/warehouse/myhive.db/score2
Found 1 items
drwxr-xr-x - hadoop supergroup 0 2024-03-02 14:10 /user/hive/warehouse/myhive.db/score2/year=2020
[hadoop@node1 ~]$ hdfs dfs -cat /user/hive/warehouse/myhive.db/score2/year=2020/month=01/day=10/score.txt
周杰轮 语文 99
周杰轮 数学 66
周杰轮 英语 88
林均街 语文 66
林均街 数学 77
林均街 英语 96
王力鸿 语文 88
王力鸿 数学 86
王力鸿 英语 79
张学油 语文 99
张学油 数学 79
张学油 英语 89分桶表操作
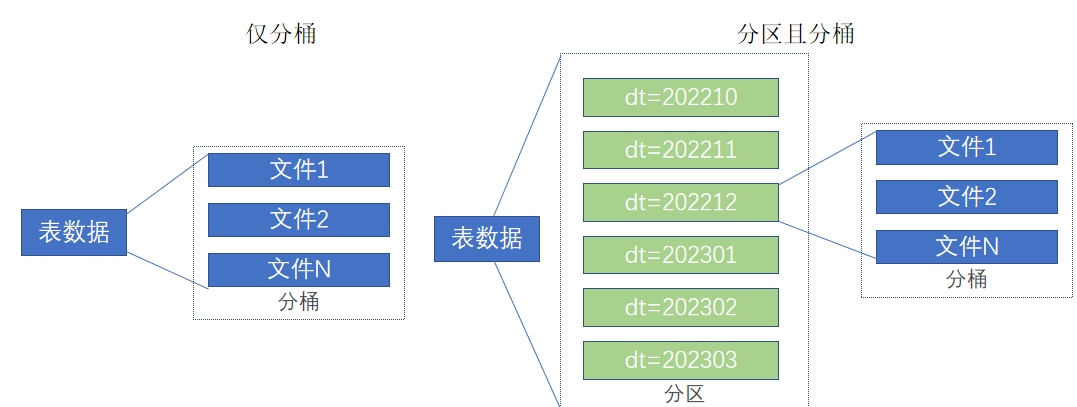
分桶和分区一样,也是一种通过改变表的存储模式,从而完成对表优化的一种调优方式
但和分区不同,分区是将表拆分到不同的子文件夹中进行存储,而分桶是将表拆分到固定数量的不同文件中进行存储。
分桶表创建
开启分桶的自动优化(自动匹配reduce task数量和桶数量一致)
set hive.enforce.bucketing=true;创建分桶表
clustered by(c_id)设置根据哪一个列进行计算分桶
create table course (c_id string,c_name string,t_id string)
clustered by(c_id) into 3 buckets row format delimited fields terminated by '\t';分桶表数据加载
桶表的数据加载,由于桶表的数据加载通过load data无法执行,只能通过insert select.
所以,比较好的方式是
- 创建一个临时表(外部表或内部表均可),通过load data加载数据进入表
- 然后通过insert select 从临时表向桶表插入数据
#创建普通表
CREATE TABLE course_temp(
c_id string,
c_name string ,
t_id string
)ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
#普通表导入数据
load data local inpath '/home/hadoop/course.txt' into table course_temp;
#通过insert select 从临时表向桶表插入数据
#参数cluster by(c_id)设置根据哪一个列进行分桶
insert overwrite table course select * from course_temp cluster by(c_id);查看分桶后的文件夹
[hadoop@node1 ~]$ hdfs dfs -ls /user/hive/warehouse/myhive.db/course
Found 3 items
-rw-r--r-- 3 hadoop supergroup 38 2024-03-02 14:57 /user/hive/warehouse/myhive.db/course/000000_0
-rw-r--r-- 3 hadoop supergroup 57 2024-03-02 14:57 /user/hive/warehouse/myhive.db/course/000001_0
-rw-r--r-- 3 hadoop supergroup 38 2024-03-02 14:57 /user/hive/warehouse/myhive.db/course/000002_0为什么不可以用load data,必须用insert select插入数据
如果没有分桶设置,插入(加载)数据只是简单的将数据放入到:
- 表的数据存储文件夹中(没有分区)
- 表指定分区的文件夹中(带有分区)
一旦有了分桶设置,比如分桶数量为3,那么,表内文件或分区内数据文件的数量就限定为3
当数据插入的时候,需要一分为3,进入三个桶文件内

问题就在于:如何将数据分成三份,划分的规则是什么?
数据的三份划分基于分桶列的值进行hash取模来决定
由于load data不会触发MapReduce,也就是没有计算过程(无法执行Hash算法),只是简单的移动数据而已所以无法用于分桶表数据插入。
修改表操作
- 表重命名
alter table old_table_name rename to new_table_name;如:alter table score4 rename to score5;
- 修改表属性值
ALTER TABLE table_name SET TBLPROPERTIES table_properties;
table_properties:(property_name = property_value, property_name = property_value, ... )如:ALTER TABLE table_name SET TBLPROPERTIES("EXTERNAL"="TRUE"); 修改内外部表属性
如:ALTER TABLE table_name SET TBLPROPERTIES ('comment' = new_comment); 修改表注释
- 添加分区
ALTER TABLE tablename ADD PARTITION (month='201101');新分区是空的没数据,需要手动添加或上传数据文件
- 修改分区值
ALTER TABLE tablename PARTITION (month='202005') RENAME TO PARTITION (month='201105');- 删除分区
ALTER TABLE tablename DROP PARTITION (month='201105');- 添加列
ALTER TABLE table_name ADD COLUMNS (v1 int, v2 string);- 修改列名
ALTER TABLE test_change CHANGE v1 v1new INT;- 删除表
DROP TABLE tablename;- 清空表
TRUNCATE TABLE tablename;ps:只可以清空内部表
复杂类型操作
Hive支持的数据类型很多,除了基本的:int、string、varchar、timestamp等还有一些复杂的数据类型:
- array
数组类型
- map
映射类型
- struct
结构类型
array类型
如下数据文件,有2个列,locations列包含多个城市:
说明:name与locations之间制表符分隔,locations中元素之间逗号分隔
name | locations
-------------------------------------------------
zhangsan | beijing,shanghai,tianjin,hangzhou
wangwu | changchun,chengdu,wuhan,beijin可以使用array数组类型,存储locations的数据
建表语句:
create table myhive.test_array(name string, work_locations array<string>)
row format delimited fields terminated by '\t'
COLLECTION ITEMS TERMINATED BY ',';- row format delimited fields terminated by '\t' 表示列分隔符是\t
- COLLECTION ITEMS TERMINATED BY ',' 表示集合(array)元素的分隔符是逗号

示例:
--导入数据
load data local inpath '/home/hadoop/data_for_array_type.txt' overwrite into table myhive.test_array;
--常用array类型查询:
-- 查询所有数据
select * from myhive.test_array;
-- 查询loction数组中第一个元素
select name, work_locations[0] location from myhive.test_array;
-- 查询location数组中元素的个数
select name, size(work_locations) location from myhive.test_array;
-- 查询location数组中包含tianjin的信息
select * from myhive.test_array where array_contains(work_locations,'tianjin');map类型
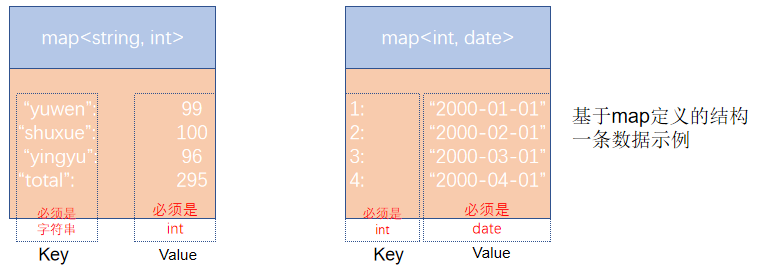
map类型其实就是简单的指代:Key-Value型数据格式。 有如下数据文件,其中members字段是key-value型数据
字段与字段分隔符: “,”;需要map字段之间的分隔符:"#";map内部k-v分隔符:":"
id,name,members,age
1,zhangsan,father:xiaoming#mother:xiaohuang#brother:xiaoxu,28
2,lisi,father:mayun#mother:huangyi#brother:guanyu,22
3,wangwu,father:wangjianlin#mother:ruhua#sister:jingtian,29
4,mayun,father:mayongzhen#mother:angelababy,26建表语句:
create table myhive.test_map(
id int, name string,
members map<string,string>,
age int
)
row format delimited
fields terminated by ','
COLLECTION ITEMS TERMINATED BY '#'
MAP KEYS TERMINATED BY ':';- COLLECTION ITEMS TERMINATED BY '#':表示每个键值对之间用#分隔
- MAP KEYS TERMINATED BY ':' 表示key-value之间用:分隔
示例:
--导入数据
load data local inpath '/home/hadoop/data_for_map_type.txt' overwrite into table myhive.test_map;
--常用查询
-- 查询全部
select * from myhive.test_map;
-- 查询father、mother这两个map的key
select id, name, members['father'], members['mother'], age from myhive.test_map;
-- 查询全部map的key,使用map_keys函数,结果是array类型
select id, name, map_keys(members) as relation from myhive.test_map;
-- 查询全部map的value,使用map_values函数,结果是array类型
select id, name, map_values(members) as relation from myhive.test_map;
-- 查询map类型的KV对数量
select id,name,size(members) num from myhive.test_map;
-- 查询map的key中有brother的数据
select * from myhive.test_map where array_contains(map_keys(members), 'brother');struct类型
struct类型是一个复合类型,可以在一个列中存入多个子列,每个子列允许设置类型和名称
有如下数据文件,说明:字段之间#分割,struct之间冒号分割
1#周杰轮:11
2#林均杰:16
3#刘德滑:21
4#张学油:26
5#蔡依临:23建表语句
create table myhive.test_struct(
id string, info struct<name:string, age:int>
)
row format delimited
fields terminated by '#'
COLLECTION ITEMS TERMINATED BY ':';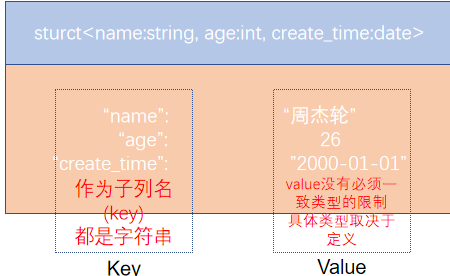
示例:
--导入数据
load data local inpath '/home/hadoop/data_for_struct_type.txt' into table myhive.test_struct;
--常用查询
select * from hive_struct;
-- 直接使用列名.子列名 即可从struct中取出子列查询
select ip, info.name from hive_struct;array、map、struct总结
| 类型 | 定义 | 示例 | 内含元素类型 | 元素个数 | 取元素 | 可用函数 |
|---|---|---|---|---|---|---|
| array | array<类型> | 如定义为array数据为:1,2,3,4,5 | 单值,类型取决于定义 | 动态,不限制 | array[数字序号]序号从0开始 | size统计元素个数array_contains判断是否包含指定数据 |
| map | map | 如定义为:map数据为:{’a’: 1, ‘b’: 2, ‘c’: 3} | 键值对,K-V,K和V类型取决于定义 | 动态,不限制 | map[key] 取出对应key的value | size统计元素个数array_contains判断是否包含指定数据map_keys取出全部key,返回arraymap_values取出全部values,返回array |
| struct | struct<子列名 类型, 子列名 类型…> | 如定义为:struct数据为:’a’, 1, ‘2000-01-01’ | 单值,类型取决于定义 | 固定,取决于定义的子列数量 | struct.子列名通过子列名取出子列值 | 暂无 |
案例实操
需求分析
背景介绍
聊天平台每天都会有大量的用户在线,会出现大量的聊天数据,通过对聊天数据的统计分析,可以更好的对用户构建精准的用户画像,为用户提供更好的服务以及实现=高ROI==的平台运营推广,给公司的发展决策提供精确的数据支撑。
我们将基于一个社交平台App的用户数据,完成相关指标的统计分析并结合BI工具对指标进行可视化展现。
目标
基于Hadoop和Hive实现聊天数据统计分析,构建聊天数据分析报表
需求
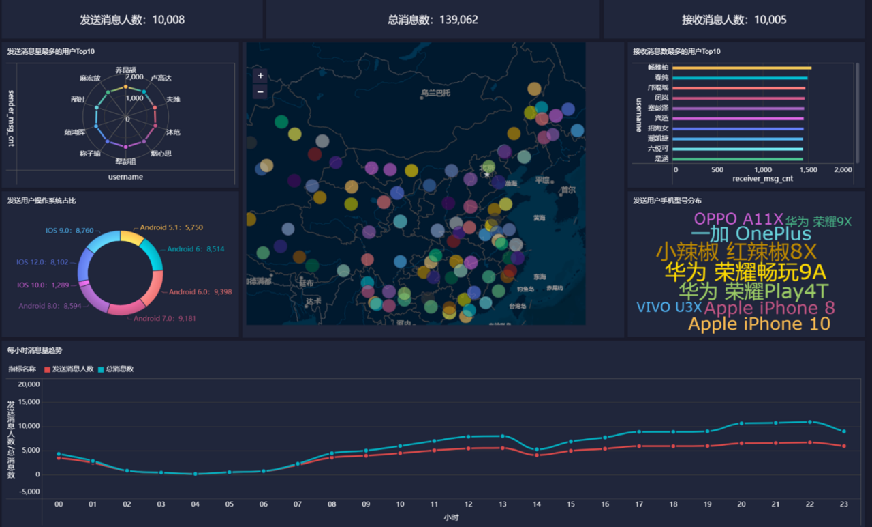
统计今日总消息量
统计今日每小时消息量、发送和接收用户数
统计今日各地区发送消息数据量
统计今日发送消息和接收消息的用户数
统计今日发送消息最多的Top10用户
统计今日接收消息最多的Top10用户
统计发送人的手机型号分布情况
统计发送人的设备操作系统分布情况
 数据内容
数据内容
数据大小:30万条数据
列分隔符:Hive默认分隔符’\001’
数据字典及样例数据
| 消息时间 | 发件人昵称 | 发件人账号 | 发件人性别 | 发件人IP | 发件人系统 | 发件人手机型号 | 发件人网络制式 | 发件人GPS | 收件人昵称 | 收件人IP | 收件人账号 | 收件人系统 | 收件人手机型号 | 收件人网络制式 | 收件人GPS | 收件人性别 | 消息类型 | 双方距离 | 消息 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2021-11-01 15:11:33 | 古博易 | 14747877194 | 男 | 48.147.134.255 | Android 8.0 | 小米 Redmi K30 | 4G | 94.704577,36.247553 | 莱优 | 97.61.25.52 | 17832829395 | IOS 10.0 | Apple iPhone 10 | 4G | 84.034145,41.423804 | 女 | TEXT | 77.82KM | 天涯海角惆怅渡,牛郎织女隔天河。佛祖座前长顿首,只求共度一百年。 |
建库建表
--如果数据库已存在就删除
drop database if exists db_msg cascade ;
--创建数据库
create database db_msg ;
--切换数据库
use db_msg ;
--列举数据库
show databases ;-- 如果表已存在就删除
drop table if exists db_msg.tb_msg_source ;
-- 建表
create table db_msg.tb_msg_source(
msg_time string comment "消息发送时间",
sender_name string comment "发送人昵称",
sender_account string comment "发送人账号",
sender_sex string comment "发送人性别",
sender_ip string comment "发送人ip地址",
sender_os string comment "发送人操作系统",
sender_phonetype string comment "发送人手机型号",
sender_network string comment "发送人网络类型",
sender_gps string comment "发送人的GPS定位",
receiver_name string comment "接收人昵称",
receiver_ip string comment "接收人IP",
receiver_account string comment "接收人账号",
receiver_os string comment "接收人操作系统",
receiver_phonetype string comment "接收人手机型号",
receiver_network string comment "接收人网络类型",
receiver_gps string comment "接收人的GPS定位",
receiver_sex string comment "接收人性别",
msg_type string comment "消息类型",
distance string comment "双方距离",
message string comment "消息内容"
);
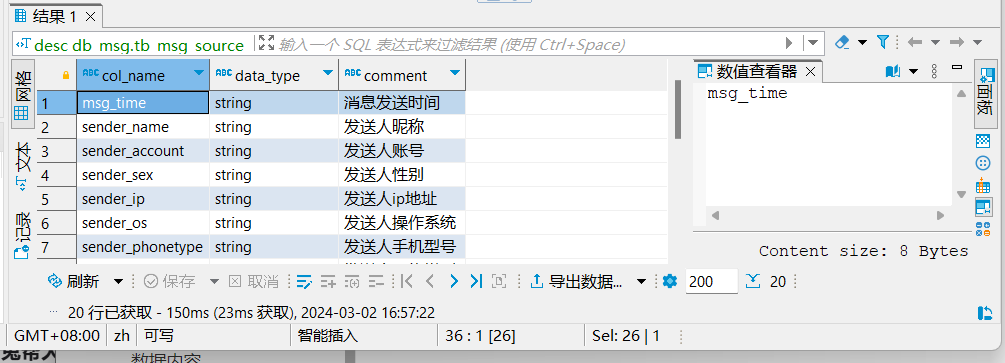
-- 查看表结构
desc db_msg.tb_msg_source;如果出现comment乱码,参考hive 表和字段注释中文乱码(亲测有效)修改
 加载数据
加载数据
- 上传文件到Linux系统
- load数据到表
load data local inpath '/home/hadoop/chat_data-30W.csv' overwrite into table tb_msg_source;验证结果
select
msg_time, sender_name, sender_ip, sender_phonetype, receiver_name, receiver_network
from tb_msg_source limit 10;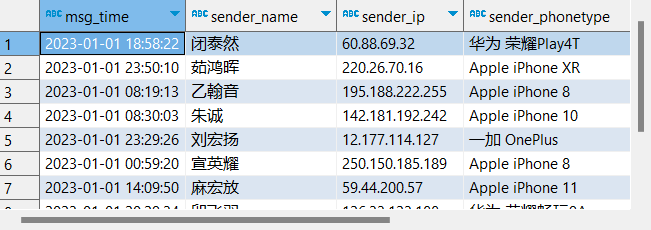
数据清洗
数据问题
问题1:当前数据中,有一些数据的字段为空,不是合法数据
select
msg_time,
sender_name,
sender_gps
from db_msg.tb_msg_source
where length(sender_gps) = 0
limit 10;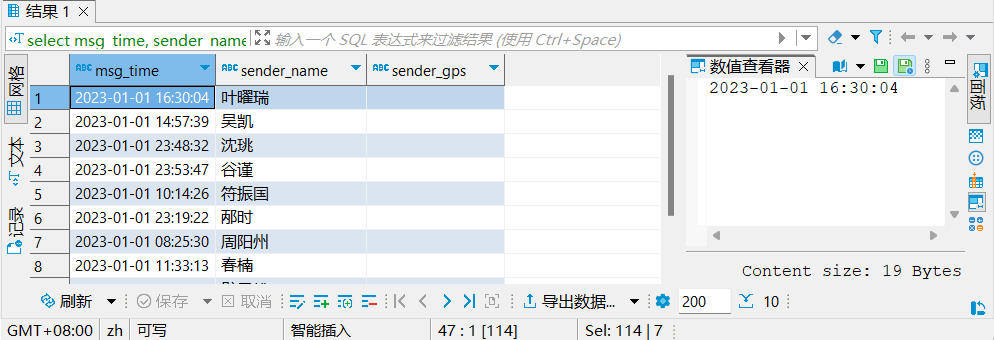
问题2:需求中,需要统计每天、每个小时的消息量,但是数据中没有天和小时字段,只有整体时间字段,不好处理
select
msg_time
from db_msg.tb_msg_source
limit 10;问题3:需求中,需要对经度和维度构建地区的可视化地图,但是数据中GPS经纬度为一个字段,不好处理
select sender_gps
from db_msg.tb_msg_source
limit 10;需求
需求1:对字段为空的不合法数据进行过滤
where过滤
需求2:通过时间字段构建天和小时字段
date hour函数
需求3:从GPS的经纬度中提取经度和维度
split函数
需求4:将ETL以后的结果保存到一张新的Hive表中
--创建新表
create table db_msg.tb_msg_etl(
msg_time string comment "消息发送时间",
sender_name string comment "发送人昵称",
sender_account string comment "发送人账号",
sender_sex string comment "发送人性别",
sender_ip string comment "发送人ip地址",
sender_os string comment "发送人操作系统",
sender_phonetype string comment "发送人手机型号",
sender_network string comment "发送人网络类型",
sender_gps string comment "发送人的GPS定位",
receiver_name string comment "接收人昵称",
receiver_ip string comment "接收人IP",
receiver_account string comment "接收人账号",
receiver_os string comment "接收人操作系统",
receiver_phonetype string comment "接收人手机型号",
receiver_network string comment "接收人网络类型",
receiver_gps string comment "接收人的GPS定位",
receiver_sex string comment "接收人性别",
msg_type string comment "消息类型",
distance string comment "双方距离",
message string comment "消息内容",
msg_day string comment "消息日",
msg_hour string comment "消息小时",
sender_lng double comment "经度",
sender_lat double comment "纬度"
);ETL数据清洗
实现
INSERT OVERWRITE TABLE db_msg.tb_msg_etl
SELECT
*,
day(msg_time) as msg_day,
HOUR(msg_time) as msg_hour,
split(sender_gps, ',')[0] AS sender_lng,
split(sender_gps, ',')[1] AS sender_lat
FROM tb_msg_source WHERE LENGTH(sender_gps) > 0查看结果
select
msg_time, msg_day, msg_hour, sender_gps, sender_lng, sender_lat
from db_msg.tb_msg_etl
limit 10;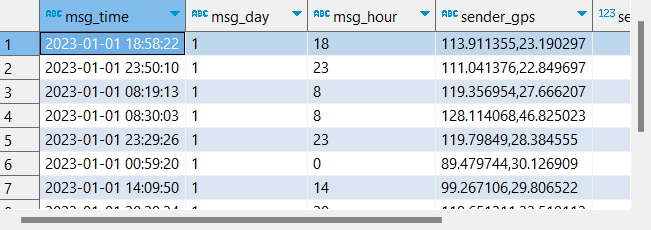
其实我们刚刚完成了
从表tb_msg_source 查询数据进行数据过滤和转换,并将结果写入到:tb_msg_etl表中的操作这种操作,本质上是一种简单的ETL行为。
ETL:
E,Extract,抽取
T,Transform,转换
L,Load,加载
从A抽取数据(E),进行数据转换过滤(T),将结果加载到B(L),就是ETL啦ETL在大数据系统中是非常常见的,后续我们还会继续接触到它。目前简单了解一下即可。
指标计算
需求
统计今日总消息量
统计今日每小时消息量、发送和接收用户数
统计今日各地区发送消息数据量
统计今日发送消息和接收消息的用户数
统计今日发送消息最多的Top10用户
统计今日接收消息最多的Top10用户
统计发送人的手机型号分布情况
统计发送人的设备操作系统分布情况
需求指标统计
--1.统计今日总消息量
CREATE TABLE IF NOT EXISTS tb_rs_total_msg_cnt
COMMENT "每日消息总量" AS
SELECT
msg_day,
COUNT(*) AS total_msg_cnt
FROM db_msg.tb_msg_etl
GROUP BY msg_day;
--2.统计今日每小时消息量、发送和接收用户数
CREATE TABLE IF NOT EXISTS tb_rs_hour_msg_cnt
COMMENT "每小时消息量趋势" AS
SELECT
msg_hour,
COUNT(*) AS total_msg_cnt,
COUNT(DISTINCT sender_account) AS sender_usr_cnt,
COUNT(DISTINCT receiver_account) AS receiver_usr_cnt
FROM db_msg.tb_msg_etl GROUP BY msg_hour;
--3.统计今日各地区发送消息数据量
CREATE TABLE IF NOT EXISTS tb_rs_loc_cnt
COMMENT '今日各地区发送消息总量' AS
SELECT
msg_day,
sender_lng,
sender_lat,
COUNT(*) AS total_msg_cnt
FROM db_msg.tb_msg_etl
GROUP BY msg_day, sender_lng, sender_lat;
SELECT * from tb_rs_loc_cnt limit 10;
--4.统计今日发送消息和接收消息的用户数
--保存结果表
CREATE TABLE IF NOT EXISTS tb_rs_usr_cnt
COMMENT "今日发送消息人数、接受消息人数" AS
SELECT
msg_day,
COUNT(DISTINCT sender_account) AS sender_usr_cnt,
COUNT(DISTINCT receiver_account) AS receiver_usr_cnt
FROM db_msg.tb_msg_etl
GROUP BY msg_day;
SELECT * from tb_rs_usr_cnt;
--5.统计今日发送消息最多的Top10用户
--保存结果表
CREATE TABLE IF NOT EXISTS db_msg.tb_rs_s_user_top10
COMMENT "发送消息条数最多的Top10用户" AS
SELECT
sender_name AS username,
COUNT(*) AS sender_msg_cnt
FROM db_msg.tb_msg_etl
GROUP BY sender_name
ORDER BY sender_msg_cnt DESC
LIMIT 10;
SELECT * from db_msg.tb_rs_s_user_top10 limit 10;
--6.统计今日接收消息最多的Top10用户
CREATE TABLE IF NOT EXISTS db_msg.tb_rs_r_user_top10
COMMENT "接收消息条数最多的Top10用户" AS
SELECT
receiver_name AS username,
COUNT(*) AS receiver_msg_cnt
FROM db_msg.tb_msg_etl
GROUP BY receiver_name
ORDER BY receiver_msg_cnt DESC
LIMIT 10;
SELECT * from db_msg.tb_rs_r_user_top10 limit 10;
--7.统计发送人的手机型号分布情况
CREATE TABLE IF NOT EXISTS db_msg.tb_rs_sender_phone
COMMENT "发送人的手机型号分布" AS
SELECT
sender_phonetype,
COUNT(sender_account) AS cnt
FROM db_msg.tb_msg_etl
GROUP BY sender_phonetype;
SELECT * from db_msg.tb_rs_sender_phone limit 10;
--8.统计发送人的设备操作系统分布情况
--保存结果表
CREATE TABLE IF NOT EXISTS db_msg.tb_rs_sender_os
COMMENT "发送人的OS分布" AS
SELECT
sender_os,
COUNT(sender_account) AS cnt
FROM db_msg.tb_msg_etl
GROUP BY sender_os
SELECT * from db_msg.tb_rs_sender_os limit 10;可视化展示
BI
BI:Business Intelligence,商业智能。
指用现代数据仓库技术、线上分析处理技术、数据挖掘和数据展现技术进行数据分析以实现商业价值。
简单来说,就是借助BI工具,可以完成复杂的数据分析、数据统计等需求,为公司决策带来巨大的价值。
所以,一般提到BI,我们指代的就是工具软件。常见的BI软件很多,比如:
FineBI、SuperSet、PowerBI、TableAu等。
FineBI的介绍及安装
FineBI的介绍:https://www.finebi.com/
FineBI 是帆软软件有限公司推出的一款商业智能(Business Intelligence)产品。FineBI 是定位于自助大数据分析的 BI 工具,能够帮助企业的业务人员和数据分析师,开展以问题导向的探索式分析。
FineBI的特点:
通过多人协作来实现最终的可视化构建
不需要通过复杂代码来实现开发,通过可视化操作实现开发
适合于各种数据可视化的应用场景
支持各种常见的分析图表和各种数据源
支持处理大数据
FineBI的界面
启动登陆,选内置数据看。
目录:首页大屏及帮助文档
仪表盘:用于构建所有可视化报表
数据准备:用于配置各种报表的数据来源
管理系统:用于管理整个FineBI的使用:用户管理、数据源管理、插件管理、权限管理等
FineBI配置数据源及数据准备
FineBI与Hive集成的官方文档:https://help.fanruan.com/finebi/doc-view-301.html
驱动配置
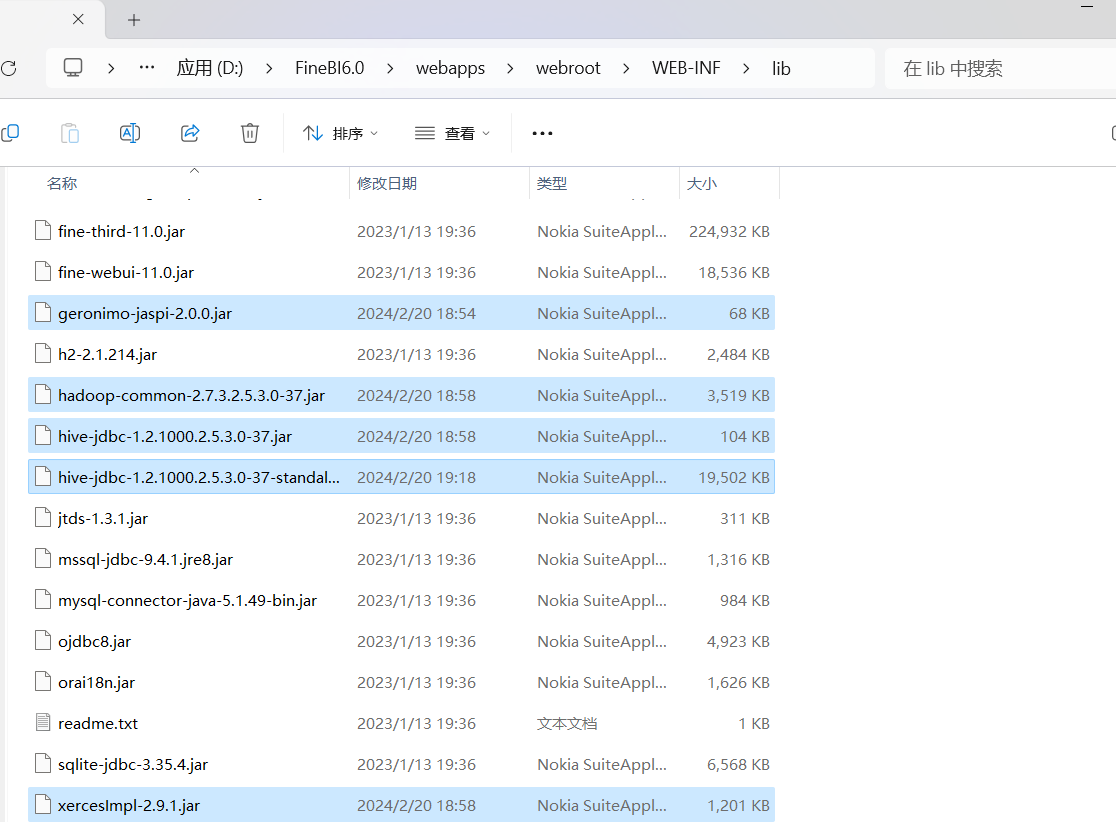
问题:如果使用FineBI连接Hive,读取Hive的数据表,需要在FineBI中添加Hive的驱动jar包
解决:将Hive的驱动jar包放入FineBI的lib目录下
step1:找到提供的【Hive连接驱动】
step2:将这些文件放入FineBI的安装目录下的:webapps\webroot\WEB-INF\lib目录中
插件安装
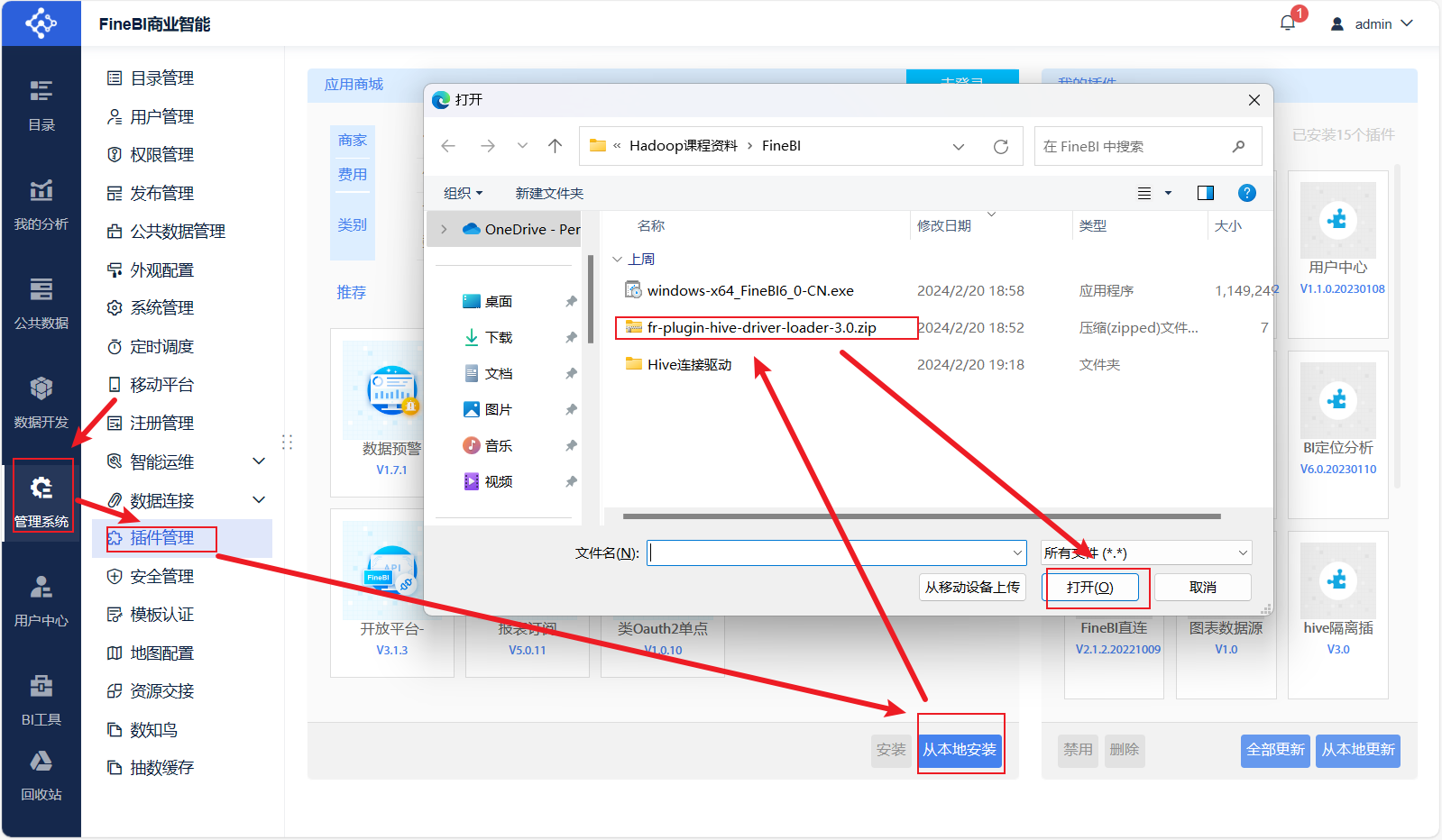
问题:我们自己放的Hive驱动包会与FineBI自带的驱动包产生冲突,导致FineBI无法识别我们自己的驱动包
解决:安装FineBI官方提供的驱动包隔离插件
step1:找到隔离插件
step2:安装插件
step3:重启FineBI
新建连接
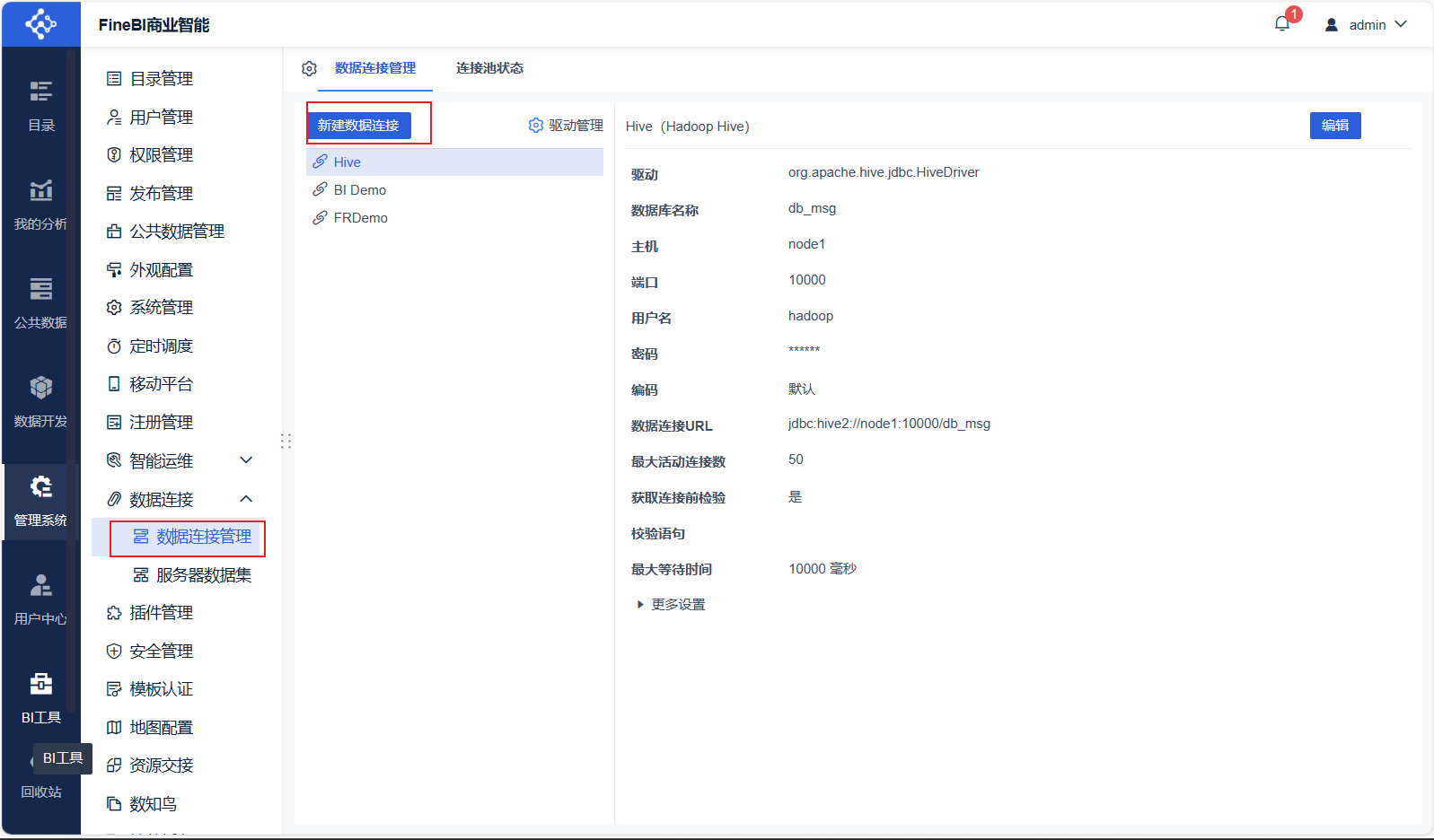

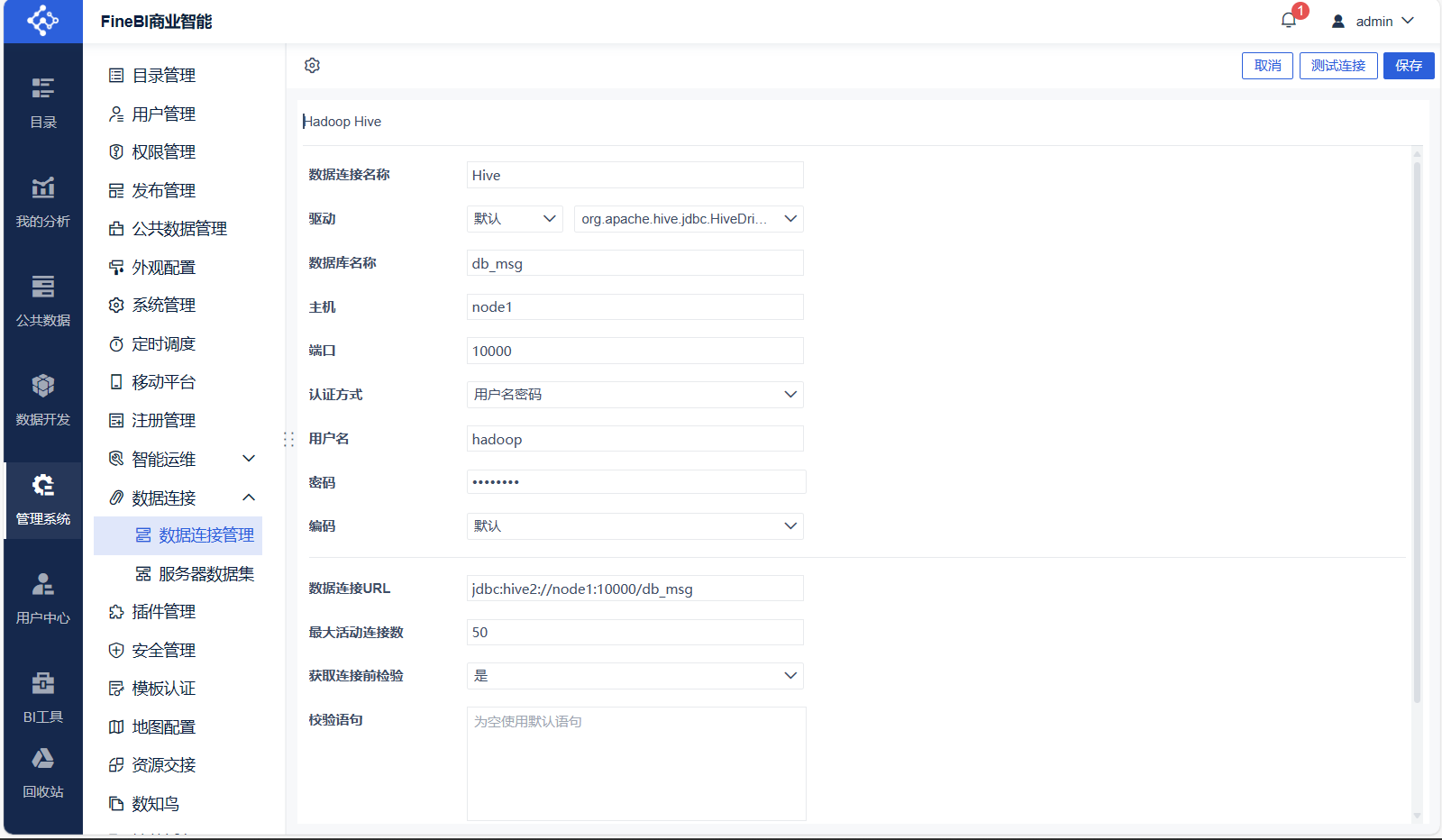
测试连接,保存连接
数据准备
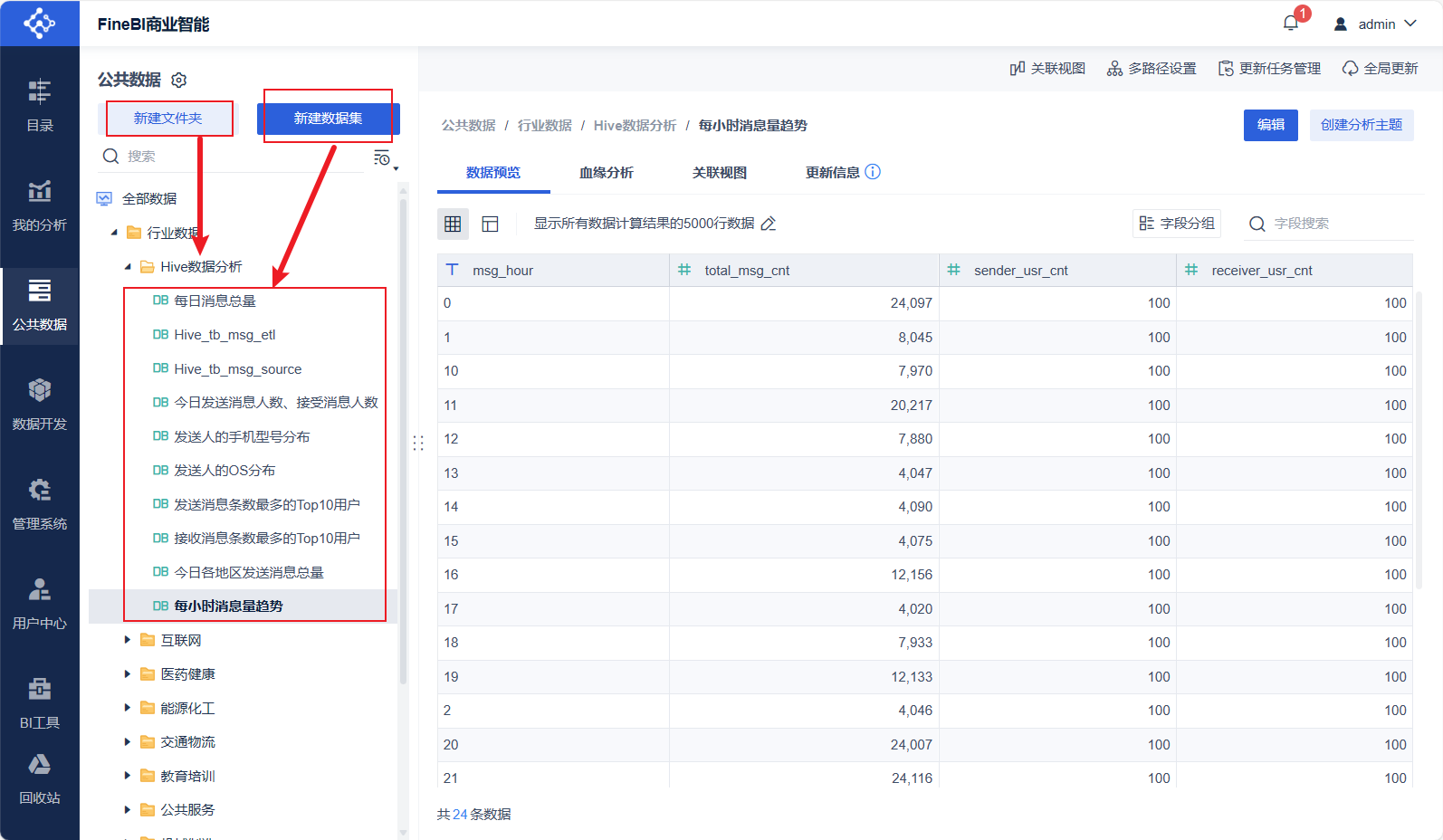
选中8个分析的结果表,确定,然后更新数据。
新建文件夹之后,选中,新建分析主题。
可视化展示
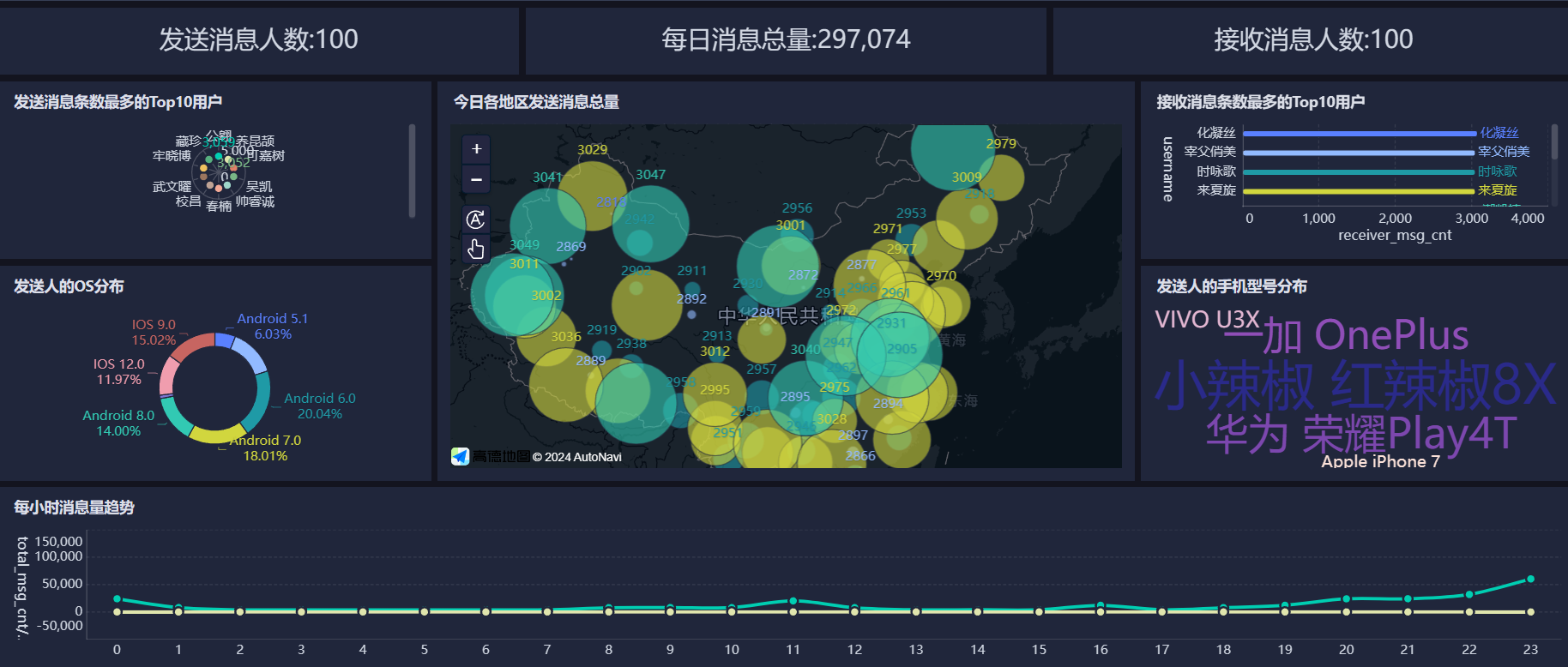
基于FineBI完成指标的可视化展现
接下来就是拖拖拽拽了,skip
结果展示
Comments NOTHING