登录平台中心
https://platform.virtaicloud.com/
Step.1 创建项目
- 创建好账号之后,进入自己的空间,点击右上角的创建项目。
- 给项目起一个你喜欢的名称(这里以ChatGLM3为例)
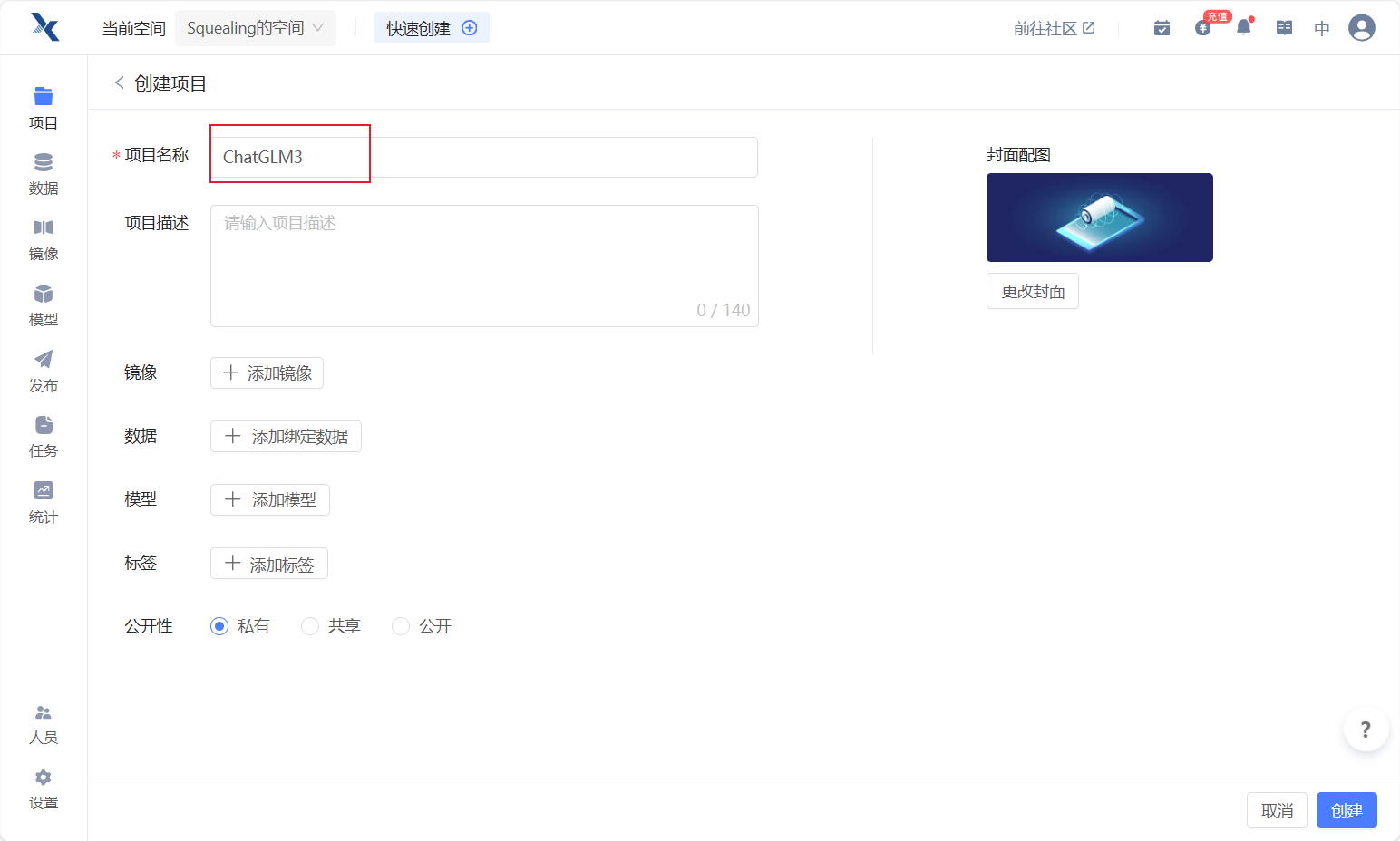
- 选择添加镜像,搜索"PyTorch2.0.1-Conda3.9"
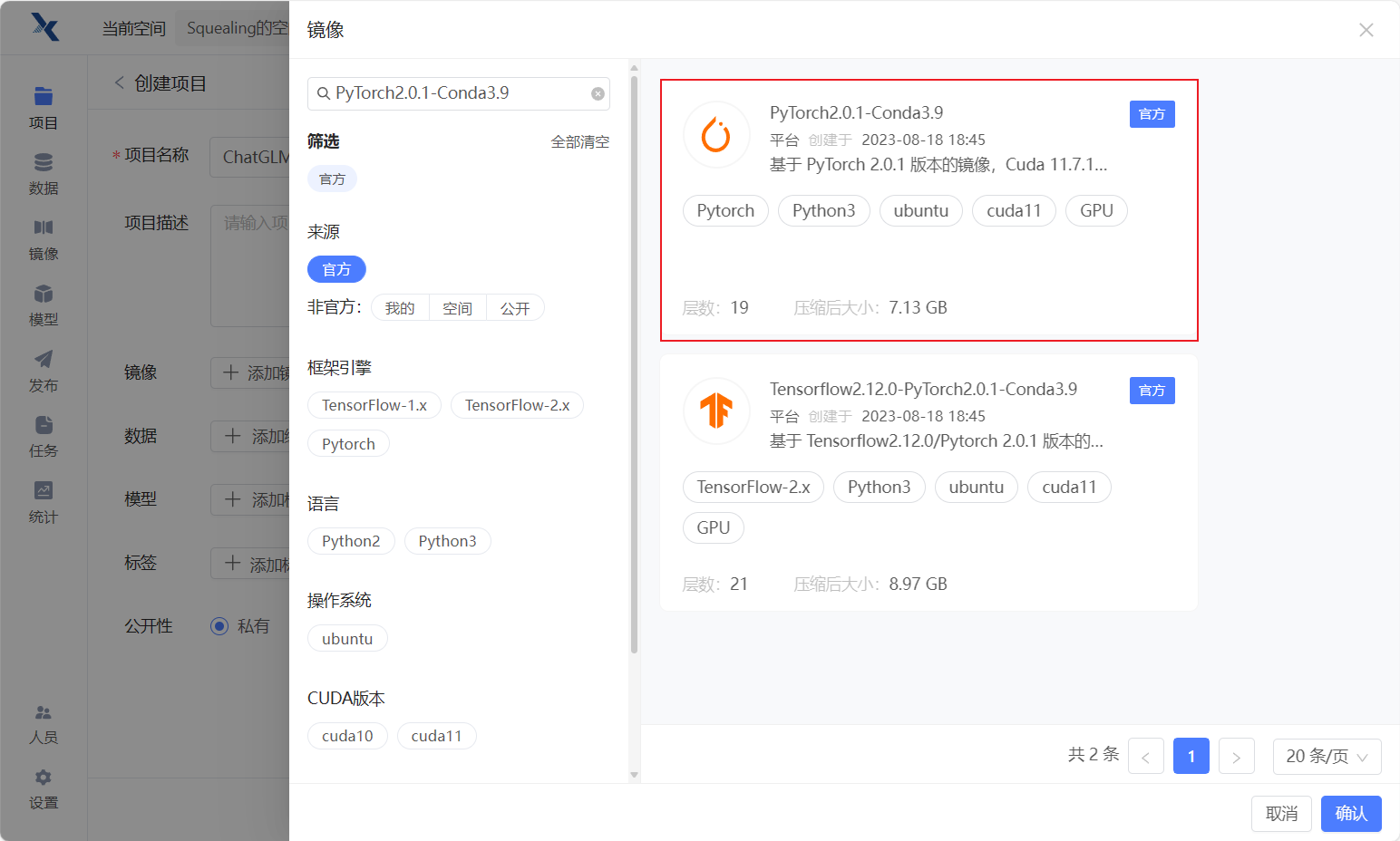
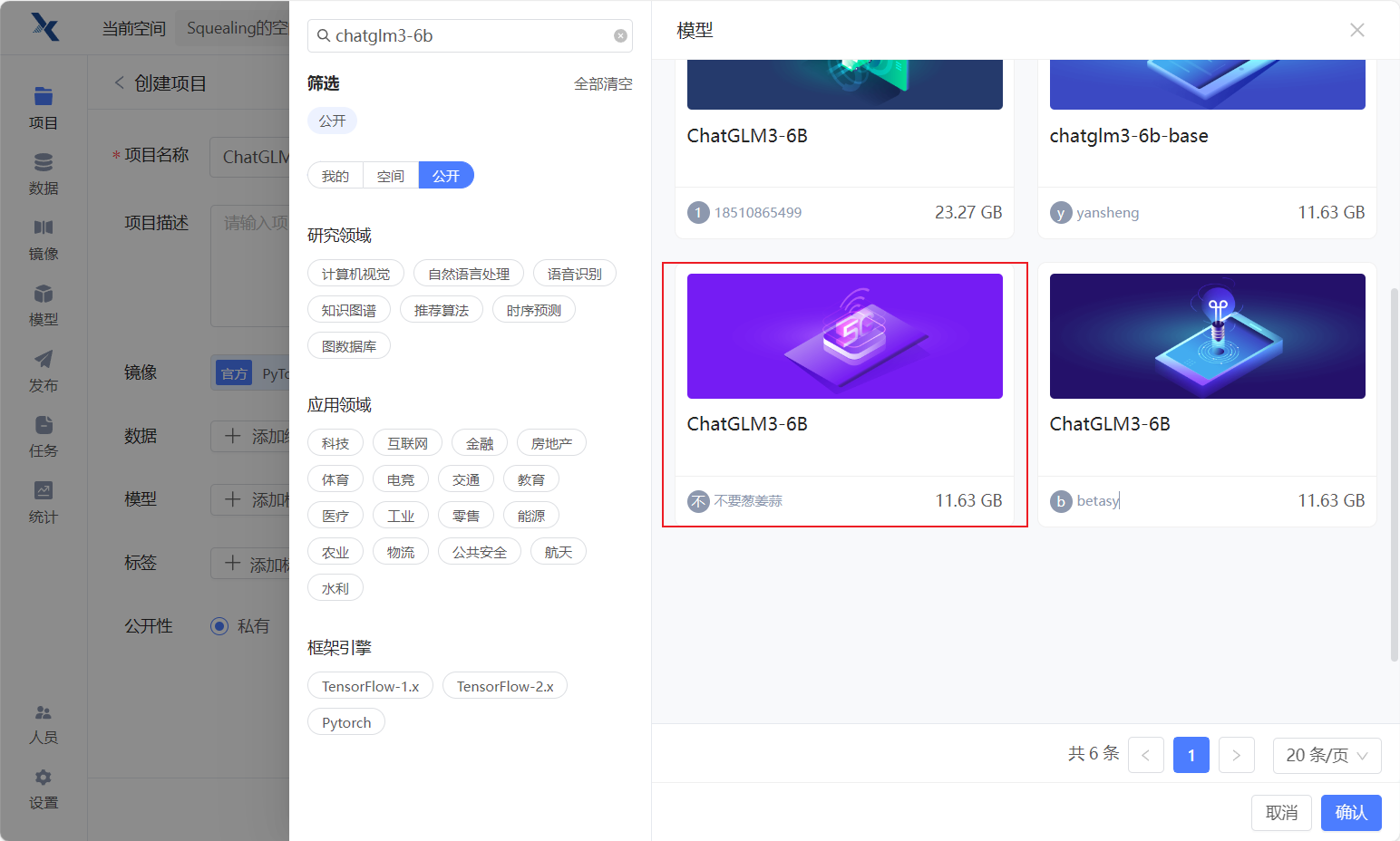
- 选择预训练模型,点击公开,搜索"chatglm3-6b",选择不要葱姜蒜上传的这个ChtaGLM3-6B模型。
- 都选完之后,点击右下角的创建
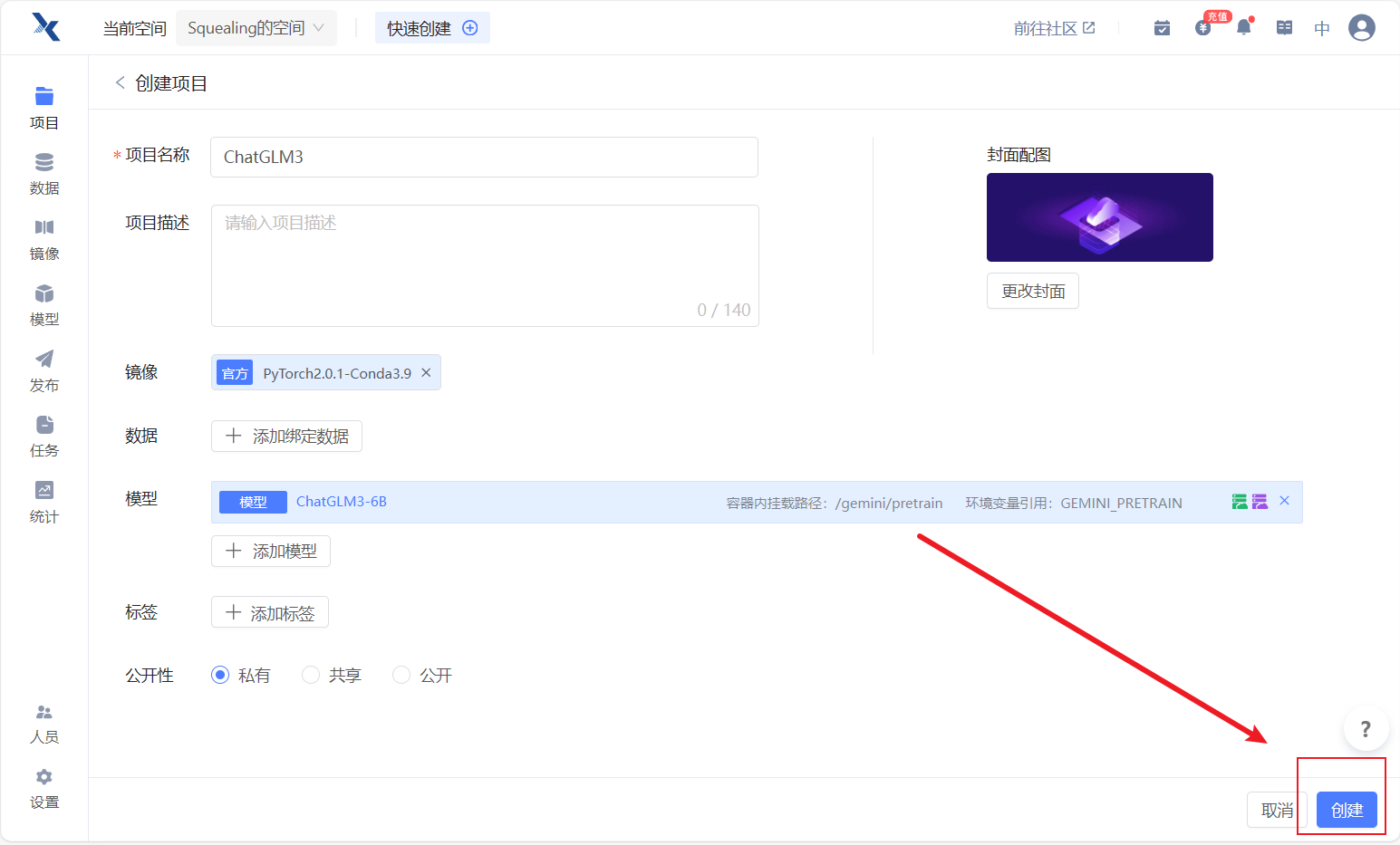
- 代码选择暂不上传。待会直接clone代码。
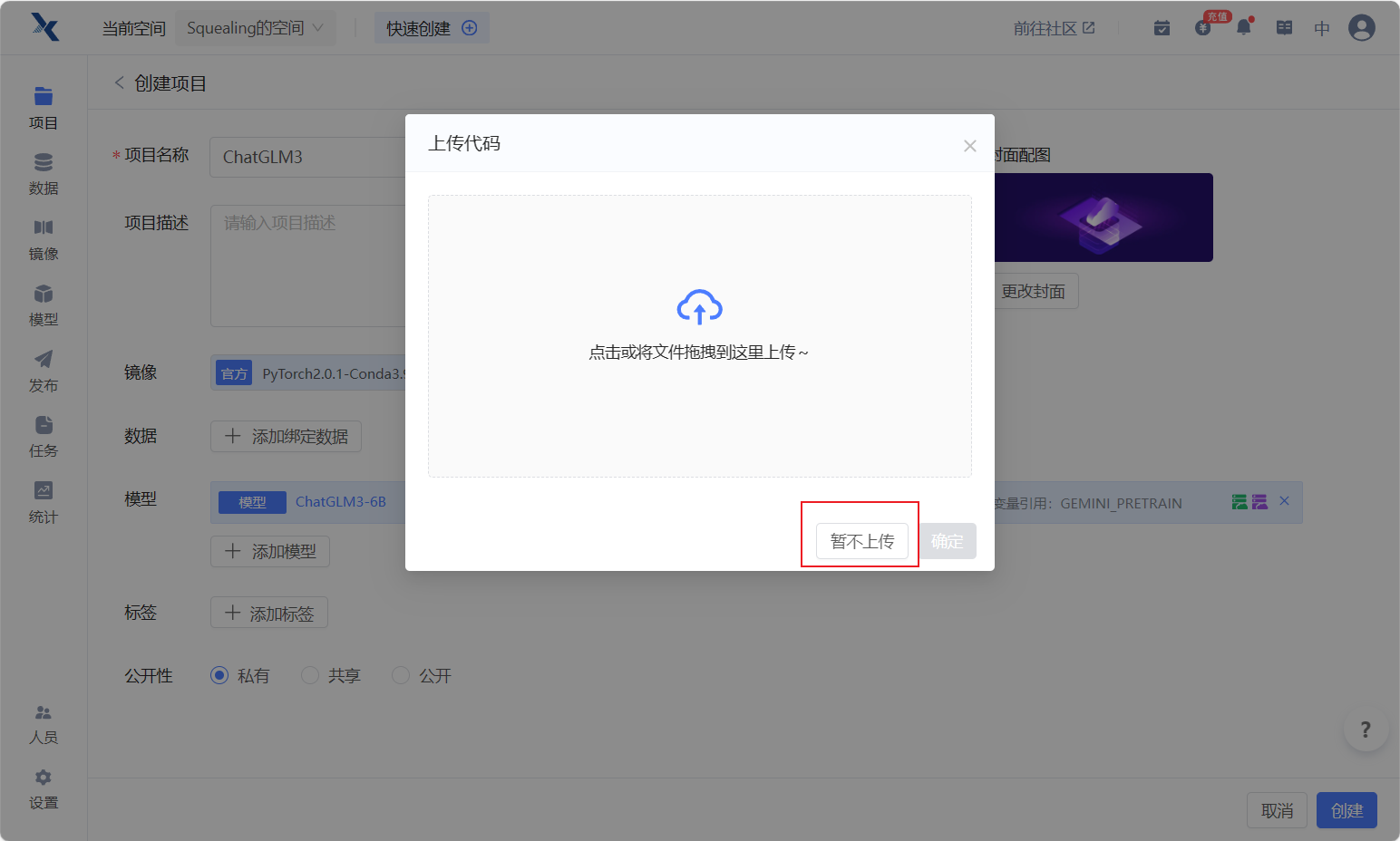
- 点击运行代码
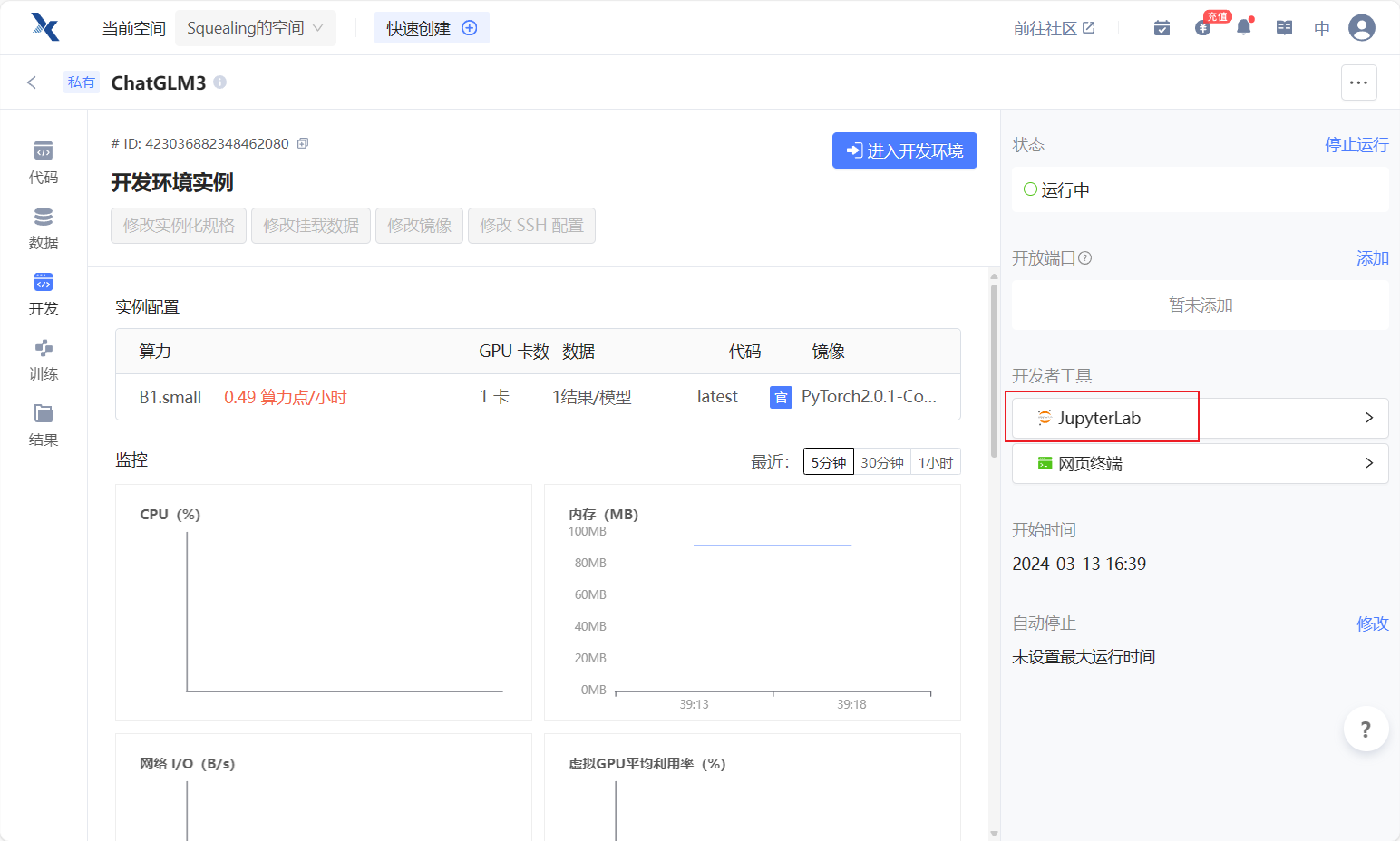
- 资源配置选择:B1.large, 24G的显存足够加载模型了。其他的不需要设置,然后点击右下角的开始运行。 注意:一定要B1.large,过低配置可能无法跑通
Step.2 配置环境
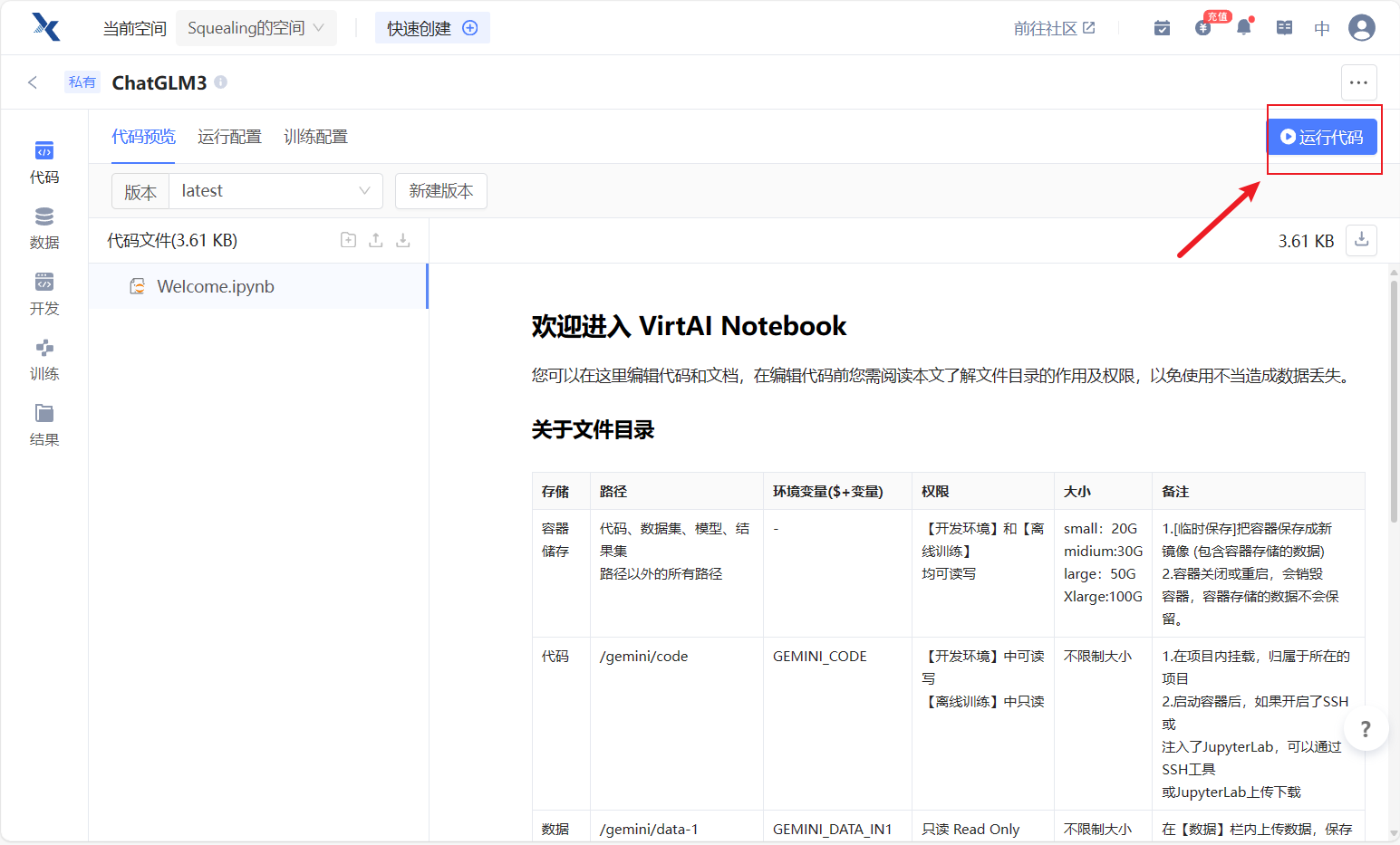
等右边两个工具全部加载完毕之后,再点击JupyterLab进入开发环境~
- 进入界面之后是这样的,然后点击这个小加号。
- 点击terminal,进入终端。
设置镜像源、克隆项目
- 升级apt,安装unzip
apt-get update && apt-get install unzip- 设置镜像源,升级pip
git config --global url."https://gitclone.com/".insteadOf https://
pip config set global.index-url https://pypi.virtaicloud.com/repository/pypi/simple
python3 -m pip install --upgrade pip- 克隆项目,并进入项目目录
git clone https://github.com/THUDM/ChatGLM3.git
cd ChatGLM3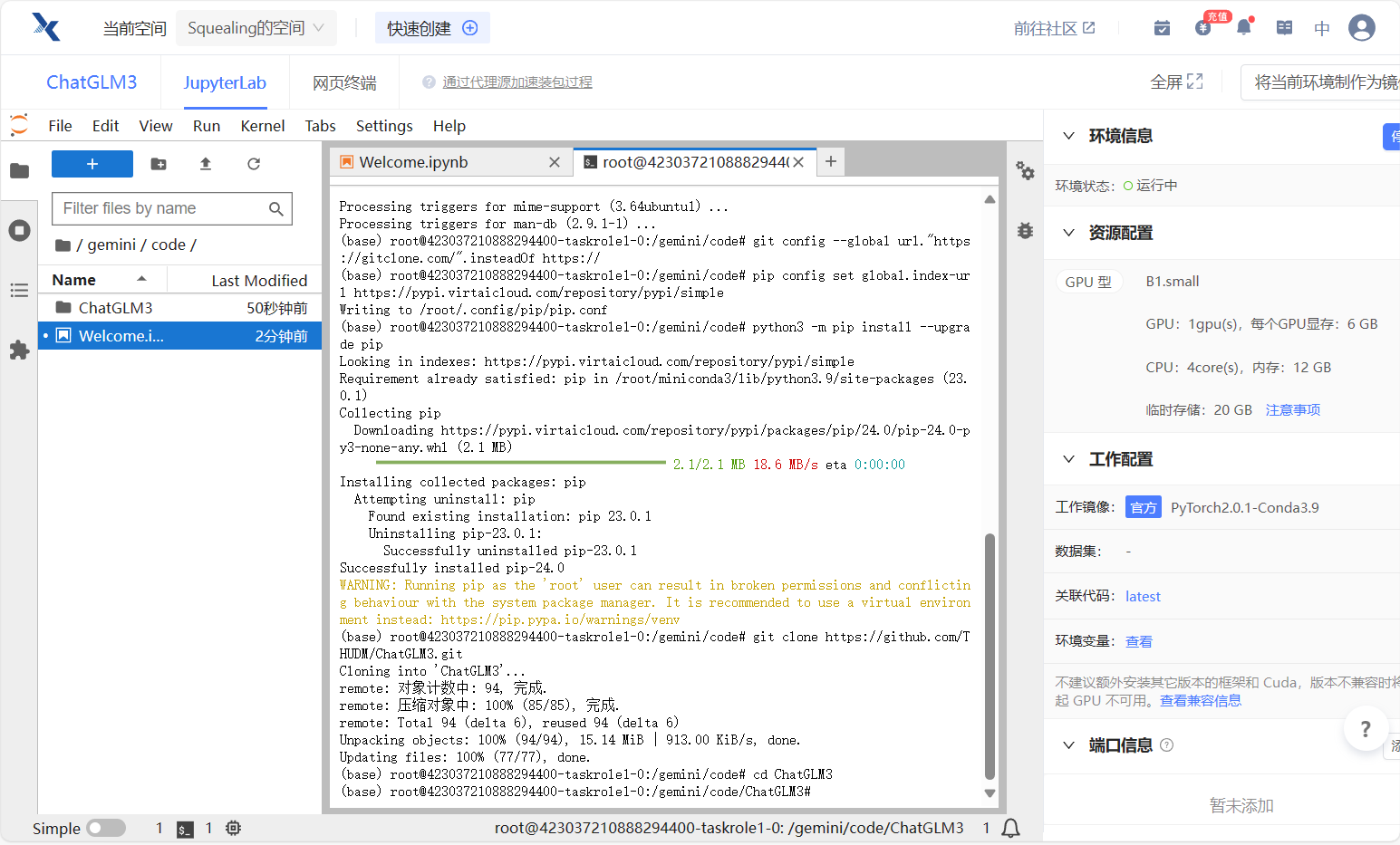
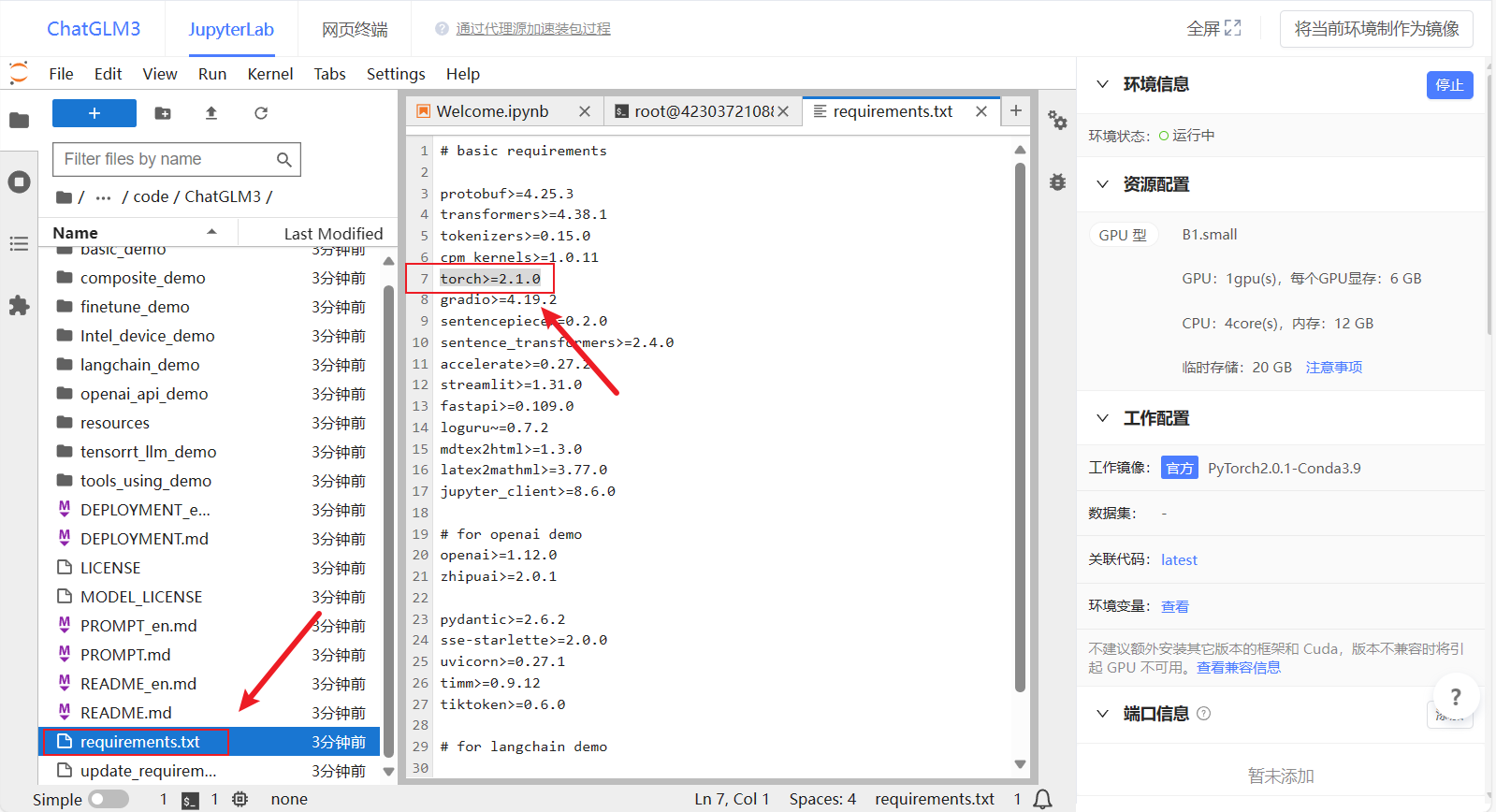
修改requirements
- 双击左侧的requirements.txt文件,把其中的torch删掉,因为我们的环境中已经有torch了,避免重复下载浪费时间【注意:删除之后要保存文件,可以使用快捷键Ctrl+S或者点击左上角的File,再点击保存】。
- 点击左上选项卡,重新返回终端,安装依赖,依赖安装完毕后还需要安装peft
pip install -r requirements.txt
pip install peft
Step.3 修改web_demo_gradio.py代码
1、修改模型目录
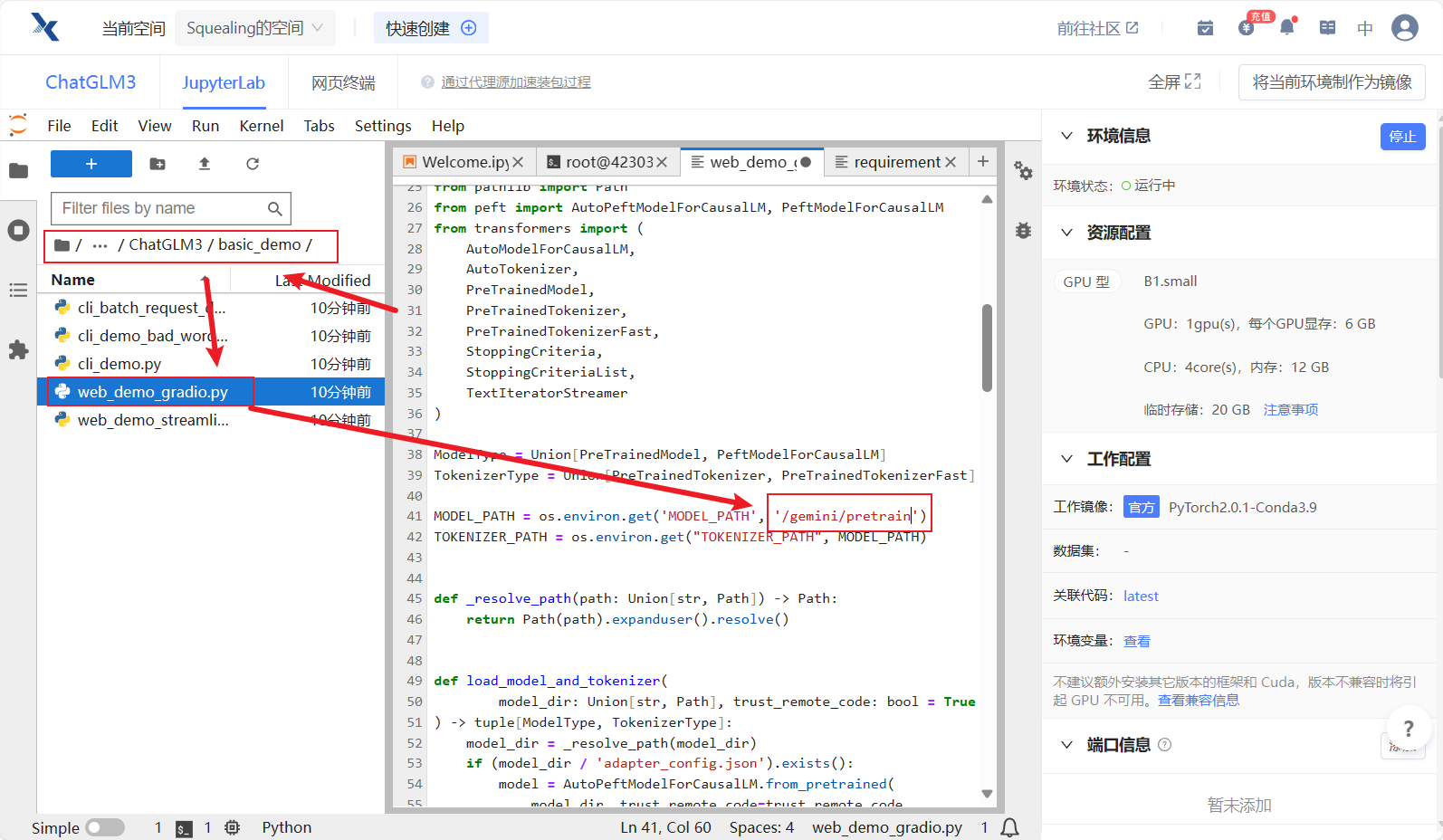
- 双击
basic_demo编辑web_demo_gradio.py,将加载模型的路径修改为:/gemini/pretrain,如下图所示~
2、修改启动代码
- 接下来还需要修改一段启动代码,将滚动条拉到最后一行,启动代码修改为如下~
demo.queue().launch(share=False, server_name="0.0.0.0",server_port=7000)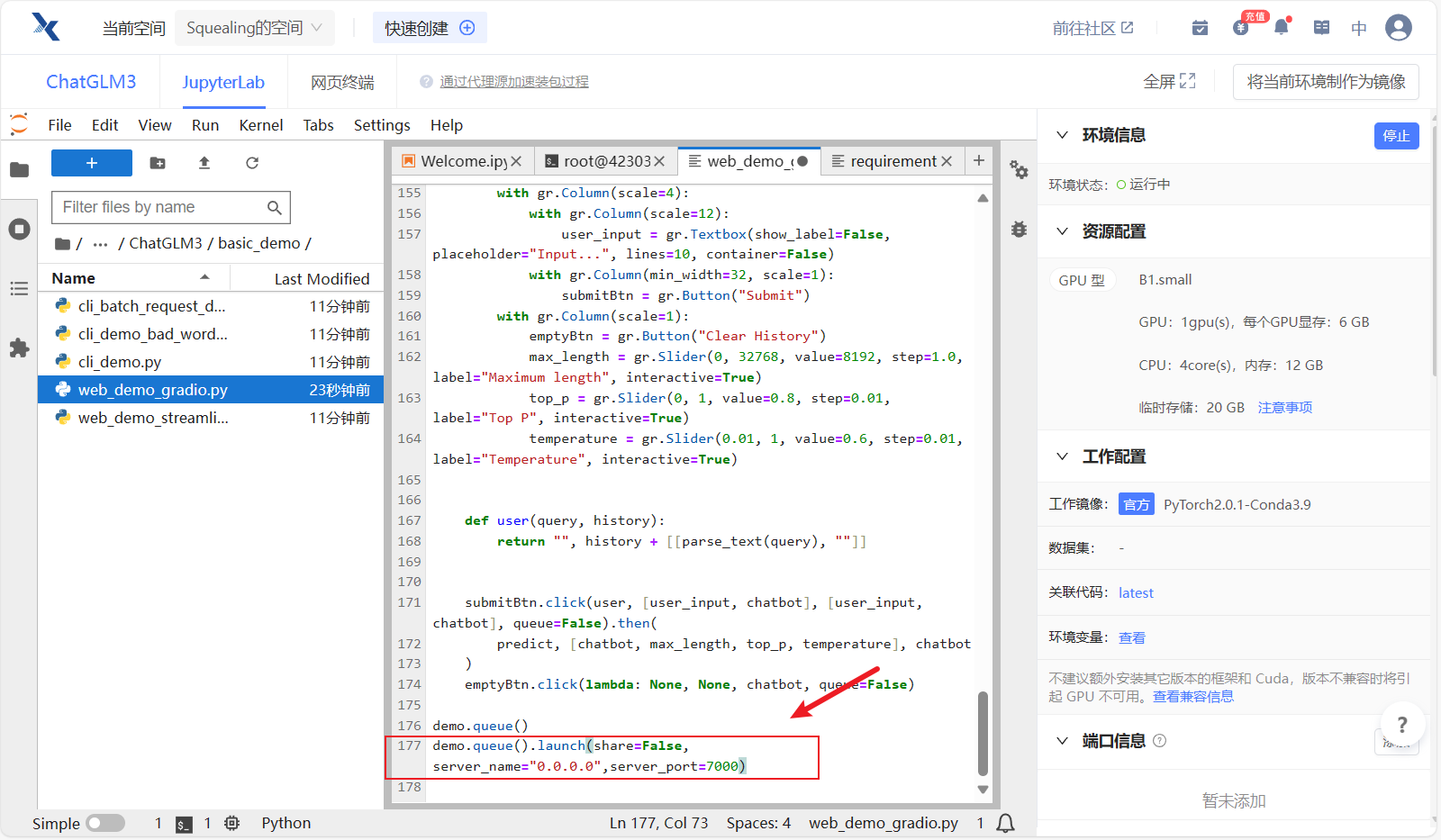
3、添加外部端口映射
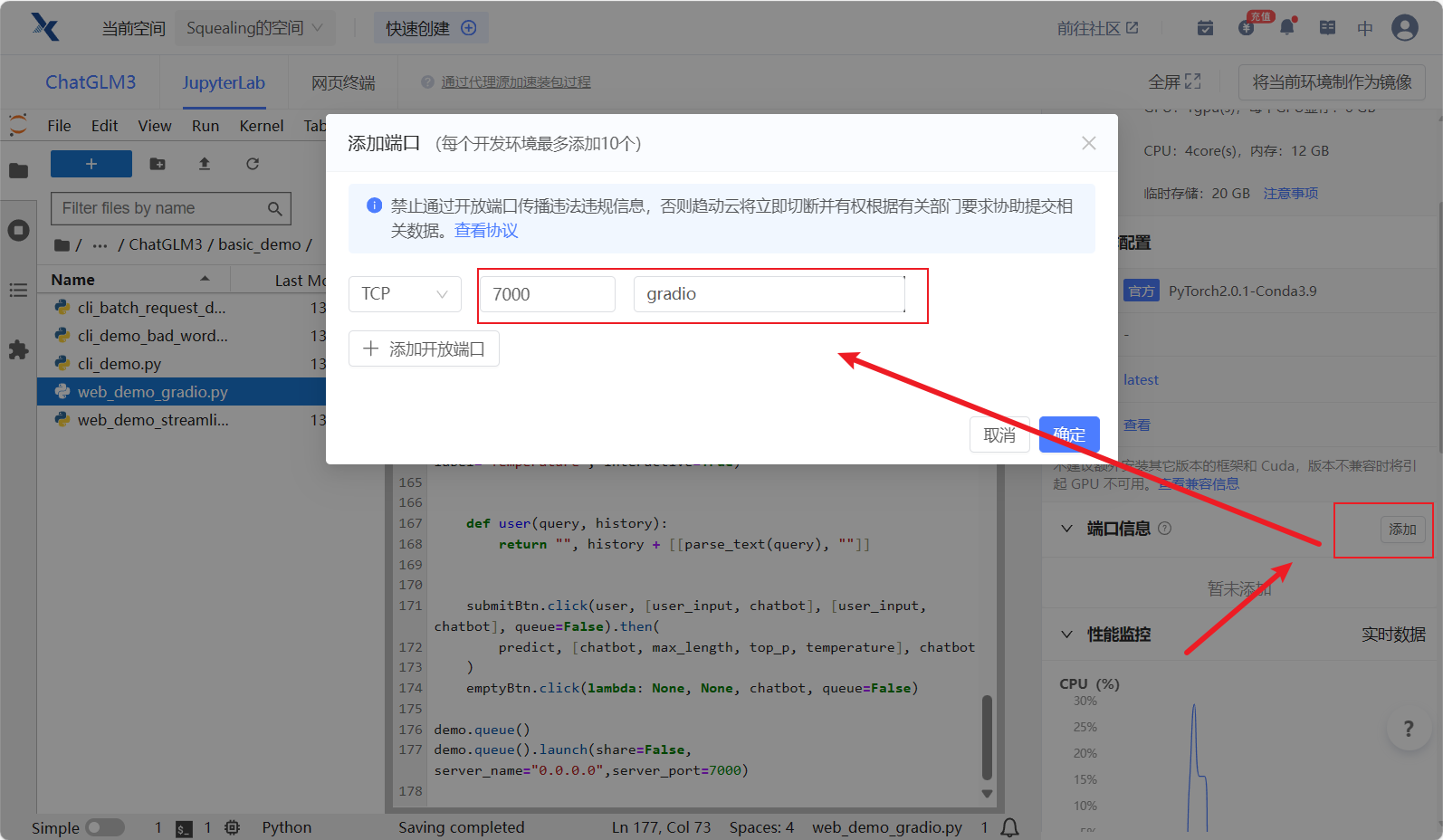
- 在界面的右边添加外部端口:7000
4、运行gradio界面
- 点击左上选项卡,重新返回终端,运行web_demo_gradio.py
cd basic_demo
python web_demo_gradio.py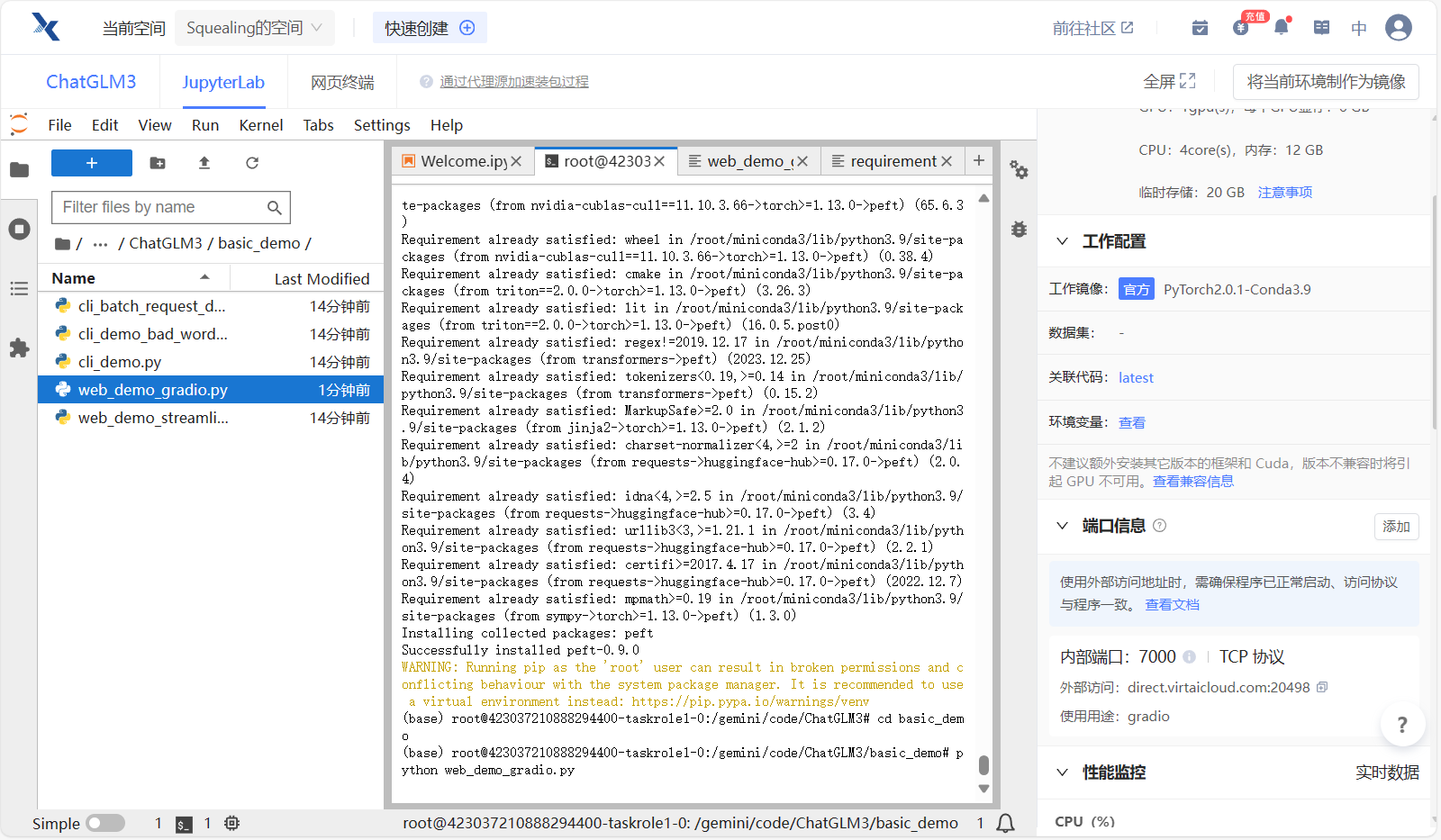
- 等待模型慢慢加载完毕,可能需要个五六分钟叭保持一点耐心 ~
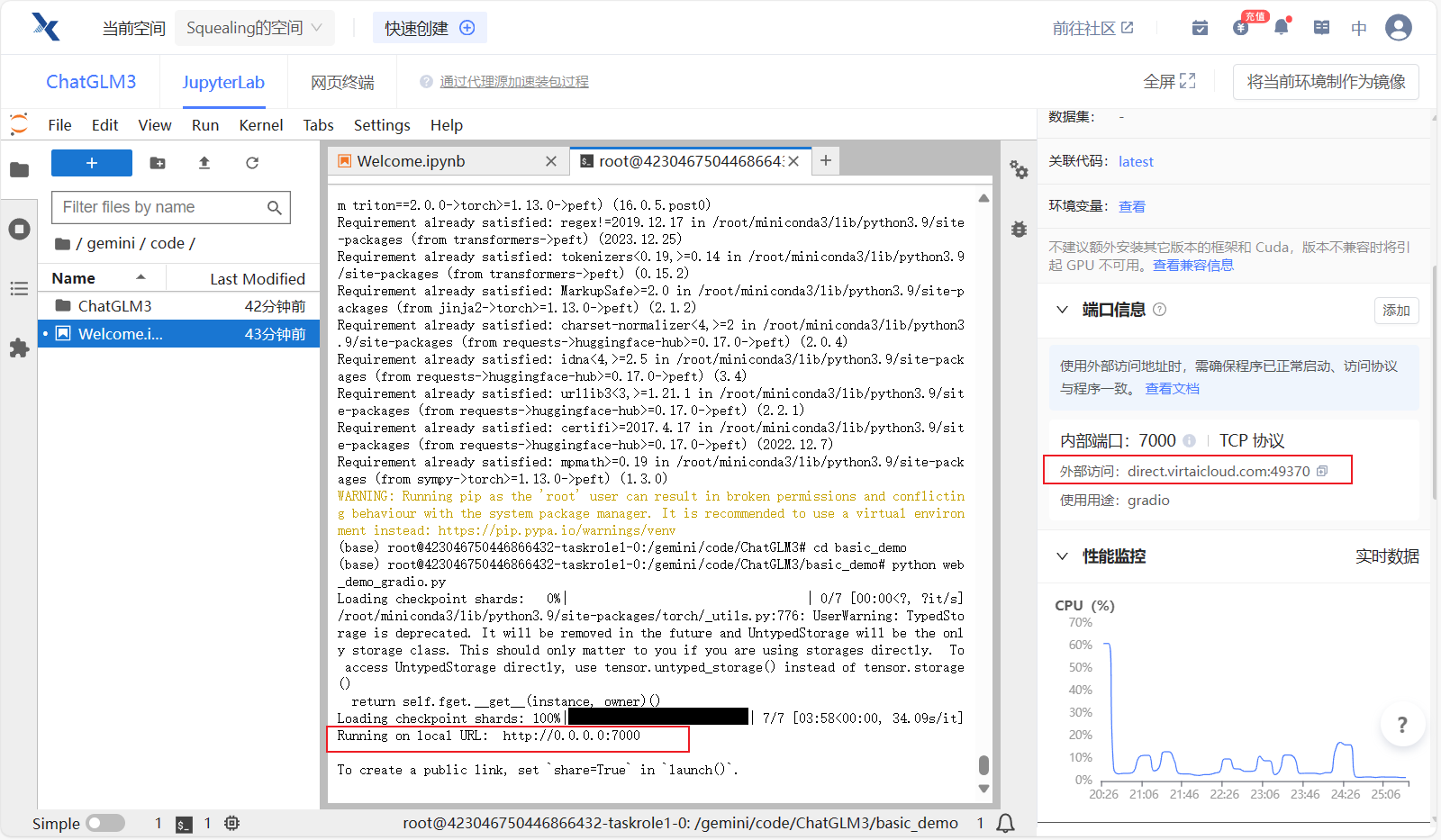
5、访问gradio页面
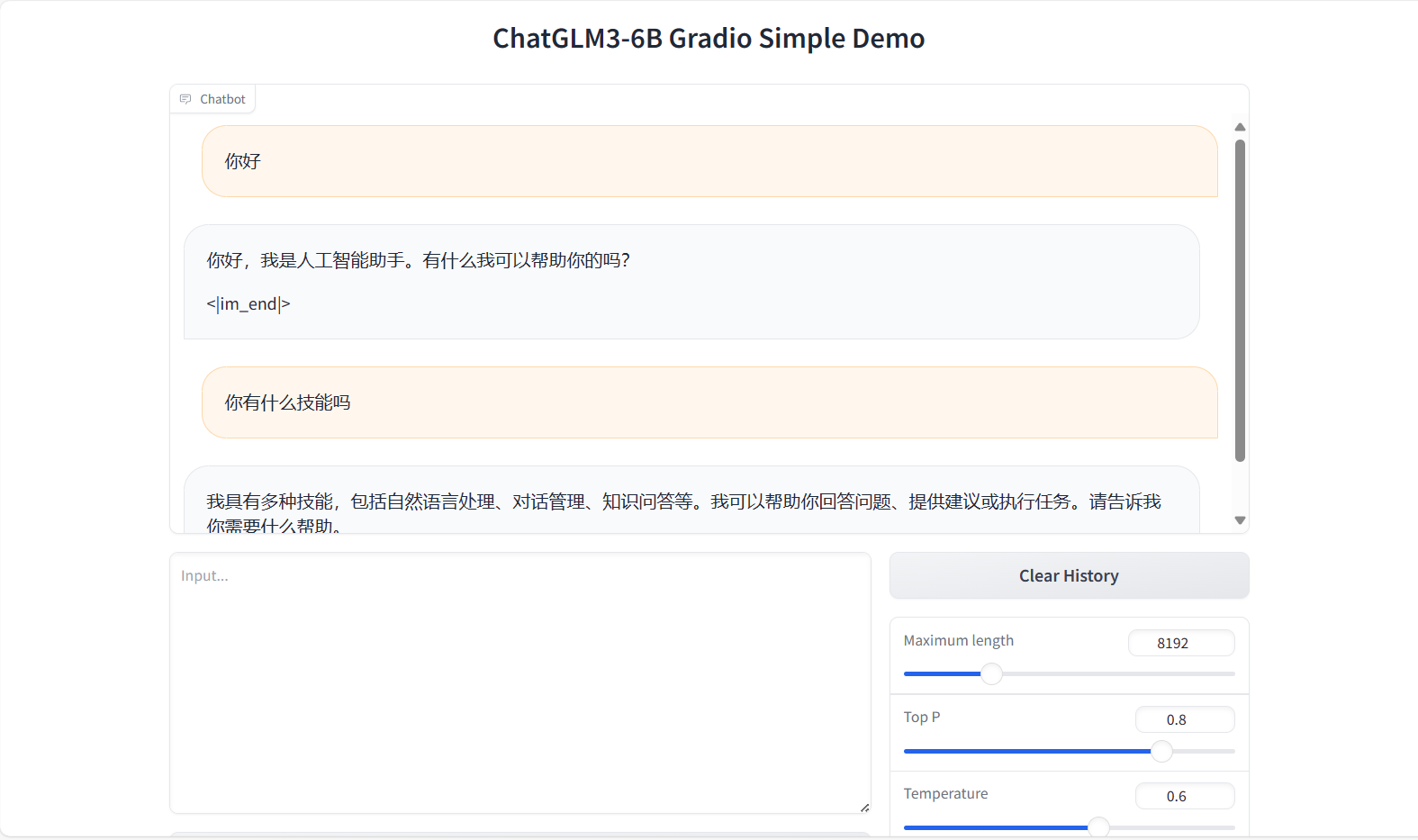
- 加载完毕之后,复制外部访问的连接,到浏览器打打开
Step.4 修改web_demo_streamlit.py代码
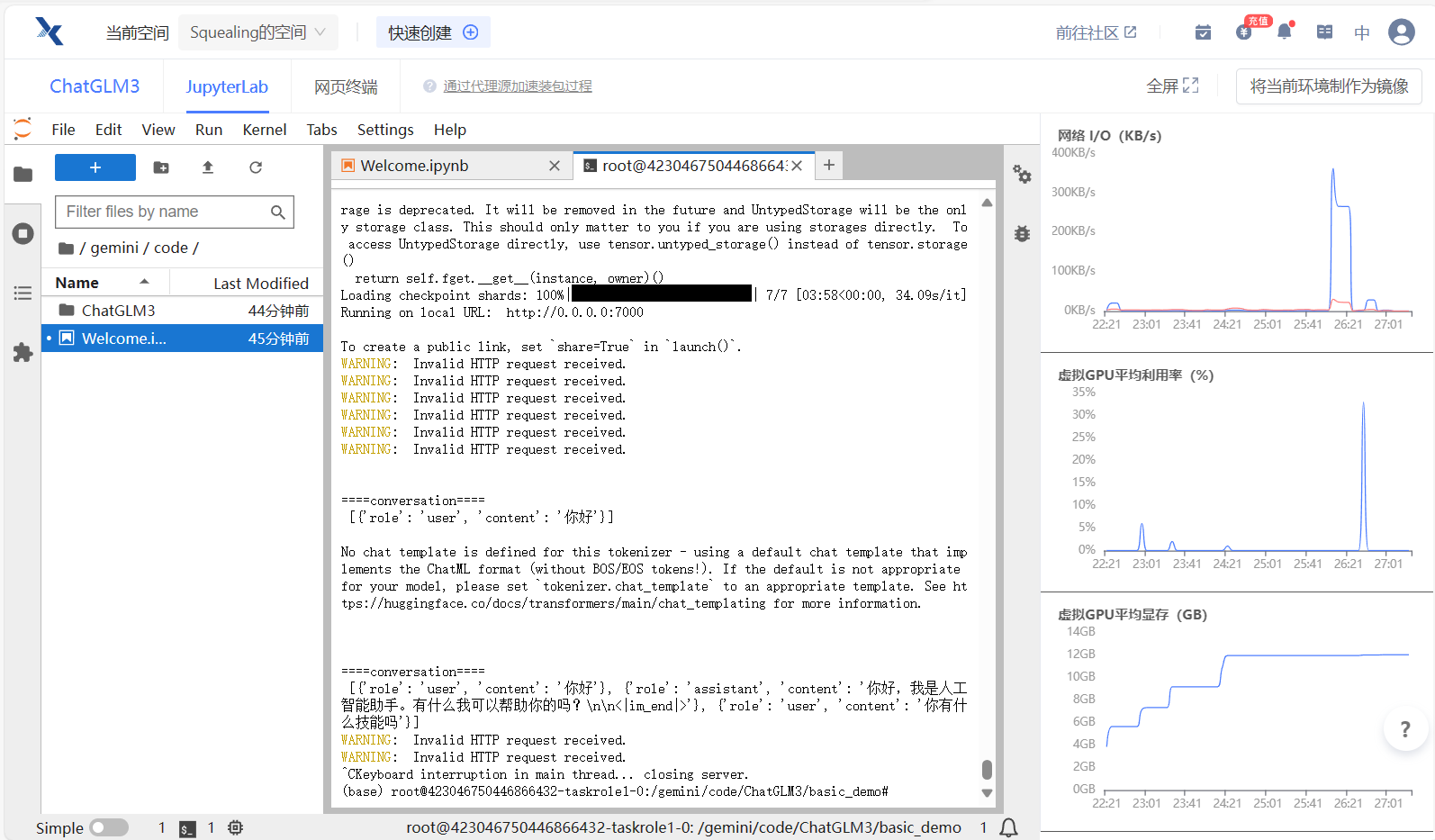
如果你运行了gradio,需要先杀掉这个进程,不然内存不够。
CTRL+C 可以杀掉进程~
杀掉进程之后,显存不会立刻释放,可以观察右边的GPU内存占用,查看显存释放情况。
退出进程后显存没有第一时间释放
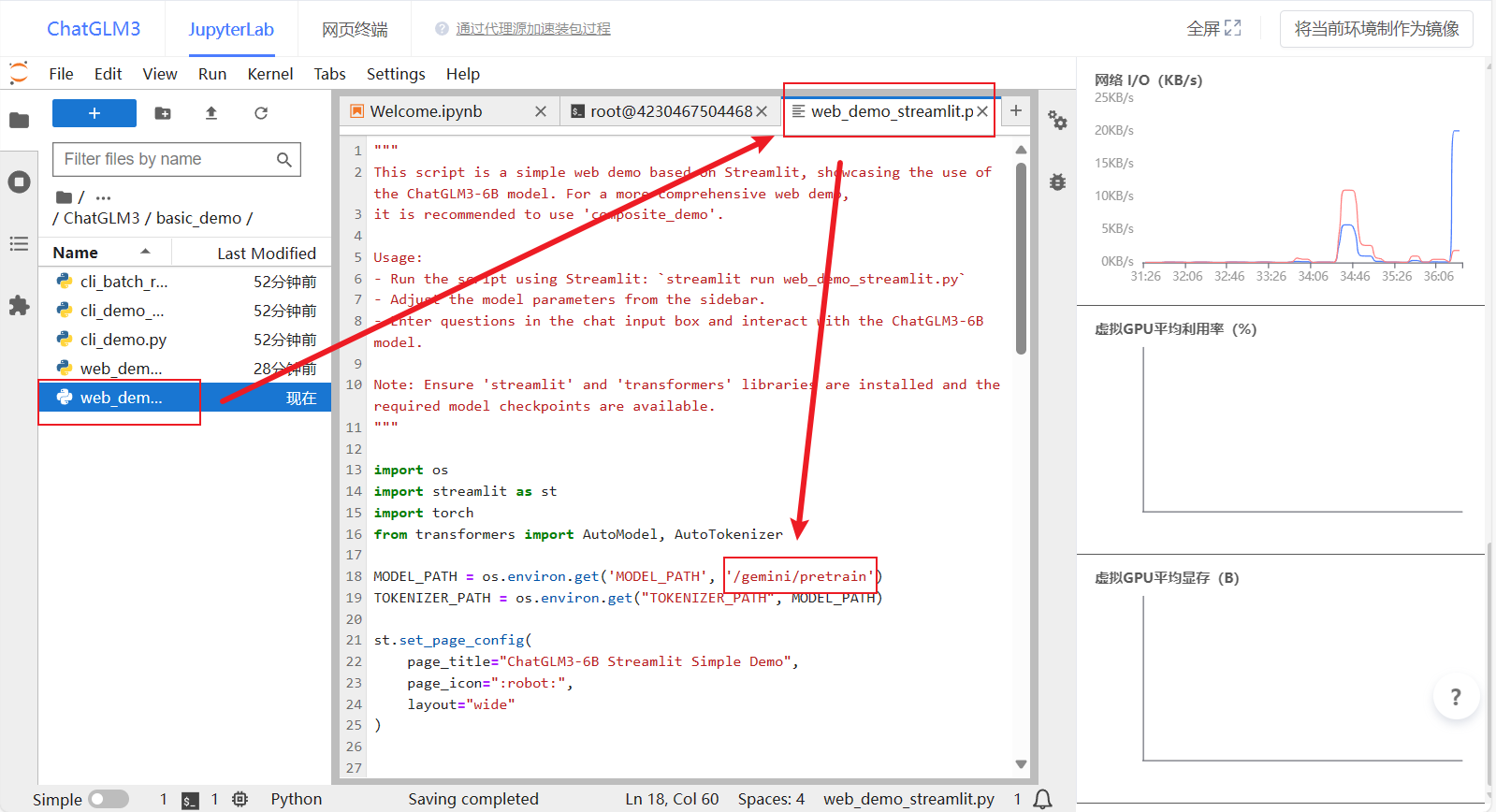
1、修改模型目录
- 双击
basic_demo编辑web_demo_streamlit.py,将加载模型的路径修改为:/gemini/pretrain,如下图所示~
提示:
web_demo_gradio.py是gradio界面的启动文件
web_demo_streamlit.py是Streamlit界面启动文件
2、运行streamlit界面
- 点击左上选项卡,重新返回终端,运行web_demo_stream.py并指定7000端口,这样就不用再次添加外部端口映射啦~
streamlit run web_demo_streamlit.py --server.port 7000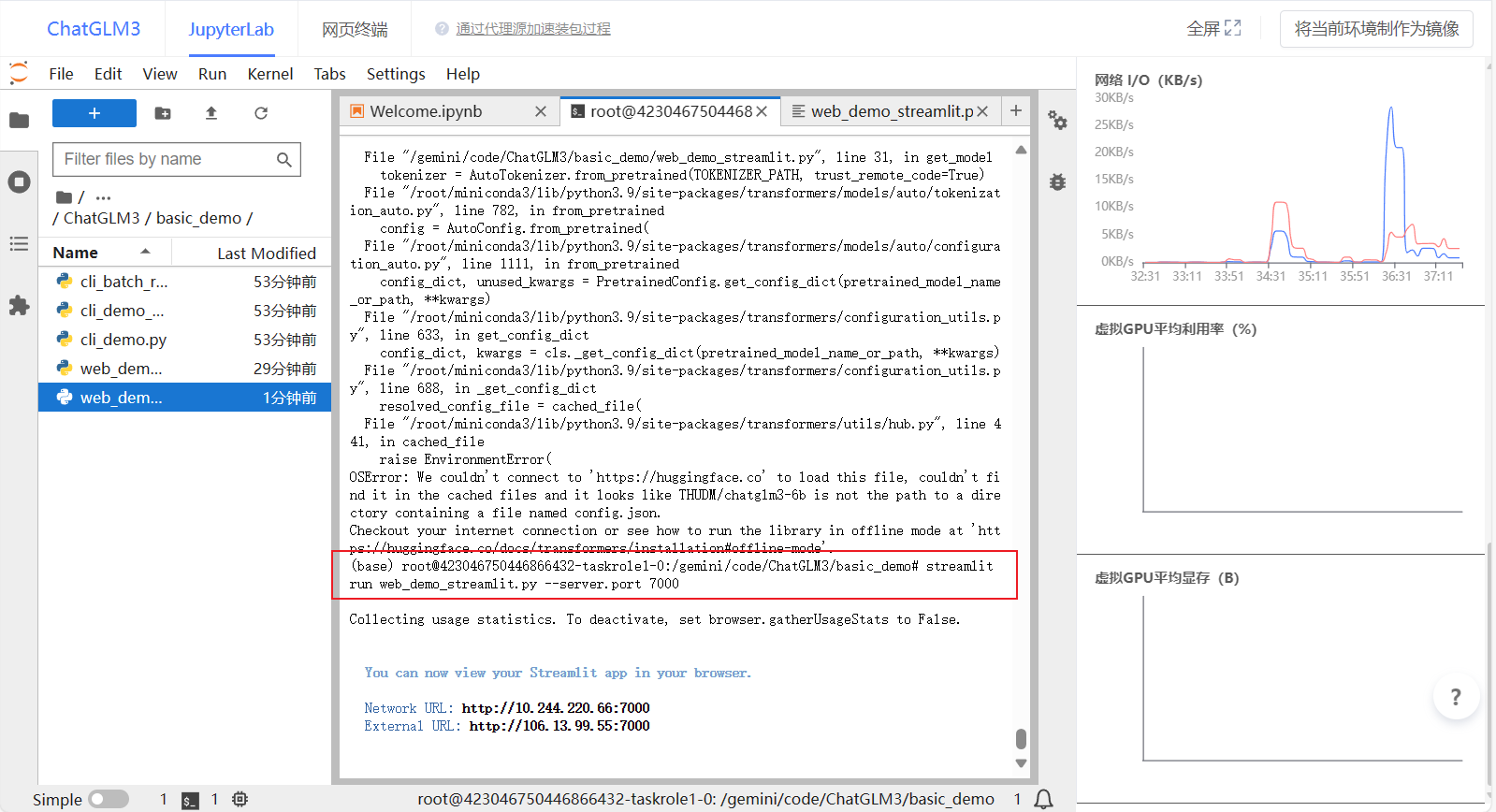
3、访问streamlit界面
- 复制外部访问地址到浏览器打开,之后模型才会开始加载。等待模型记载完毕~

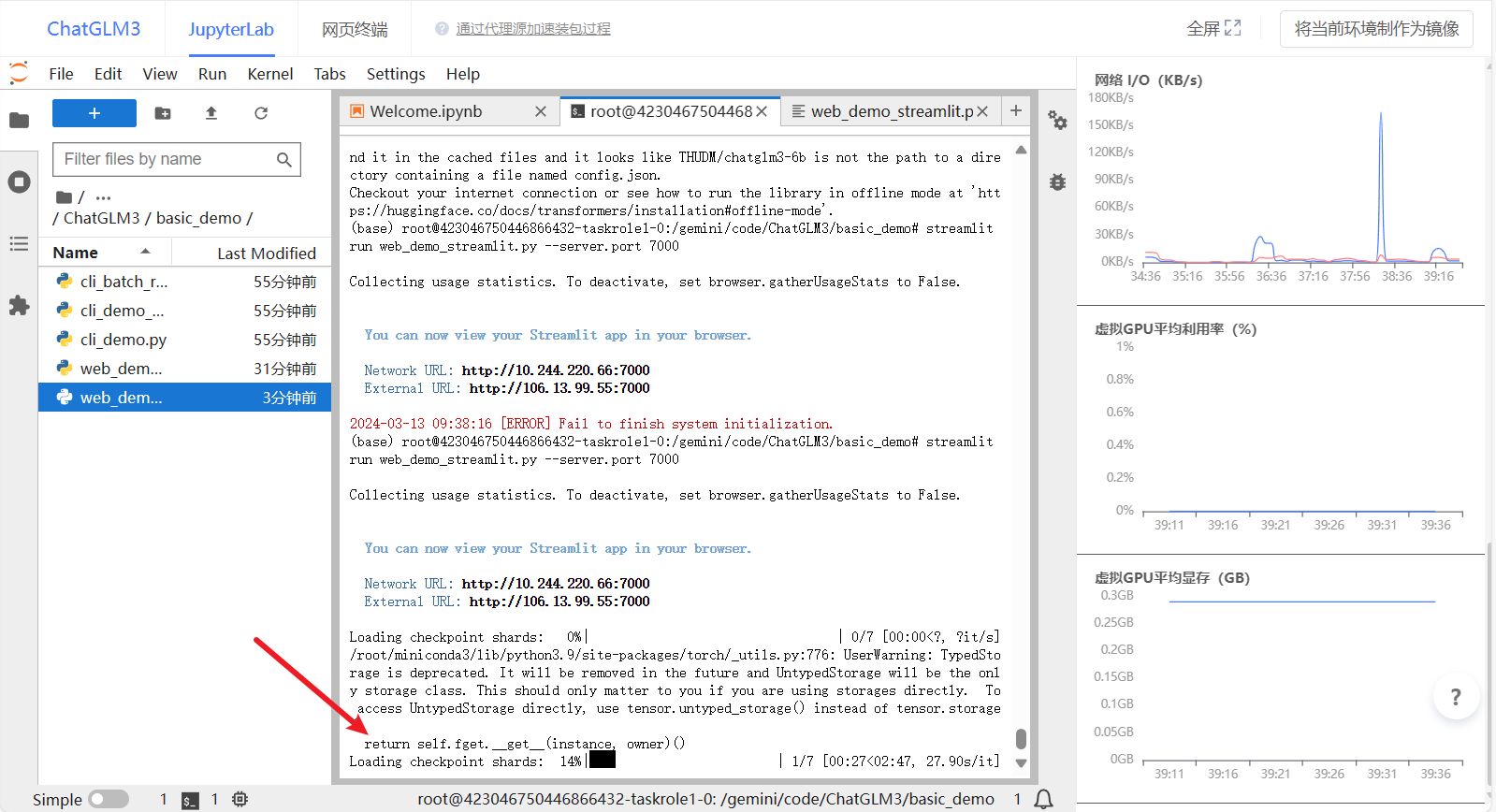
- 加载成功后工作台后端画面
Comments 1 条评论