LangChain 为基于 LLM 开发自定义应用提供了高效的开发框架,便于开发者迅速地激发 LLM 的强大能力,搭建 LLM 应用。LangChain 也同样支持多种大模型,内置了 OpenAI、LLAMA 等大模型的调用接口。但是,LangChain 并没有内置所有大模型,它通过允许用户自定义 LLM 类型,来提供强大的可扩展性。
1. 基于 LangChain 调用 ChatGPT
LangChain 提供了对于多种大模型的封装,基于 LangChain 的接口可以便捷地调用 ChatGPT 并将其集合在以 LangChain 为基础框架搭建的个人应用中。我们在此简述如何使用 LangChain 接口来调用 ChatGPT。
注意,基于 LangChain 接口调用 ChatGPT 同样需要配置你的个人密钥,配置方法同上。
PS:如果使用第三方OpenAI接口,需要在env中添加OPENAI_API_BASE = "https://你的API接口域名/"
1.1 Models(模型)
从 langchain.chat_models 导入 OpenAI 的对话模型 ChatOpenAI 。 除去OpenAI以外,langchain.chat_models 还集成了其他对话模型,更多细节可以查看Langchain官方文档。
import os
import openai
from dotenv import load_dotenv, find_dotenv
# 读取本地/项目的环境变量。
# find_dotenv()寻找并定位.env文件的路径
# load_dotenv()读取该.env文件,并将其中的环境变量加载到当前的运行环境中
# 如果你设置的是全局的环境变量,这行代码则没有任何作用。
_ = load_dotenv(find_dotenv())
# 获取环境变量 OPENAI_API_KEY
openai_api_key = os.environ['OPENAI_API_KEY']Copy to clipboardErrorCopied没有安装 langchain-openai 的话,请先运行下面进行代码!
from langchain_openai import ChatOpenAICopy to clipboardErrorCopied接下来你需要实例化一个 ChatOpenAI 类,可以在实例化时传入超参数来控制回答,例如 temperature 参数。
# 这里我们将参数temperature设置为0.0,从而减少生成答案的随机性。
# 如果你想要每次得到不一样的有新意的答案,可以尝试调整该参数。
llm = ChatOpenAI(temperature=0.0)
llmCopy to clipboardErrorCopied
ChatOpenAI(client=<openai.resources.chat.completions.Completions object at 0x000001B17F799BD0>, async_client=<openai.resources.chat.completions.AsyncCompletions object at 0x000001B17F79BA60>, temperature=0.0, openai_api_key=SecretStr('**********'), openai_api_base='https://api.chatgptid.net/v1', openai_proxy='')Copy to clipboardErrorCopied上面的 cell 假设你的 OpenAI API 密钥是在环境变量中设置的,如果您希望手动指定API密钥,请使用以下代码:
llm = ChatOpenAI(temperature=0, openai_api_key="YOUR_API_KEY")Copy to clipboardErrorCopied可以看到,默认调用的是 ChatGPT-3.5 模型。另外,几种常用的超参数设置包括:
· model_name:所要使用的模型,默认为 ‘gpt-3.5-turbo’,参数设置与 OpenAI 原生接口参数设置一致。
· temperature:温度系数,取值同原生接口。
· openai_api_key:OpenAI API key,如果不使用环境变量设置 API Key,也可以在实例化时设置。
· openai_proxy:设置代理,如果不使用环境变量设置代理,也可以在实例化时设置。
· streaming:是否使用流式传输,即逐字输出模型回答,默认为 False,此处不赘述。
· max_tokens:模型输出的最大 token 数,意义及取值同上。Copy to clipboardErrorCopied当我们初始化了你选择的LLM后,我们就可以尝试使用它!让我们问一下“请你自我介绍一下自己!”
output = llm.invoke("请你自我介绍一下自己!")Copy to clipboardErrorCopied
output
1.2 Prompt (提示模版)
在我们开发大模型应用时,大多数情况下不会直接将用户的输入直接传递给 LLM。通常,他们会将用户输入添加到一个较大的文本中,称为提示模板,该文本提供有关当前特定任务的附加上下文。 PromptTemplates 正是帮助解决这个问题!它们捆绑了从用户输入到完全格式化的提示的所有逻辑。这可以非常简单地开始 - 例如,生成上述字符串的提示就是:
我们需要先构造一个个性化 Template:
from langchain_core.prompts import ChatPromptTemplate
# 这里我们要求模型对给定文本进行中文翻译
prompt = """请你将由三个反引号分割的文本翻译成英文!\
text: ```{text}```
"""Copy to clipboardErrorCopied接下来让我们看一下构造好的完整的提示模版:
text = "我带着比身体重的行李,\
游入尼罗河底,\
经过几道闪电 看到一堆光圈,\
不确定是不是这里。\
"
prompt.format(text=text)Copy to clipboardErrorCopied
'请你将由三个反引号分割的文本翻译成英文!text: ```我带着比身体重的行李,游入尼罗河底,经过几道闪电 看到一堆光圈,不确定是不是这里。```\n'Copy to clipboardErrorCopied我们知道聊天模型的接口是基于消息(message),而不是原始的文本。PromptTemplates 也可以用于产生消息列表,在这种样例中,prompt不仅包含了输入内容信息,也包含了每条message的信息(角色、在列表中的位置等)。通常情况下,一个 ChatPromptTemplate 是一个 ChatMessageTemplate 的列表。每个 ChatMessageTemplate 包含格式化该聊天消息的说明(其角色以及内容)。
让我们一起看一个示例:
from langchain.prompts.chat import ChatPromptTemplate
template = "你是一个翻译助手,可以帮助我将 {input_language} 翻译成 {output_language}."
human_template = "{text}"
chat_prompt = ChatPromptTemplate.from_messages([
("system", template),
("human", human_template),
])
text = "我带着比身体重的行李,\
游入尼罗河底,\
经过几道闪电 看到一堆光圈,\
不确定是不是这里。\
"
messages = chat_prompt.format_messages(input_language="中文", output_language="英文", text=text)
messages[SystemMessage(content='你是一个翻译助手,可以帮助我将 中文 翻译成 英文.'),
HumanMessage(content='我带着比身体重的行李,游入尼罗河底,经过几道闪电 看到一堆光圈,不确定是不是这里。')]output = llm.invoke(messages)
outputAIMessage(content='I carried luggage heavier than my body and dived into the bottom of the Nile. After passing through several flashes of lightning, I saw a pile of halos, not sure if this is the place.', response_metadata={'token_usage': {'completion_tokens': 41, 'prompt_tokens': 95, 'total_tokens': 136, 'pre_token_count': 16384, 'pre_total': 124, 'adjust_total': 123, 'final_total': 1}, 'model_name': 'gpt-3.5-turbo', 'system_fingerprint': 'fp_c2295e73ad', 'finish_reason': 'stop', 'logprobs': None}, id='run-14982c3d-f240-4abb-aa8a-8570417cc081-0')1.3 Output parser(输出解析器)
OutputParsers 将语言模型的原始输出转换为可以在下游使用的格式。 OutputParsers 有几种主要类型,包括:
- 将 LLM 文本转换为结构化信息(例如 JSON)
- 将 ChatMessage 转换为字符串
- 将除消息之外的调用返回的额外信息(如 OpenAI 函数调用)转换为字符串
最后,我们将模型输出传递给 output_parser,它是一个 BaseOutputParser,这意味着它接受字符串或 BaseMessage 作为输入。 StrOutputParser 特别简单地将任何输入转换为字符串。
from langchain_core.output_parsers import StrOutputParser
output_parser = StrOutputParser()
output_parser.invoke(output)
'I carried luggage heavier than my body and dived into the bottom of the Nile. After passing through several flashes of lightning, I saw a pile of halos, not sure if this is the place.'从上面结果可以看到,我们通过输出解析器成功将 ChatMessage 类型的输出解析为了字符串
1.4 完整的流程
我们现在可以将所有这些组合成一条链。该链将获取输入变量,将这些变量传递给提示模板以创建提示,将提示传递给语言模型,然后通过(可选)输出解析器传递输出。接下来我们将使用LCEL这种语法去快速实现一条链(chain)。让我们看看它的实际效果!
chain = chat_prompt | llm | output_parser
chain.invoke({"input_language":"中文", "output_language":"英文","text": text})
Copy to clipboardErrorCopied
'I carried luggage heavier than my body and dived into the bottom of the Nile River. After passing through several flashes of lightning, I saw a pile of halos, not sure if this is the place.'Copy to clipboardErrorCopied再测试一个样例:
text = 'I carried luggage heavier than my body and dived into the bottom of the Nile River. After passing through several flashes of lightning, I saw a pile of halos, not sure if this is the place.'
chain.invoke({"input_language":"英文", "output_language":"中文","text": text})Copy to clipboardErrorCopied
'我扛着比我的身体还重的行李,潜入尼罗河的底部。穿过几道闪电后,我看到一堆光环,不确定这是否就是目的地。'Copy to clipboardErrorCopied什么是 LCEL ? LCEL(LangChain Expression Language,Langchain的表达式语言),LCEL是一种新的语法,是LangChain工具包的重要补充,他有许多优点,使得我们处理LangChain和代理更加简单方便。
- LCEL提供了异步、批处理和流处理支持,使代码可以快速在不同服务器中移植。
- LCEL拥有后备措施,解决LLM格式输出的问题。
- LCEL增加了LLM的并行性,提高了效率。
- LCEL内置了日志记录,即使代理变得复杂,有助于理解复杂链条和代理的运行情况。
用法示例:
chain = prompt | model | output_parser上面代码中我们使用 LCEL 将不同的组件拼凑成一个链,在此链中,用户输入传递到提示模板,然后提示模板输出传递到模型,然后模型输出传递到输出解析器。| 的符号类似于 Unix 管道运算符,它将不同的组件链接在一起,将一个组件的输出作为下一个组件的输入。
构建检索问答链
在 C3 搭建数据库 章节,我们已经介绍了如何根据自己的本地知识文档,搭建一个向量知识库。 在接下来的内容里,我们将使用搭建好的向量数据库,对 query 查询问题进行召回,并将召回结果和 query 结合起来构建 prompt,输入到大模型中进行问答。
1. 加载向量数据库
首先,我们加载在前一章已经构建的向量数据库。注意,此处你需要使用和构建时相同的 Emedding。
import sys
sys.path.append("../C3 搭建知识库") # 将父目录放入系统路径中
# 使用智谱 Embedding API,注意,需要将上一章实现的封装代码下载到本地
from zhipuai_embedding import ZhipuAIEmbeddings
from langchain.vectorstores.chroma import Chroma从环境变量中加载你的 API_KEY
from dotenv import load_dotenv, find_dotenv
import os
_ = load_dotenv(find_dotenv()) # read local .env file
zhipuai_api_key = os.environ['ZHIPUAI_API_KEY']加载向量数据库,其中包含了 ../../data_base/knowledge_db 下多个文档的 Embedding
# 定义 Embeddings
embedding = ZhipuAIEmbeddings()
# 向量数据库持久化路径
persist_directory = '../C3 搭建知识库/data_base/vector_db/chroma'
# 加载数据库
vectordb = Chroma(
persist_directory=persist_directory, # 允许我们将persist_directory目录保存到磁盘上
embedding_function=embedding
)print(f"向量库中存储的数量:{vectordb._collection.count()}")向量库中存储的数量:20我们可以测试一下加载的向量数据库,使用一个问题 query 进行向量检索。如下代码会在向量数据库中根据相似性进行检索,返回前 k 个最相似的文档。
⚠️使用相似性搜索前,请确保你已安装了 OpenAI 开源的快速分词工具 tiktoken 包:
pip install tiktoken
question = "什么是prompt engineering?"
docs = vectordb.similarity_search(question,k=3)
print(f"检索到的内容数:{len(docs)}")检索到的内容数:3打印一下检索到的内容
for i, doc in enumerate(docs):
print(f"检索到的第{i}个内容: \n {doc.page_content}", end="\n-----------------------------------------------------\n")检索到的第0个内容:
相反,我们应通过 Prompt 指引语言模型进行深入思考。可以要求其先列出对问题的各种看法,说明推理依据,然后再得出最终结论。在 Prompt 中添加逐步推理的要求,能让语言模型投入更多时间逻辑思维,输出结果也将更可靠准确。
综上所述,给予语言模型充足的推理时间,是 Prompt Engineering 中一个非常重要的设计原则。这将大大提高语言模型处理复杂问题的效果,也是构建高质量 Prompt 的关键之处。开发者应注意给模型留出思考空间,以发挥语言模型的最大潜力。
2.1 指定完成任务所需的步骤
接下来我们将通过给定一个复杂任务,给出完成该任务的一系列步骤,来展示这一策略的效果。
首先我们描述了杰克和吉尔的故事,并给出提示词执行以下操作:首先,用一句话概括三个反引号限定的文本。第二,将摘要翻译成英语。第三,在英语摘要中列出每个名称。第四,输出包含以下键的 JSON 对象:英语摘要和人名个数。要求输出以换行符分隔。
-----------------------------------------------------
检索到的第1个内容:
第二章 提示原则
如何去使用 Prompt,以充分发挥 LLM 的性能?首先我们需要知道设计 Prompt 的原则,它们是每一个开发者设计 Prompt 所必须知道的基础概念。本章讨论了设计高效 Prompt 的两个关键原则:编写清晰、具体的指令和给予模型充足思考时间。掌握这两点,对创建可靠的语言模型交互尤为重要。
首先,Prompt 需要清晰明确地表达需求,提供充足上下文,使语言模型准确理解我们的意图,就像向一个外星人详细解释人类世界一样。过于简略的 Prompt 往往使模型难以把握所要完成的具体任务。
其次,让语言模型有充足时间推理也极为关键。就像人类解题一样,匆忙得出的结论多有失误。因此 Prompt 应加入逐步推理的要求,给模型留出充分思考时间,这样生成的结果才更准确可靠。
如果 Prompt 在这两点上都作了优化,语言模型就能够尽可能发挥潜力,完成复杂的推理和生成任务。掌握这些 Prompt 设计原则,是开发者取得语言模型应用成功的重要一步。
一、原则一 编写清晰、具体的指令
-----------------------------------------------------
检索到的第2个内容:
一、原则一 编写清晰、具体的指令
亲爱的读者,在与语言模型交互时,您需要牢记一点:以清晰、具体的方式表达您的需求。假设您面前坐着一位来自外星球的新朋友,其对人类语言和常识都一无所知。在这种情况下,您需要把想表达的意图讲得非常明确,不要有任何歧义。同样的,在提供 Prompt 的时候,也要以足够详细和容易理解的方式,把您的需求与上下文说清楚。
并不是说 Prompt 就必须非常短小简洁。事实上,在许多情况下,更长、更复杂的 Prompt 反而会让语言模型更容易抓住关键点,给出符合预期的回复。原因在于,复杂的 Prompt 提供了更丰富的上下文和细节,让模型可以更准确地把握所需的操作和响应方式。
所以,记住用清晰、详尽的语言表达 Prompt,就像在给外星人讲解人类世界一样,“Adding more context helps the model understand you better.”。
从该原则出发,我们提供几个设计 Prompt 的技巧。
1.1 使用分隔符清晰地表示输入的不同部分
-----------------------------------------------------2. 创建一个 LLM
在这里,我们调用 OpenAI 的 API 创建一个 LLM,当然你也可以使用其他 LLM 的 API 进行创建
import os
OPENAI_API_KEY = os.environ["OPENAI_API_KEY"]from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model_name = "gpt-3.5-turbo", temperature = 0)
llm.invoke("请你自我介绍一下自己!")AIMessage(content='你好,我是一个智能助手,专门为用户提供各种服务和帮助。我可以回答问题、提供信息、解决问题等等。如果您有任何需要,请随时告诉我,我会尽力帮助您的。感谢您的使用!', response_metadata={'token_usage': {'completion_tokens': 81, 'prompt_tokens': 20, 'total_tokens': 101}, 'model_name': 'gpt-3.5-turbo', 'system_fingerprint': 'fp_3bc1b5746c', 'finish_reason': 'stop', 'logprobs': None})
3. 构建检索问答链
from langchain.prompts import PromptTemplate
template = """使用以下上下文来回答最后的问题。如果你不知道答案,就说你不知道,不要试图编造答
案。最多使用三句话。尽量使答案简明扼要。总是在回答的最后说“谢谢你的提问!”。
{context}
问题: {question}
"""
QA_CHAIN_PROMPT = PromptTemplate(input_variables=["context","question"],
template=template)
再创建一个基于模板的检索链:
from langchain.chains import RetrievalQA
qa_chain = RetrievalQA.from_chain_type(llm,
retriever=vectordb.as_retriever(),
return_source_documents=True,
chain_type_kwargs={"prompt":QA_CHAIN_PROMPT})
创建检索 QA 链的方法 RetrievalQA.from_chain_type() 有如下参数:
- llm:指定使用的 LLM
- 指定 chain type : RetrievalQA.from_chain_type(chain_type="map_reduce"),也可以利用load_qa_chain()方法指定chain type。
- 自定义 prompt :通过在RetrievalQA.from_chain_type()方法中,指定chain_type_kwargs参数,而该参数:chain_type_kwargs = {"prompt": PROMPT}
- 返回源文档:通过RetrievalQA.from_chain_type()方法中指定:return_source_documents=True参数;也可以使用RetrievalQAWithSourceChain()方法,返回源文档的引用(坐标或者叫主键、索引)
4.检索问答链效果测试
question_1 = "什么是南瓜书?"
question_2 = "王阳明是谁?"4.1 基于召回结果和 query 结合起来构建的 prompt 效果
result = qa_chain({"query": question_1})
print("大模型+知识库后回答 question_1 的结果:")
print(result["result"])d:\Miniconda\miniconda3\envs\llm2\lib\site-packages\langchain_core\_api\deprecation.py:117: LangChainDeprecationWarning: The function __call__ was deprecated in LangChain 0.1.0 and will be removed in 0.2.0. Use invoke instead.
warn_deprecated(
大模型+知识库后回答 question_1 的结果:
南瓜书是指《计算机程序的构造和解释》一书的俗称,是一本经典的计算机科学教材。
谢谢你的提问!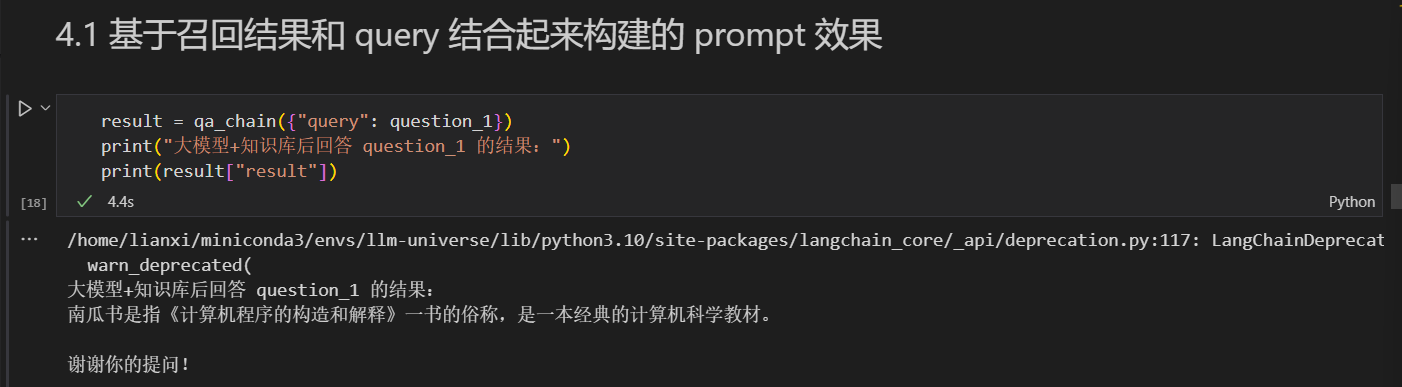
result = qa_chain({"query": question_2})
print("大模型+知识库后回答 question_2 的结果:")
print(result["result"])大模型+知识库后回答 question_2 的结果:
王阳明是明代著名的思想家、军事家和教育家,提出了“致良知”和“格物致知”的理论。
谢谢你的提问!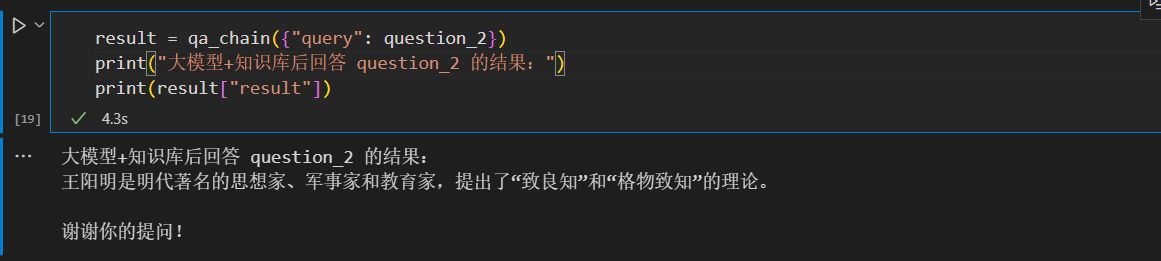
4.2 大模型自己回答的效果
prompt_template = """请回答下列问题:
{}""".format(question_1)
### 基于大模型的问答
llm.predict(prompt_template)d:\Miniconda\miniconda3\envs\llm2\lib\site-packages\langchain_core\_api\deprecation.py:117: LangChainDeprecationWarning: The function predict was deprecated in LangChain 0.1.7 and will be removed in 0.2.0. Use invoke instead.
warn_deprecated(
'南瓜书是指一种关于南瓜的书籍,通常是指介绍南瓜的种植、养护、烹饪等方面知识的书籍。南瓜书也可以指一种以南瓜为主题的文学作品。'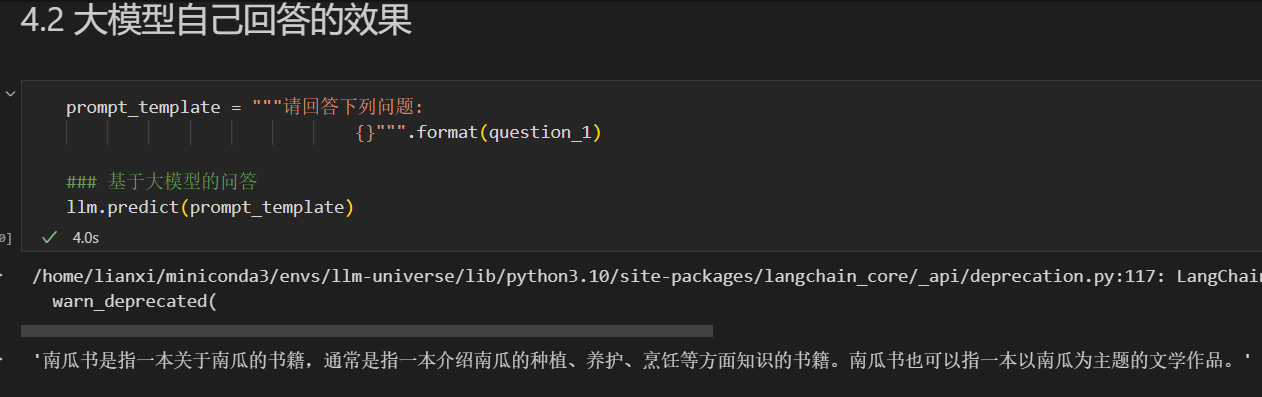
prompt_template = """请回答下列问题:
{}""".format(question_2)
### 基于大模型的问答
llm.predict(prompt_template)'王阳明(1472年-1529年),字宪,号阳明,浙江绍兴人,明代著名的哲学家、军事家、教育家、政治家。他提出了“致良知”、“格物致知”等重要思想,强调人的内心本具良知,只要发挥良知,就能认识道德真理。他的思想对后世影响深远,被称为“阳明心学”。'
⭐ 通过以上两个问题,我们发现 LLM 对于一些近几年的知识以及非常识性的专业问题,回答的并不是很好。而加上我们的本地知识,就可以帮助 LLM 做出更好的回答。另外,也有助于缓解大模型的“幻觉”问题。
5. 添加历史对话的记忆功能
现在我们已经实现了通过上传本地知识文档,然后将他们保存到向量知识库,通过将查询问题与向量知识库的召回结果进行结合输入到 LLM 中,我们就得到了一个相比于直接让 LLM 回答要好得多的结果。在与语言模型交互时,你可能已经注意到一个关键问题 - 它们并不记得你之前的交流内容。这在我们构建一些应用程序(如聊天机器人)的时候,带来了很大的挑战,使得对话似乎缺乏真正的连续性。这个问题该如何解决呢?
1. 记忆(Memory)
在本节中我们将介绍 LangChain 中的储存模块,即如何将先前的对话嵌入到语言模型中的,使其具有连续对话的能力。我们将使用 ConversationBufferMemory ,它保存聊天消息历史记录的列表,这些历史记录将在回答问题时与问题一起传递给聊天机器人,从而将它们添加到上下文中。
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory(
memory_key="chat_history", # 与 prompt 的输入变量保持一致。
return_messages=True # 将以消息列表的形式返回聊天记录,而不是单个字符串
)关于更多的 Memory 的使用,包括保留指定对话轮数、保存指定 token 数量、保存历史对话的总结摘要等内容,请参考 langchain 的 Memory 部分的相关文档。
2. 对话检索链(ConversationalRetrievalChain)
对话检索链(ConversationalRetrievalChain)在检索 QA 链的基础上,增加了处理对话历史的能力。
它的工作流程是:
- 将之前的对话与新问题合并生成一个完整的查询语句。
- 在向量数据库中搜索该查询的相关文档。
- 获取结果后,存储所有答案到对话记忆区。
- 用户可在 UI 中查看完整的对话流程。

这种链式方式将新问题放在之前对话的语境中进行检索,可以处理依赖历史信息的查询。并保留所有信
息在对话记忆中,方便追踪。
接下来让我们可以测试这个对话检索链的效果:
使用上一节中的向量数据库和 LLM !首先提出一个无历史对话的问题“这门课会学习 Python 吗?”,并查看回答。
from langchain.chains import ConversationalRetrievalChain
retriever=vectordb.as_retriever()
qa = ConversationalRetrievalChain.from_llm(
llm,
retriever=retriever,
memory=memory
)
question = "我可以学习到关于提示工程的知识吗?"
result = qa({"question": question})
print(result['answer'])是的,您可以学习到关于提示工程的知识。本模块内容基于吴恩达老师的《Prompt Engineering for Developer》课程编写,旨在分享使用提示词开发大语言模型应用的最佳实践和技巧。课程将介绍设计高效提示的原则,包括编写清晰、具体的指令和给予模型充足思考时间等。通过学习这些内容,您可以更好地利用大语言模型的性能,构建出色的语言模型应用。然后基于答案进行下一个问题“为什么这门课需要教这方面的知识?”:
question = "为什么这门课需要教这方面的知识?"
result = qa({"question": question})
print(result['answer'])这门课程需要教授关于Prompt Engineering的知识,主要是为了帮助开发者更好地使用大型语言模型(LLM)来完成各种任务。通过学习Prompt Engineering,开发者可以学会如何设计清晰明确的提示词,以指导语言模型生成符合预期的文本输出。这种技能对于开发基于大型语言模型的应用程序和解决方案非常重要,可以提高模型的效率和准确性。可以看到,LLM 它准确地判断了这方面的知识,指代内容是强化学习的知识,也就
是我们成功地传递给了它历史信息。这种持续学习和关联前后问题的能力,可大大增强问答系统的连续
性和智能水平。
Comments NOTHING