开始前建议将课程代码下载下来,课程项目代码仓库:https://github.com/datawhalechina/hands-on-data-analysis
这门课程得主要目的是通过真实的数据,以实战的方式了解数据分析的流程和熟悉数据分析python的基本操作。知道了课程的目的之后,我们接下来我们要正式的开始数据分析的实战教学,完成kaggle上泰坦尼克的任务,实战数据分析全流程。
这里有两份资料:
教材《Python for Data Analysis》和 baidu.com &
google.com(善用搜索引擎)
第一章 第一节:数据载入及初步观察
1.1 载入数据
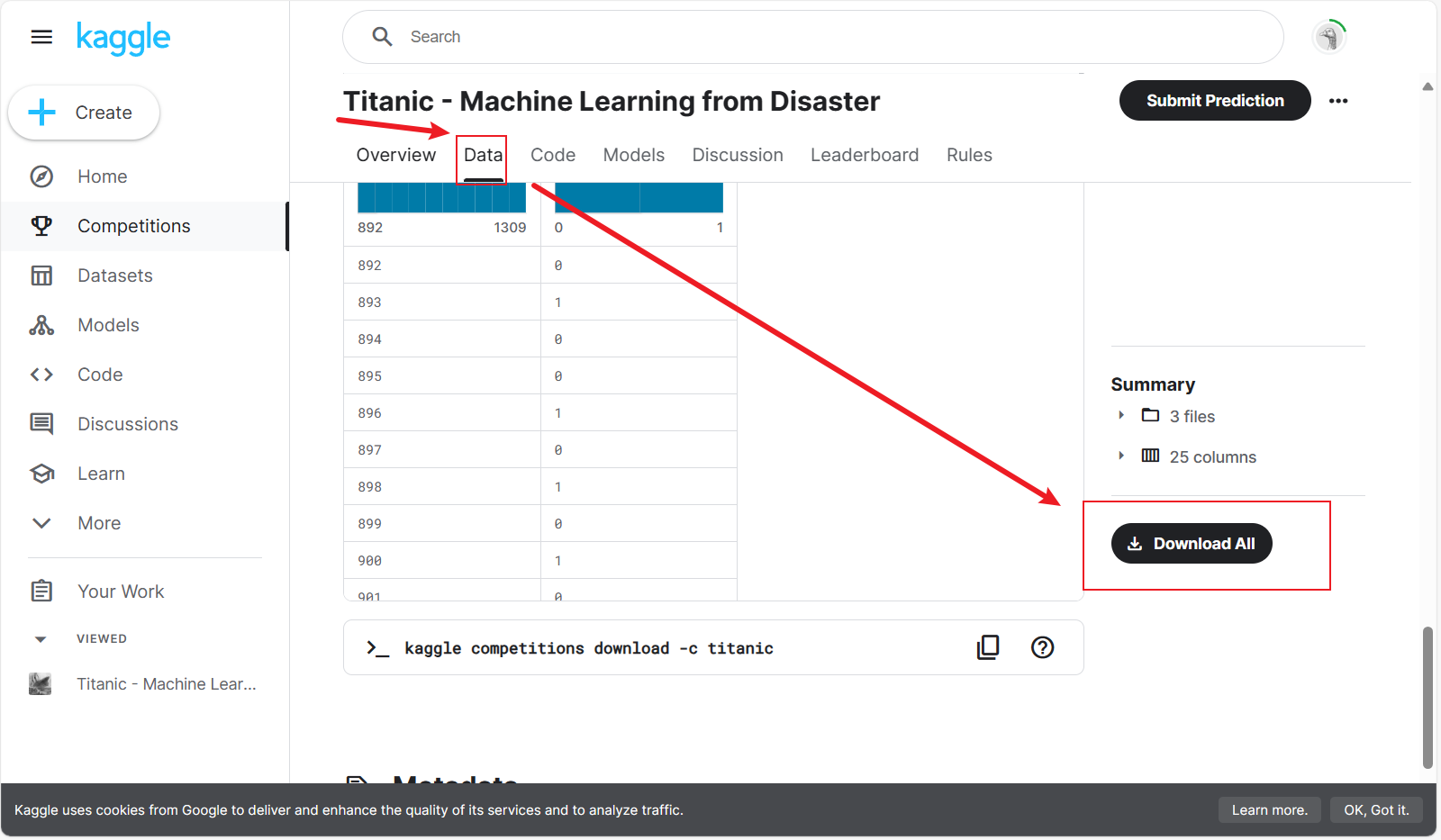
数据集下载 https://www.kaggle.com/c/titanic/overview
(可能需要工具连接)
选择"Data"栏,拉到最下面点击Download All""
下载的"titanic.zip"解压到项目目录下
1.1.1 任务一:导入numpy和pandas
简单介绍一下这两个工具库:
NumPy 是 Python 语言的一个扩展程序库,支持大量的维度数组与矩阵运算,以及数学函数库。
pandas是用于数据操纵和分析的Python软件库。它建造在NumPy基础上,并为操纵数值表格和时间序列,提供了数据结构和运算操作。
import numbers as nb
import pandas as pd1.1.2 任务二:载入数据
pandas读取csv文件的方法是read_csv(),具体参数可参考官方wiki
(1) 使用相对路径载入数据
df=pd.read_csv('./titanic/train.csv')
df.head()(2) 使用绝对路径载入数据
#这里使用你存放的绝对路径,我的只作演示
df=pd.read_csv('E:/VS clod_Data/hands-on-data-analysis/第一单元项目集合/titanic/train.csv')
df.head()#也可以使用os.path.abspath()获取当前路径
train_path=os.path.abspath('./titanic/train.csv')
print(train_path)
df=pd.read_csv(train_path)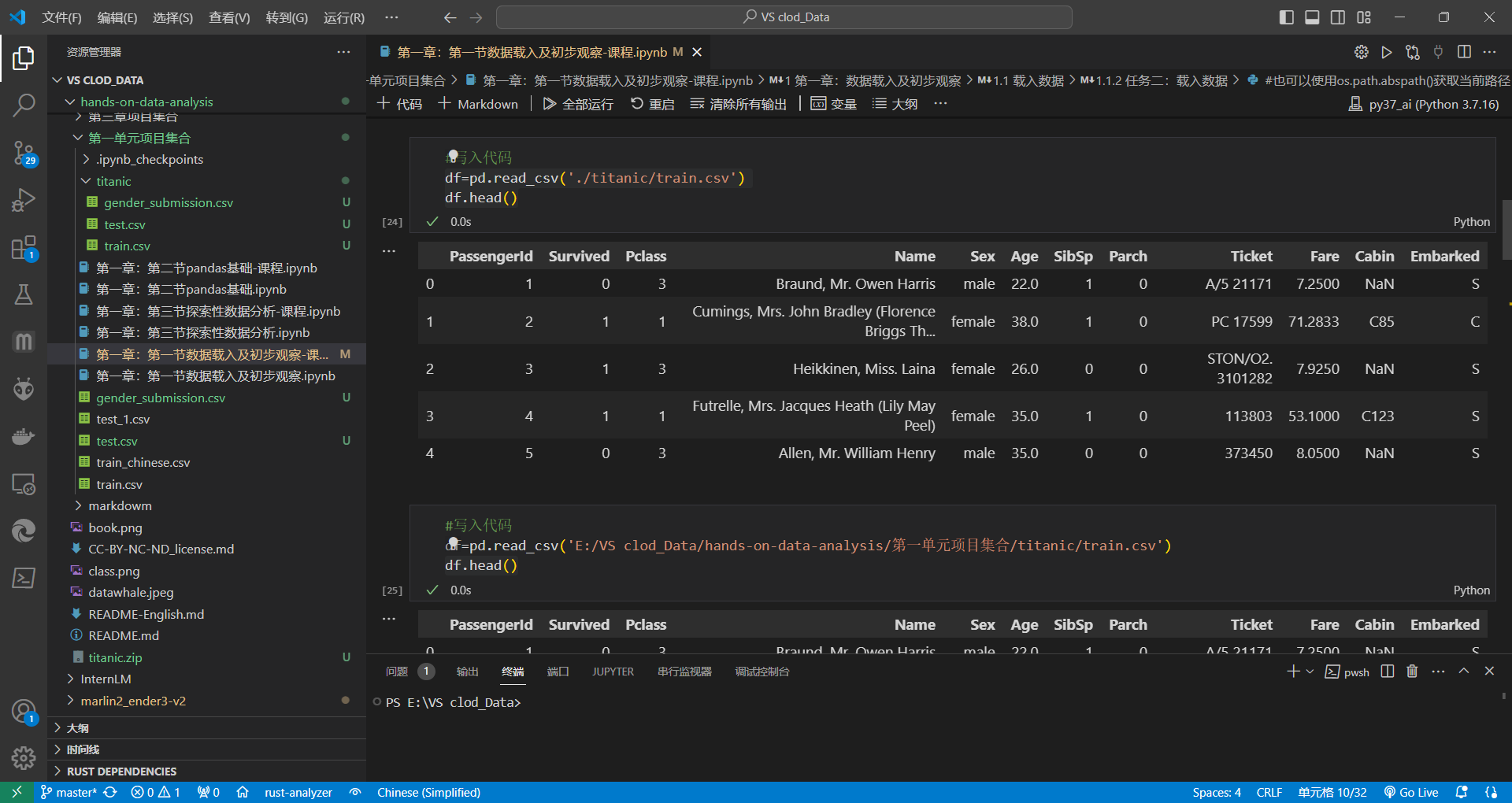
read_csv()和read_table()之间的区别
函数pd.read_csv()和pd.read_table()的内容相同,只是默认分隔符不同。
在read_csv()中,定界符为,,在read_table()中,定界符为\ t
1.1.3 任务三:每1000行为一个数据模块,逐块读取
这里我们需要在read_csv()添加一个参数chunksize,具体说明如下(官方wiki机翻):
chunksize int, 可选
每个块要从文件中读取的行数。传递一个值将导致 函数返回一个对象进行迭代。 有关 和 的更多信息,请参阅 IO 工具文档。
TextFileReader``iterator``chunksize
df=pd.read_csv('./titanic/train.csv',chunksize=1000)需要注意,使用了chunksize参数后,返回的是一个迭代器TextFileReader,而不是之前不加参数的表格型数据结构DataFrame(具体结构可看这篇文章),我们可以使用type()查看
type(pd.read_csv('./titanic/train.csv'))type(pd.read_csv('./titanic/train.csv',chunksize=1000))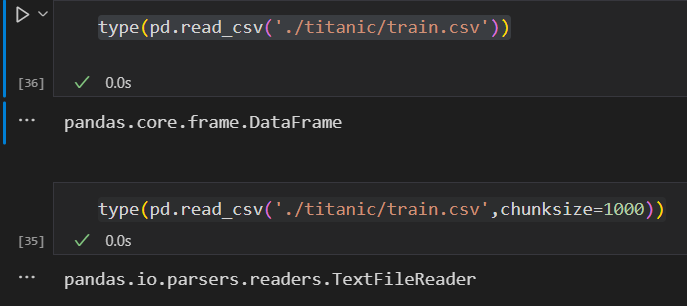
所有,使用块读取之后不能使用像之前直接head()查看了,但可以使用get_chunk()查看
df.get_chunk()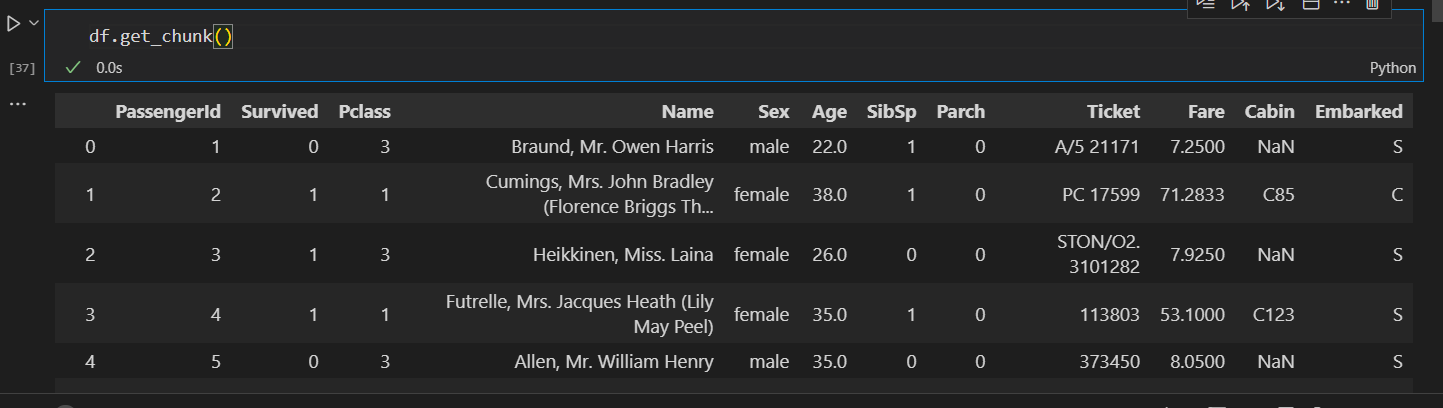
【思考】什么是逐块读取?为什么要逐块读取呢?
【回答】
日常数据分析工作中,难免碰到数据量特别大的情况,动不动就2、3千万行,如果直接读进 Python 内存中,非常占用内存,且读取和处理过程很慢
采用逐块读取文件的主要目的是防止文件过大,一次性加载到内存,会让内存爆掉,或者内存一次性无法加载这么多。此时就需要使用pandas逐块读取文件,并且逐块读取之后就可以将文件处理之后直接读出。这样就可以大大的节省内存空间的使用。
1.1.4 任务四:将表头改成中文,索引改为乘客ID
[对于某些英文资料,我们可以通过翻译来更直观的熟悉我们的数据]
PassengerId => 乘客ID
Survived => 是否幸存
Pclass => 乘客等级(1/2/3等舱位)
Name => 乘客姓名
Sex => 性别
Age => 年龄
SibSp => 堂兄弟/妹个数
Parch => 父母与小孩个数
Ticket => 船票信息
Fare => 票价
Cabin => 客舱
Embarked => 登船港口
#方法1:重命名列名
df=pd.read_csv('./titanic/train.csv')
df.columns=['乘客ID','是否幸存','乘客等级(1/2/3等舱位)','乘客姓名','性别','年龄','堂兄弟/妹个数','父母与小孩个数','船票信息','票价','客舱','登船港口']
dfnames Hashable 序列,可选
要应用的列标签的顺序。如果文件包含标题行, 然后,您应该显式传递以覆盖列名。 此列表中不允许重复。
header=0
#方法2:读取csv文件时,重命名列名
df=pd.read_csv('./titanic/train.csv',names=['乘客ID','是否幸存','乘客等级(1/2/3等舱位)','乘客姓名','性别','年龄','堂兄弟/妹个数','父母与小孩个数','船票信息','票价','客舱','登船港口'])
df两个方法区别:
方法1是将原有表头重命名,方法2相当于又添加了一行表头
1.2 初步观察
导入数据后,你可能要对数据的整体结构和样例进行概览,比如说,数据大小、有多少列,各列都是什么格式的,是否包含null等
df.info() # 打印摘要
df.describe() # 描述性统计信息
df.values # 数据 <ndarray>
df.to_numpy() # 数据 <ndarray> (推荐)
df.shape # 形状 (行数, 列数)
df.columns # 列标签 <Index>
df.columns.values # 列标签 <ndarray>
df.index # 行标签 <Index>
df.index.values # 行标签 <ndarray>
df.head(n) # 前n行
df.tail(n) # 尾n行
pd.options.display.max_columns=n # 最多显示n列
pd.options.display.max_rows=n # 最多显示n行
df.memory_usage() # 占用内存(字节B)1.2.2 任务二:观察表格前10行的数据和后15行的数据
df.head(10)df.tail(10)1.2.4 任务三:判断数据是否为空,为空的地方返回True,其余地方返回False
df.isnull().head()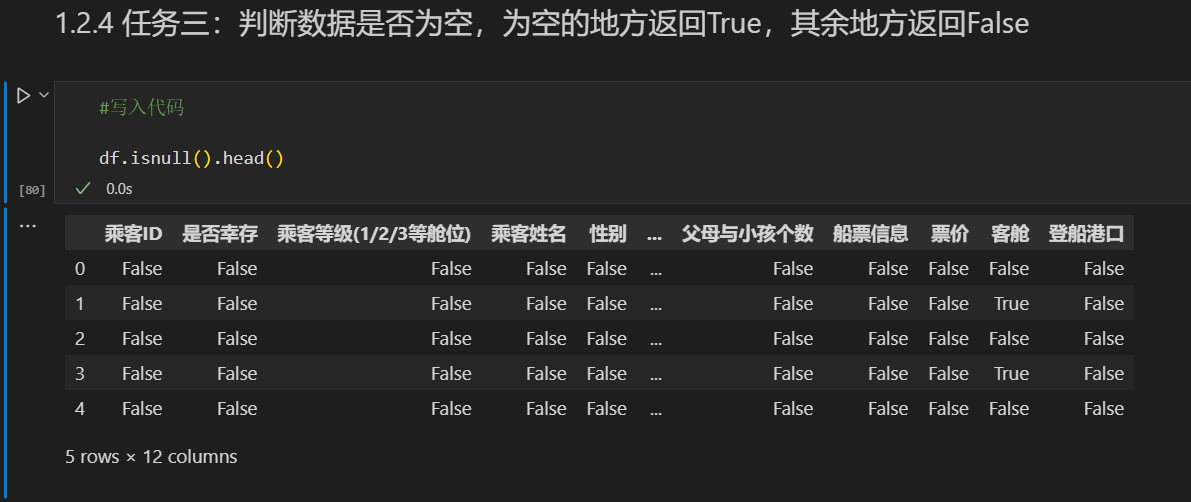
1.3 保存数据
1.3.1 任务一:将你加载并做出改变的数据,在工作目录下保存为一个新文件train_chinese.csv
df.to_csv('train_chinese.csv',encoding='utf-8',index=False)第一章 第二节:数据载入及初步观察
1.4 知道你的数据叫什么
我们学习pandas的基础操作,那么上一节通过pandas加载之后的数据,其数据类型是什么呢?
开始前导入numpy和pandas
import numpy as np
import pandas as pd1.4.1 任务一:pandas中有两个数据类型DateFrame和Series,通过查找简单了解他们。然后自己写一个关于这两个数据类型的小例子🌰[开放题]
Series
Series 是带标签的一维数组,可存储整数、浮点数、字符串、Python 对象等类型的数据。轴标签统称为索引。
调用 pd.Series 函数即可创建 Series:
s = pd.Series(np.random.randn(5), index=['a', 'b', 'c', 'd', 'e'])
s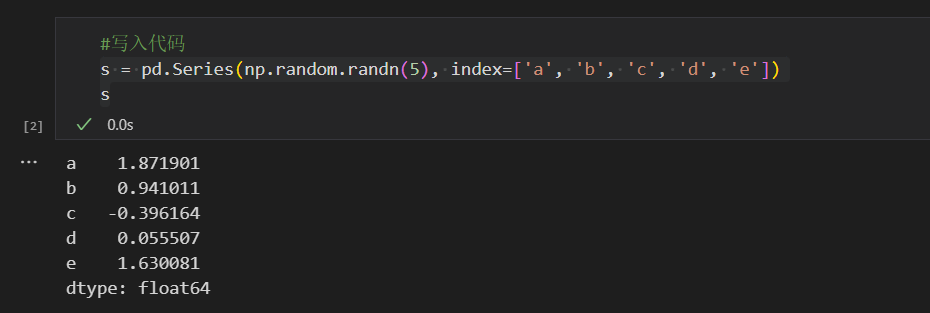
也可以使用字典生成
s=pd.Series({'a':1,'b':2,'c':3,'d':4})
s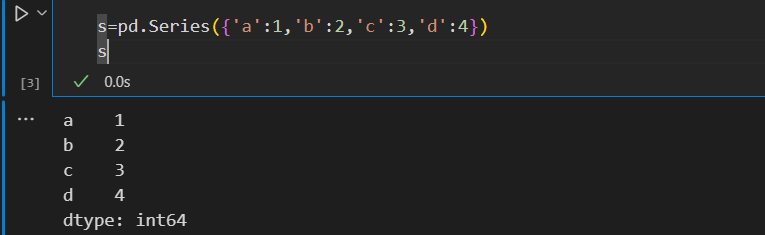
DataFrame
DataFrame 是由多种类型的列构成的二维标签数据结构,类似于 Excel 、SQL 表,或 Series 对象构成的字典。DataFrame 是最常用的 Pandas 对象,与 Series 一样,DataFrame 支持多种类型的输入数据:
- 一维 ndarray、列表、字典、Series 字典
- 二维 numpy.ndarray
- 结构多维数组或记录多维数组
SeriesDataFrame
除了数据,还可以有选择地传递 index(行标签)和 columns(列标签)参数。传递了索引或列,就可以确保生成的 DataFrame 里包含索引或列。Series 字典加上指定索引时,会丢弃与传递的索引不匹配的所有数据。
用 Series 字典或字典生成 DataFrame
生成的索引是每个 Series 索引的并集。先把嵌套字典转换为 Series。如果没有指定列,DataFrame 的列就是字典键的有序列表。
d = {'one': pd.Series([1., 2., 3.], index=['a', 'b', 'c']),'two': pd.Series([1., 2., 3., 4.], index=['a', 'b', 'c', 'd'])}
df = pd.DataFrame(d)
df
1.4.2 任务二:根据上节课的方法载入"train.csv"文件
df=pd.read_csv('./titanic/train.csv')
df
1.4.3 任务三:查看DataFrame数据的每列的名称
df.columnsIndex(['PassengerId', 'Survived', 'Pclass', 'Name', 'Sex', 'Age', 'SibSp',
'Parch', 'Ticket', 'Fare', 'Cabin', 'Embarked'],
dtype='object')
1.4.4任务四:查看"Cabin"这列的所有值[有多种方法]
#方法1
df.Cabin#方法2
df['Cabin']
使用type查看查看发现返回的是pandas.core.series.Series
type(df['Cabin'])pandas.core.series.Series
想输出格式跟DataFrame一样,可以嵌套一下
df[['Cabin']]
1.4.5 任务五:加载文件"test_1.csv",然后对比"train.csv",看看有哪些多出的列,然后将多出的列删除
经过我们的观察发现一个测试集test_1.csv有一列是多余的,我们需要将这个多余的列删去
test_1=pd.read_csv('test_1.csv')
test_1.head()
#方法1
del test_1['a']
test_1.head()#方法2
test_1=pd.read_csv('test_1.csv')
test_1.pop('a')
test_1.head()那么还有其他方法删除吗?
还可以使用drop方法,官方Wiki的介绍如下(机翻):
DataFrame.drop(labels=None, ***, *axis=0*, *index=None*, *columns=None*, *level=None*, *inplace=False*, *errors='raise'*)
从行或列中删除指定的标签。
通过指定标签名称和相应的标签名称来删除行或列 轴,或直接指定索引或列名。使用 多索引,可以通过指定 水平。
#方法3
test_1=pd.read_csv('test_1.csv')
test_1.drop(['a'], axis=1)1.4.6 任务六: 将['PassengerId','Name','Age','Ticket']这几个列元素隐藏,只观察其他几个列元素
test_1=pd.read_csv('test_1.csv')
test_1.drop(['PassengerId','Name','Age','Ticket'], axis=1)1.5 筛选的逻辑
表格数据中,最重要的一个功能就是要具有可筛选的能力,选出我所需要的信息,丢弃无用的信息。
下面我们还是用实战来学习pandas这个功能。
1.5.1 任务一: 我们以"Age"为筛选条件,显示年龄在10岁以下的乘客信息。
test_1[test_1['Age']<10]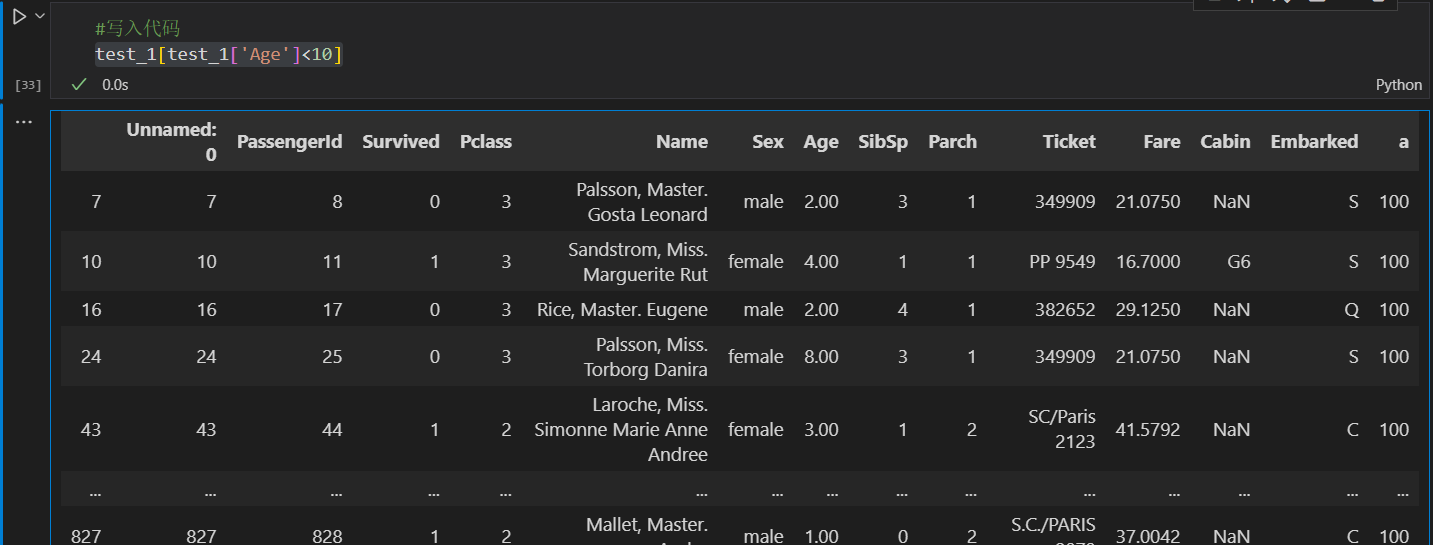
1.5.2 任务二: 以"Age"为条件,将年龄在10岁以上和50岁以下的乘客信息显示出来,并将这个数据命名为midage
test_1[(test_1['Age']>10) & (test_1['Age']<50)]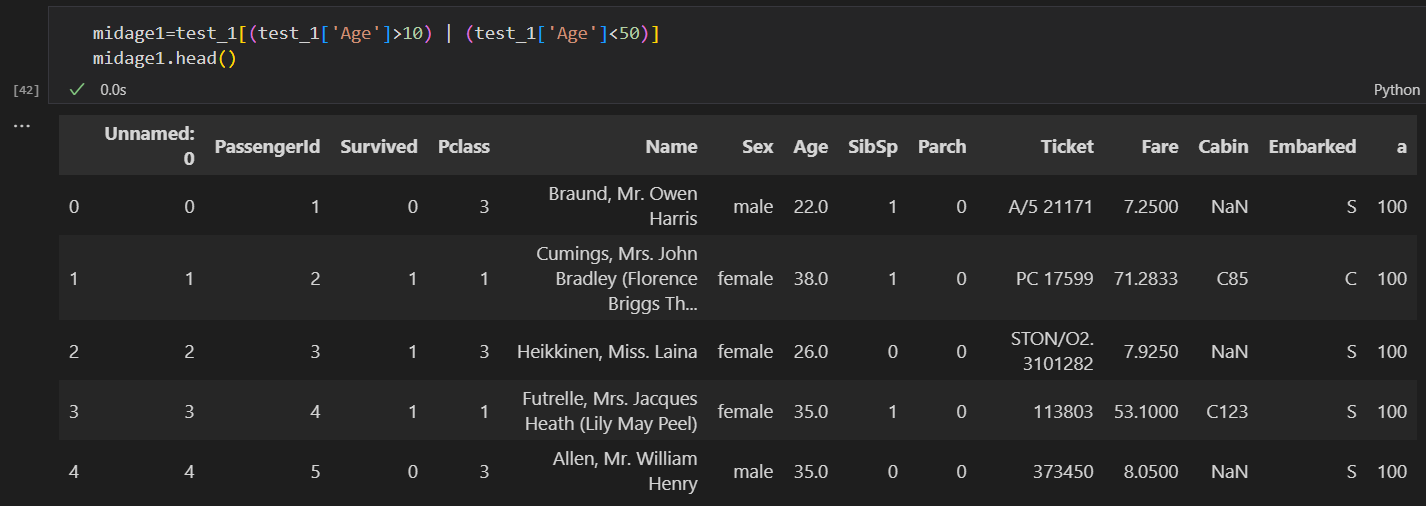
1.5.3 任务三:将midage的数据中第100行的"Pclass"和"Sex"的数据显示出来
#因为源文件的index是乱的,我们使用reset_index()重新计算index,并另存为midage.csv
midage = midage.reset_index(drop=True)
midage.head(3)
midage.to_csv('midage.csv',index=False)#读取重新排序的文件,并输出第100行信息
midage1=pd.read_csv('midage.csv')
midage1.loc[[100],['Pclass','Sex']]1.5.4 任务四:使用loc方法将midage的数据中第100,105,108行的"Pclass","Name"和"Sex"的数据显示出来
midage1.loc[[100,105,108],['Pclass','Name','Sex']]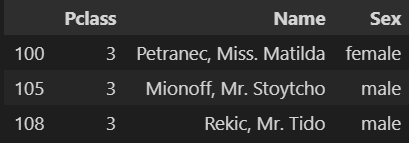
1.5.5 任务五:使用iloc方法将midage的数据中第100,105,108行的"Pclass","Name"和"Sex"的数据显示出来
midage1.iloc[[100,105,108],[2,3,4]]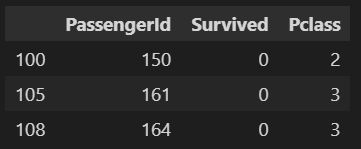
【思考】对比iloc和loc的异同
loc选择列时,需要填写列名;iloc是指定第几个列
第一章 第三节:探索性数据分析
开始之前,导入numpy、pandas包和数据
import numpy as np
import pandas as pd载入之前保存的train_chinese.csv数据,关于泰坦尼克号的任务,我们就使用这个数据
text = pd.read_csv('train_chinese.csv')
text.head()1.6 了解你的数据吗?
教材《Python for Data Analysis》第五章
1.6.1 任务一:利用Pandas对示例数据进行排序,要求升序
#自己构建一个都为数字的DataFrame数据
sample = pd.DataFrame(
np.arange(12).reshape((3, 4)),
index=['1', '2','3'],
columns=['d', 'a', 'b', 'c']
)
samplepd.DataFrame() :创建一个DataFrame对象
np.arange(8).reshape((2, 4)) : 生成一个二维数组(3*4)
第一列:0,1,2,3
第二列:4,5,6,7
第三列: 8, 9, 10, 11
index=['2, 1] :DataFrame 对象的索引列
columns=['d', 'a', 'b', 'c'] :DataFrame 对象的索引行
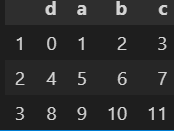
如果想要将构建的DataFrame中的数据根据某一列,升序排列
【问题】:大多数时候我们都是想根据列的值来排序,所以将你构建的DataFrame中的数据根据某一列,升序排列
这个问题需要使用到pandas的sort_values,可以查看官方wiki
具体有几个参数:
by:str 或 str 列表
选择要作为排序依据的名称或名称列表。
- 如果axis为 0 或“index”,则 by 可能包含索引级别和/或列标签。
- 如果axis是 1 或“columns”,则 by 可能包含列级别和/或索引标签。
axis:“{0 或 'index', 1 或 'columns'}”,默认值为 0
选择行排序(0)还是列排序(1)
ascending: bool 或 bool 列表,默认为 True
升序(True)还是降序(False)
#升序
sample.sort_values('a')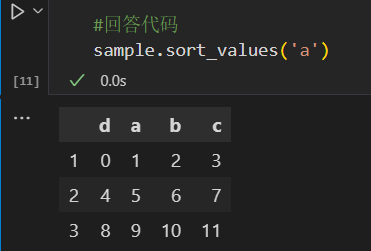
#降序
sample.sort_values('a',ascending=False)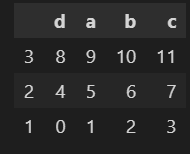
【总结】下面将不同的排序方式做一个总结
1.让行索引升序排序
sample.sort_index()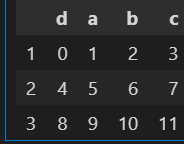
2.让列索引升序排序
sample.sort_index(axis=1)
3.让列索引降序排序
sample.sort_index(axis=1,ascending=False)
4.让任选两列数据同时降序排序
sample.sort_values(by=['a', 'c'], ascending=False)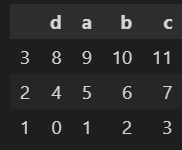
1.6.2 任务二:对泰坦尼克号数据(trian.csv)按票价和年龄两列进行综合排序(降序排列)
对泰坦尼克号数据(trian.csv)按票价和年龄两列进行综合排序(降序排列),从这个数据中你可以分析出什么?
'''
在开始我们已经导入了train_chinese.csv数据,而且前面我们也学习了导入数据过程,根据上面学习,我们直接对目标列进行排序即可
head(20) : 读取前20条数据
'''
text.sort_values(by=['票价', '年龄'], ascending=False).head(20)1.6.3 任务三:利用Pandas进行算术计算,计算两个DataFrame数据相加结果
frame1_a = pd.DataFrame(np.arange(9.).reshape(3, 3),
columns=['a', 'b', 'c'],
index=['one', 'two', 'three'])
frame1_b = pd.DataFrame(np.arange(12.).reshape(4, 3),
columns=['a', 'e', 'c'],
index=['first', 'one', 'two', 'second'])
frame1_a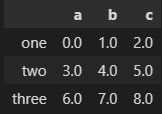
将frame_a和frame_b进行相加
frame1_a+frame1_b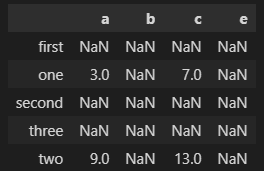
【提醒】两个DataFrame相加后,会返回一个新的DataFrame,对应的行和列的值会相加,没有对应的会变成空值NaN
1.6.4 任务四:通过泰坦尼克号数据如何计算出在船上最大的家族有多少人?
'''
还是用之前导入的chinese_train.csv如果我们想看看在船上,最大的家族有多少人(‘兄弟姐妹个数’+‘父母子女个数’),我们该怎么做呢?
'''
max(text['堂兄弟/妹个数'] + text['堂兄弟/妹个数'])1.6.5 任务五:学会使用Pandas describe()函数查看数据基本统计信息
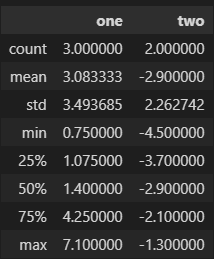
#自己构建一个有数字有空值的DataFrame数据
frame2 = pd.DataFrame([[1.4, np.nan],
[7.1, -4.5],
[np.nan, np.nan],
[0.75, -1.3]
], index=['a', 'b', 'c', 'd'], columns=['one', 'two'])
frame2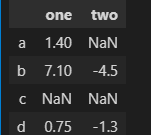
调用 describe 函数,观察frame2的数据基本信息
frame2.describe()'''
count : 样本数据大小
mean : 样本数据的平均值
std : 样本数据的标准差
min : 样本数据的最小值
25% : 样本数据25%的时候的值
50% : 样本数据50%的时候的值
75% : 样本数据75%的时候的值
max : 样本数据的最大值
'''
1.6.6 任务六:分别看看泰坦尼克号数据集中 票价、父母子女 这列数据的基本统计数据,你能发现什么?
'''
看看泰坦尼克号数据集中 票价 这列数据的基本统计数据
'''
text['票价'].describe()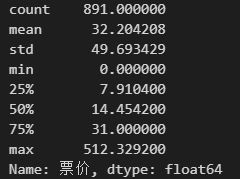
Comments NOTHING