本系列笔记是学习 黑马程序员大数据入门到实战教程,大数据开发必会的Hadoop、Hive,云平台实战 过程中自己总结和记录的笔记,分享出来方便大家学习
HDFS 的基础架构
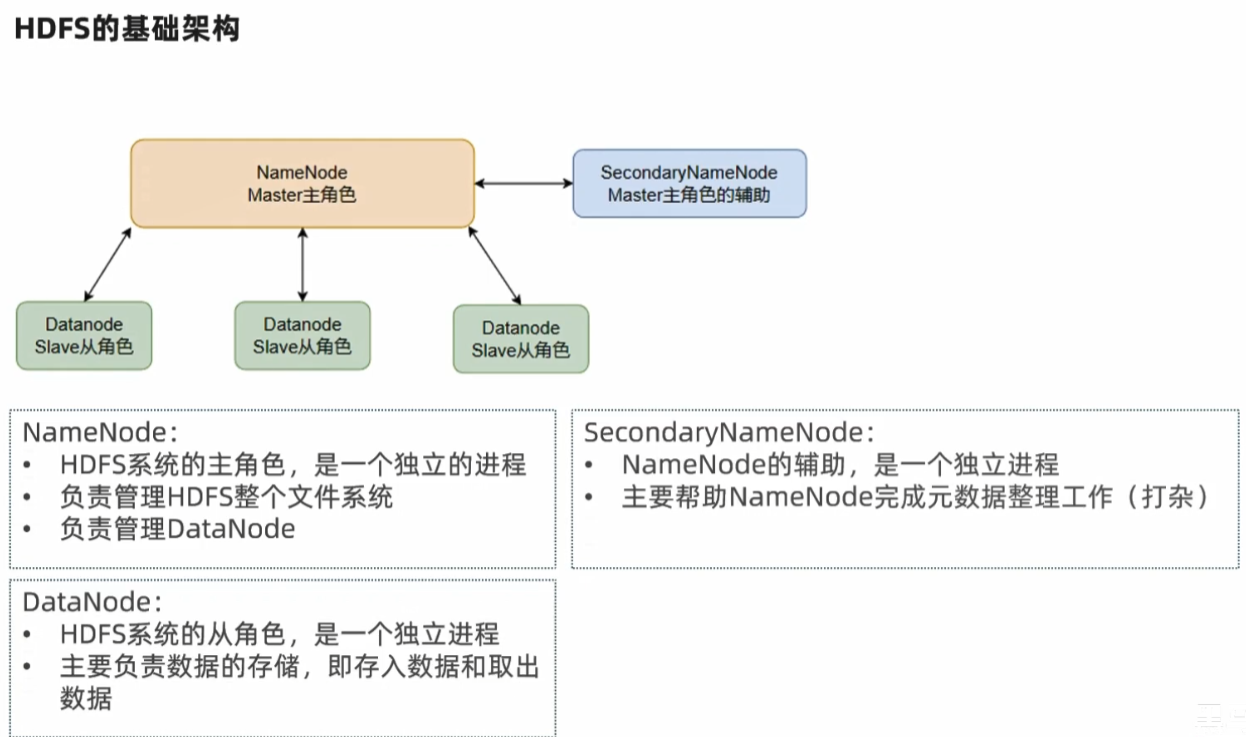
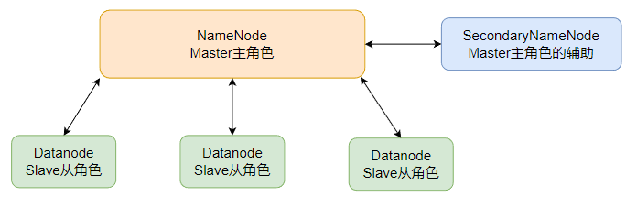
NameNode:
- HDFS 系统的主角色,是一个独立的进程
- 负责管理 HDFS 整个文件系统
- 负责管理 DataNode
SecondaryNameNode:
- NameNode 的辅助,是一个独立进程
- 主要帮助 NameNode 完成元数据整理工作(打杂)
DataNode:
- HDFS 系统的从角色,是一个独立进程
- 主要负责数据的存储,即存入数据和取出数据
部署HDFS集群
以下操作:node1节点执行,root用户身份登录
上传 & 解压
1 ,上传 Hadoop 安装包到node节点中
2 ,解压缩安装包到/export/server/中
tar -zxvf hadoop-3.3.4.tar.gz -C /export/server3 .构建软链接
cd /export/server
ln -s /export/server/hadoop-3.3.4 hadoop4 .进入 hadoop 安装包内
cd hadoop
llHadoop安装包目录结构
各个文件夹含义如下
- bin,存放Hadoop的各类程序(命令)
- etc,存放Hadoop的配置文件
- include,C语言的一些头文件
- lib,存放Linux系统的动态链接库(.so文件)
- libexec,存放配置Hadoop系统的脚本文件(.sh和.cmd)
- licenses-binary,存放许可证文件
- sbin,管理员程序(super bin)
- share,存放二进制源码(Java jar包)
修改配置文件,应用自定义设置
配置HDFS集群,我们主要涉及到如下文件的修改:
- workers: 配置从节点(DataNode)有哪些
- hadoop-env.sh: 配置Hadoop的相关环境变量
- core-site.xml: Hadoop核心配置文件
- hdfs-site.xml: HDFS核心配置文件
这些文件均存在与$HADOOP_HOME/etc/hadoop文件夹中
ps:$HADOOP_HOME是后续我们要设置的环境变量,其指代Hadoop安装文件夹即/export/server/hadoop
配置workers文件
该文件存储DataNode所在机器
cd ./etc/hadoop
vim workers填入如下内容
node1
node2
node3配置hadoop-env.sh文件
vim hadoop-env.sh# 填入如下内容
export JAVA_HOME=/export/server/jdk
export HADOOP_HOME=/export/server/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_LOG_DIR=$HADOOP_HOME/logs- JAVA_HOME,指明JDK环境的位置在哪
- HADOOP_HOME,指明Hadoop安装位置
- HADOOP_CONF_DIR,指明Hadoop配置文件目录位置
- HADOOP_LOG_DIR,指明Hadoop运行日志目录位置
通过记录这些环境变量, 来指明上述运行时的重要信息
配置core-site.xml文件
vim core-site.xml在文件内部填入如下内容
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:8020</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
</configuration>- key:fs.defaultFS
- 含义:HDFS文件系统的网络通讯路径
- 值:hdfs://node1:8020
- 协议为hdfs://
- namenode为node1
- namenode通讯端口为8020
- key:io.file.buffer.size
- 含义:io操作文件缓冲区大小
- 值:131072 byte
hdfs://node1:8020为整个HDFS内部的通讯地址,应用协议为hdfs://(Hadoop内置协议)
表明DataNode将和node1的8020端口通讯,node1是NameNode所在机器
此配置固定了node1必须启动NameNode进程
配置hdfs-site.xml文件
vim hdfs-site.xml# 在文件内部填入如下内容
<configuration>
<property>
<name>dfs.datanode.data.dir.perm</name>
<value>700</value>
</property>
<!--
key:dfs.datanode.data.dir.perm
含义:hdfs文件系统,默认创建的文件权限设置
值:700,即:rwx
-->
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/nn</value>
</property>
<!--
key:dfs.namenode.name.dir
含义:NameNode元数据的存储位置
值:/data/nn,在node1节点的/data/nn目录下
-->
<property>
<name>dfs.namenode.hosts</name>
<value>node1,node2,node3</value>
</property>
<!--
key:dfs.namenode.hosts
含义:NameNode允许哪几个节点的DataNode连接(即允许加入集群)
值:node1、node2、node3,这三台服务器被授权
-->
<property>
<name>dfs.blocksize</name>
<value>268435456</value>
</property>
<!--
key:dfs.blocksize
含义:hdfs默认块大小
值:268435456(256MB)
-->
<property>
<name>dfs.namenode.handler.count</name>
<value>100</value>
</property>
<!--
key:dfs.namenode.handler.count
含义:namenode处理的并发线程数
值:100,以100个并行度处理文件系统的管理任务
-->
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/dn</value>
</property>
<!--
key:dfs.datanode.data.dir
含义:从节点DataNode的数据存储目录
值:/data/dn,即数据存放在node1、node2、node3,三台机器的/data/dn内
-->
</configuration>准备数据目录
namenode数据存放node1的/data/nn
datanode数据存放node1、node2、node3的/data/dn
- 在node1节点:
mkdir -p /data/nn
mkdir /data/dn- 在node2和node3节点:
mkdir -p /data/dn分发Hadoop文件夹
在node1执行如下命令
cd /export/server
scp -r hadoop-3.3.4 node2:`pwd`/
scp -r hadoop-3.3.4 node3:`pwd`/在node2执行,为hadoop配置软链接
ln -s /export/server/hadoop-3.3.4 /export/server/hadoop在node3执行,为hadoop配置软链接
ln -s /export/server/hadoop-3.3.4 /export/server/hadoop配置环境变量
node1,node2,node3都执行以下操作
vim /etc/profile# 在/etc/profile文件底部追加如下内容
export HADOOP_HOME=/export/server/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbinsource /etc/profile授权为hadoop用户
hadoop部署的准备工作基本完成
为了确保安全,hadoop系统不以root用户启动,我们以普通用户hadoop来启动整个Hadoop服务
所以,现在需要对文件权限进行授权。
ps:请确保已经提前创建好了hadoop用户(前置准备章节中有讲述),并配置好了hadoop用户之间的免密登录
以root身份,在node1、node2、node3三台服务器上均执行如下命令
# 以root身份,在三台服务器上均执行
chown -R hadoop:hadoop /data
chown -R hadoop:hadoop /export格式化整个文件系统
格式化namenode(noode1执行)
# 确保以hadoop用户执行
su - hadoop
# 格式化namenode
hadoop namenode -format启动
# 一键启动hdfs集群
start-dfs.sh
# 一键关闭hdfs集群
stop-dfs.sh
# 如果遇到命令未找到的错误,表明环境变量未配置好,可以以绝对路径执行
/export/server/hadoop/sbin/start-dfs.sh
/export/server/hadoop/sbin/stop-dfs.shHDFS的Shell操作
进程启停管理
一键启停脚本
Hadoop HDFS组件内置了HDFS集群的一键启停脚本。
$HADOOP_HOME/sbin/start-dfs.sh,一键启动HDFS集群
执行原理:
- 在执行此脚本的机器上,启动SecondaryNameNode
- 读取core-site.xml内容(fs.defaultFS项),确认NameNode所在机器,启动NameNode
- 读取workers内容,确认DataNode所在机器,启动全部DataNode
$HADOOP_HOME/sbin/stop-dfs.sh,一键关闭HDFS集群
执行原理:
- 在执行此脚本的机器上,关闭SecondaryNameNode
- 读取core-site.xml内容(fs.defaultFS项),确认NameNode所在机器,关闭NameNode
- 读取workers内容,确认DataNode所在机器,关闭全部DataNode
单进程启停
除了一键启停外,也可以单独控制进程的启停。
1.$HADOOP_HOME/sbin/hadoop-daemon.sh,此脚本可以单独控制所在机器的进程的启停
用法:
hadoop-daemon.sh (start|status|stop) (namenode|secondarynamenode|datanode)2.$HADOOP_HOME/bin/hdfs,此程序也可以用以单独控制所在机器的进程的启停
用法:
hdfs --daemon (start|status|stop) (namenode|secondarynamenode|datanode)文件系统操作命令
HDFS文件系统基本信息
HDFS作为分布式存储的文件系统,有其对数据的路径表达方式。
HDFS同Linux系统一样,均是以/作为根目录的组织形式
- Linux:/usr/local/hello.txt
- HDFS:/usr/local/hello.txt
如何区分呢?
- Linux:file:///
- HDFS:hdfs://namenode:port/
如上路径:
- Linux:file:///usr/local/hello.txt
- HDFS:hdfs://node1:8020/usr/local/hello.txt
协议头file:/// 或 hdfs://node1:8020/可以省略
- 需要提供Linux路径的参数,会自动识别为file://
- 需要提供HDFS路径的参数,会自动识别为hdfs://
除非你明确需要写或不写会有BUG,否则一般不用写协议头
介绍
关于HDFS文件系统的操作命令,Hadoop提供了2套命令体系
hadoop命令(老版本用法)
用法:hadoop fs [generic options]
hdfs命令(新版本用法)
用法:hdfs dfs [generic options]
1、创建文件夹
- hadoop fs -mkdir [-p] …
- hdfs dfs -mkdir [-p] …
- path 为待创建的目录
- -p 选项的行为与Linux mkdir -p一致,它会沿着路径创建父目录。
hadoop fs -mkdir -p /itcast/bigdata
hdfs dfs -mkdir -p /itheima/hadoop2、查看指定目录下内容
- hadoop fs -ls [-h] [-R] [ …]
- hdfs dfs -ls [-h] [-R] [ …]
- path 指定目录路径
- -h 人性化显示文件size
- -R 递归查看指定目录及其子目录

3、上传文件到HDFS指定目录下
- hadoop fs -put [-f] [-p] …
- hdfs dfs -put [-f] [-p] …
- -f 覆盖目标文件(已存在下)
- -p 保留访问和修改时间,所有权和权限。
- localsrc 本地文件系统(客户端所在机器)
- dst 目标文件系统(HDFS)
hadoop fs -put words.txt /itcast
hdfs dfs -put file:///etc/profile hdfs://node1:8020/itcast4、查看HDFS文件内容
- hadoop fs -cat …
- hdfs dfs -cat …
读取指定文件全部内容,显示在标准输出控制台。
hadoop fs -cat /itcast/words.txt
hdfs dfs -cat /itcast/profile读取大文件可以使用管道符配合more
- hadoop fs -cat | more
- hdfs dfs -cat | more
5、下载HDFS文件
hadoop fs -get [-f] [-p] …
hdfs dfs -get [-f] [-p] …
下载文件到本地文件系统指定目录,localdst必须是目录
-f 覆盖目标文件(已存在下)
-p 保留访问和修改时间,所有权和权限。
[root@node1 ~]# mkdir test
[root@node1 ~]# cd test/
[root@node1 test]# ll total 0
[root@node1 test]# hadoop fs -get /itcast/zookeeper.out ./
[root@node1 test]# ll
total 20 -rw-r--r-- 1 root root 18213 Aug 18 17:54 zookeeper.out6、拷贝HDFS文件
只能在hdfs文件系统中进行拷贝,即HDFS对HDFS复制
- hadoop fs -cp [-f] …
- hdfs dfs -cp [-f] …
-f 覆盖目标文件(已存在下)
[root@node3 ~]# hadoop fs -cp /small/1.txt /itcast
[root@node3 ~]# hadoop fs -cp /small/1.txt /itcast/666.txt #重命名7、追加数据到HDFS文件中
- hadoop fs -appendToFile …
- hdfs dfs -appendToFile …
将所有给定本地文件的内容追加到给定dst文件。
dst如果文件不存在,将创建该文件。
如果为-,则输入为从标准输入中读取。
#追加内容到文件尾部 appendToFile
[root@node3 ~]# echo 1 >> 1.txt
[root@node3 ~]# echo 2 >> 2.txt
[root@node3 ~]# echo 3 >> 3.txt
[root@node3 ~]# hadoop fs -put 1.txt /
[root@node3 ~]# hadoop fs -cat /1.txt
1
[root@node3 ~]# hadoop fs -appendToFile 2.txt 3.txt /1.txt
[root@node3 ~]# hadoop fs -cat /1.txt
1
2
38、HDFS数据移动操作
- hadoop fs -mv …
- hdfs dfs -mv …
移动文件到指定文件夹下
可以使用该命令移动数据,重命名文件的名称
9、HDFS数据删除操作
- hadoop fs -rm -r [-skipTrash] URI [URI …]
- hdfs dfs -rm -r [-skipTrash] URI [URI …]
删除指定路径的文件或文件夹
-skipTrash 跳过回收站,直接删除
回收站功能默认关闭,如果要开启需要在core-site.xml内配置:
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
<property>
<name>fs.trash.checkpoint.interval</name>
<value>120</value>
</property>
无需重启集群,在哪个机器配置的,在哪个机器执行命令就生效。
回收站默认位置在:/user/用户名(hadoop)/.TrashHDFS WEB浏览
使用WEB浏览操作文件系统,一般会遇到权限问题
这是因为WEB浏览器中是以匿名用户(dr.who)登陆的,其只有只读权限,多数操作是做不了的。
如果需要以特权用户在浏览器中进行操作,需要配置如下内容到core-site.xml并重启集群
<property>
<name>hadoop.http.staticuser.user</name>
<value>hadoop</value>
</property>但是,不推荐这样做HDFS WEBUI,只读权限挺好的,简单浏览即可如果给与高权限,会有很大的安全问题,造成数据泄露或丢失
HDFS客户端
Big Data Tools插件
在Jetbrains的产品中,均可以安装插件,其中:
Big Data Tools插件可以帮助我们方便的操作HDFS,比如
- IntelliJ IDEA(Java IDE)
- PyCharm(Python IDE)
- DataGrip(SQL IDE)
均可以支持Bigdata Tool插件。
在设置->Plugins(插件)-> Marketplace(市场),搜索Big Data Tools,点击Install安装即可
需要对Windows系统做一些基础设置,配合插件使用
- 解压Hadoop安装包到Windows系统,如解压到:E:\hadoop-3.3.4
- 设置$HADOOP_HOME环境变量指向:E:\hadoop-3.3.4
- 下载
- hadoop.dll(https://github.com/steveloughran/winutils/blob/master/hadoop-3.0.0/bin/hadoop.dll)
- winutils.exe(https://github.com/steveloughran/winutils/blob/master/hadoop-3.0.0/bin/winutils.exe)
将hadoop.dll和winutils.exe放入$HADOOP_HOME/bin中
NFS
配置NFS
配置HDFS需要配置如下内容:
- core-site.xml,新增配置项 以及 hdfs-site.xml,新增配置项
- 开启portmap、nfs3两个新进程
在node1进行如下操作
- ###### 在core-site.xml 内新增如下两项
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
<!--
项目: hadoop.proxyuser.hadoop.groups
值:*
允许hadoop用户代理任何其它用户组
-->
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<!--
项目:hadoop.proxyuser.hadoop.hosts
值:*
允许代理任意服务器的请求
-->- ###### 在hdfs-site.xml中新增如下项
<property>
<name>nfs.superuser</name>
<value>hadoop</value>
</property>
<!--
nfs.suerpser:NFS操作HDFS系统,所使用的超级用户(hdfs的启动用户为超级用户)
-->
<property>
<name>nfs.dump.dir</name>
<value>/tmp/.hdfs-nfs</value>
</property>
<!--
nfs.dump.dir:NFS接收数据上传时使用的临时目录
-->
<property>
<name>nfs.exports.allowed.hosts</name>
<value>192.168.88.1 rw</value>
</property>
<!--
nfs.exports.allowed.hosts:NFS允许连接的客户端IP和权限,rw表示读写,IP整体或部分可以以*代替
-->启动NFS功能
- 将配置好的core-site.xml和hdfs-site.xml分发到node2和node3
scp -r core-site.xml hdfs-site.xml node2:`pwd`/
scp -r core-site.xml hdfs-site.xml node3:`pwd`/2.重启Hadoop HDFS集群
stop-dfs.sh3.停止系统的NFS相关进程
a.关闭系统nfs并关闭其开机自启
su
systemctl stop nfs
systemctl disable nfs b.卸载系统自带rpcbind
yum remove -y rpcbind 4.启动portmap(HDFS自带的rpcbind功能)(必须以root执行):
hdfs --daemon start portmap5.启动nfs(HDFS自带的nfs功能)(必须以hadoop用户执行):
su hadoop
hdfs --daemon start nfs3检查NFS是否正常
以下操作在node2或node3执行(因为node1卸载了rpcbind,缺少了必要的2个命令)
执行:rpcinfo -p node1,正常输出如下有mountd和nfs出现
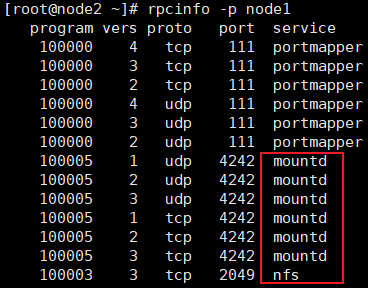
执行:showmount -e node1
可以看到

- 开启Windows的NFS功能
- 在Windows命令提示符(CMD)内输入:
net use X: \\192.168.88.151\!- 完成后即可在文件管理器中看到盘符为X的网络位置
HDFS的存储原理
存储原理
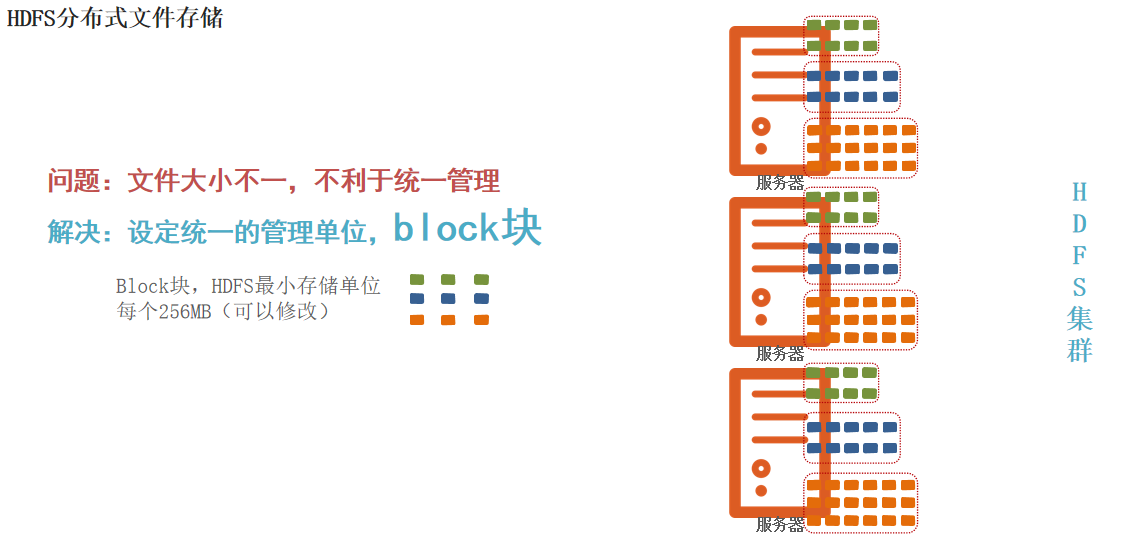
hdfs中会将文件统一切分成统一大小的块(block块),分发至节点存储
Block块,HDFS最小存储单位每个256MB(可以修改)
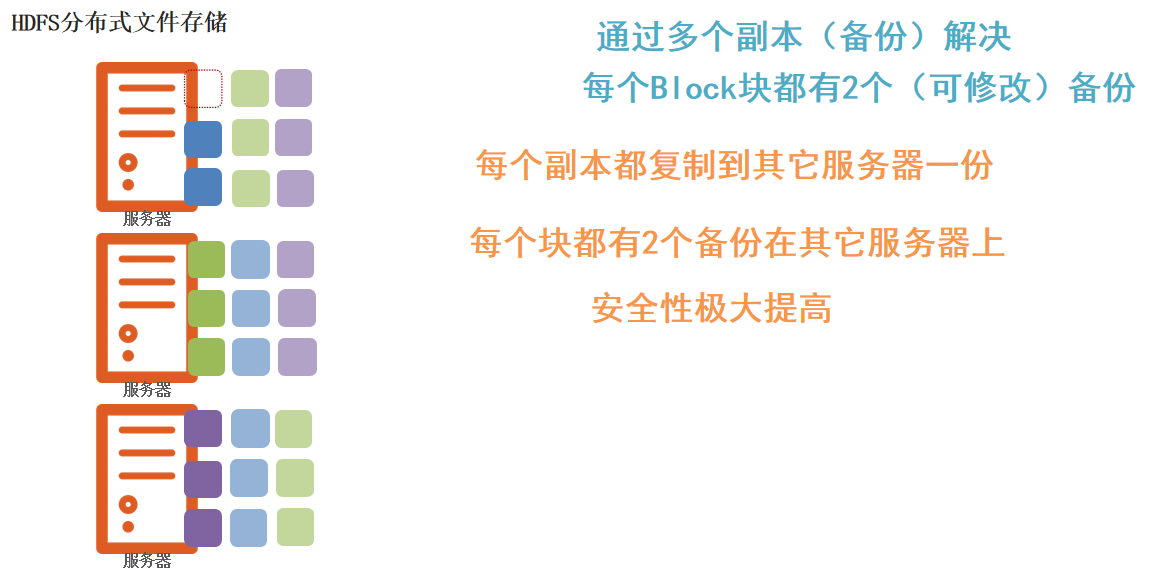
同时为了防止块丢失,导致数据丢失,采用副本进行备份
fsck命令
HDFS副本块数量的配置
在前面我们了解了HDFS文件系统的数据安全,是依靠多个副本来确保的。如何设置默认文件上传到HDFS中拥有的副本数量呢?可以在hdfs-site.xml中配置如下属性:
<property>
<name>dfs.replication</name>
<value>3</value>
</property>这个属性默认是3,一般情况下,我们无需主动配置(除非需要设置非3的数值)如果需要自定义这个属性,请修改每一台服务器的hdfs-site.xml文件,并设置此属性。
fsck命令检查文件的副本数
除了配置文件外,我们还可以在上传文件的时候,临时决定被上传文件以多少个副本存储。
hadoop fs -D dfs.replication=2 -put test.txt /tmp/如上命令,就可以在上传test.txt的时候,临时设置其副本数为2
对于已经存在HDFS的文件,修改dfs.replication属性不会生效,如果要修改已存在文件可以通过命令
hadoop fs -setrep [-R] 2 path如上命令,指定path的内容将会被修改为2个副本存储。-R选项可选,使用-R表示对子目录也生效。
同时,我们可以使用hdfs提供的fsck命令来检查文件的副本数
hdfs fsck path [-files [-blocks [-locations]]]fsck
可以检查指定路径是否正常
-files
可以列出路径内的文件状态
-files -blocks
输出文件块报告(有几个块,多少副本)
-files -blocks -locations
输出每一个block的详情
[hadoop@node1 ~]$ hdfs fsck /a/3.txt -files -blocks -locations
Connecting to namenode via http://node1:9870/fsck?ugi=hadoop&files=1&blocks=1&locations=1&path=%2Fa%2F3.txt
FSCK started by hadoop (auth:SIMPLE) from /192.168.10.151 for path /a/3.txt at Tue Feb 27 19:14:36 CST 2024
/a/3.txt 4 bytes, replicated: replication=3, 1 block(s): OK
0. BP-458852383-192.168.88.151-1708529998866:blk_1073741825_1001 len=4 Live_repl=3 [DatanodeInfoWithStorage[192.168.10.152:9866,DS-dfa2896e-93fe-4158-87fe-4ef0d3b33e9f,DISK], DatanodeInfoWithStorage[192.168.10.153:9866,DS-83827086-9c43-4479-a7e9-a323a66d741f,DISK], DatanodeInfoWithStorage[192.168.10.151:9866,DS-6e2cccb1-2956-4a61-9870-39a0dfa78265,DISK]]
Status: HEALTHY
Number of data-nodes: 3
Number of racks: 1
Total dirs: 0
Total symlinks: 0
Replicated Blocks:
Total size: 4 B
Total files: 1
Total blocks (validated): 1 (avg. block size 4 B)
Minimally replicated blocks: 1 (100.0 %)
Over-replicated blocks: 0 (0.0 %)
Under-replicated blocks: 0 (0.0 %)
Mis-replicated blocks: 0 (0.0 %)
Default replication factor: 3
Average block replication: 3.0
Missing blocks: 0
Corrupt blocks: 0
Missing replicas: 0 (0.0 %)
Blocks queued for replication: 0
Erasure Coded Block Groups:
Total size: 0 B
Total files: 0
Total block groups (validated): 0
Minimally erasure-coded block groups: 0
Over-erasure-coded block groups: 0
Under-erasure-coded block groups: 0
Unsatisfactory placement block groups: 0
Average block group size: 0.0
Missing block groups: 0
Corrupt block groups: 0
Missing internal blocks: 0
Blocks queued for replication: 0
FSCK ended at Tue Feb 27 19:14:36 CST 2024 in 3 milliseconds
The filesystem under path '/a/3.txt' is HEALTHYblock配置
可以看到通过fsck命令我们验证了:
文件有多个副本
文件被分成多个块存储在hdfs
对于块(block),hdfs默认设置为256MB一个,也就是1GB文件会被划分为4个block存储。块大小可以通过参数:
<property>
<name>dfs.blocksize</name>
<value>268435456</value>
<description>设置HDFS块大小,单位是b</description>
</property>如上,设置为256MB
NameNode元数据
在hdfs中,文件是被划分了一堆堆的block块,那如果文件很大、以及文件很多,Hadoop是如何记录和整理文件和block块的关系呢?
答案就在于NameNode
NameNode基于一批edits和一个fsimage文件的配合完成整个文件系统的管理和维护
edits文件
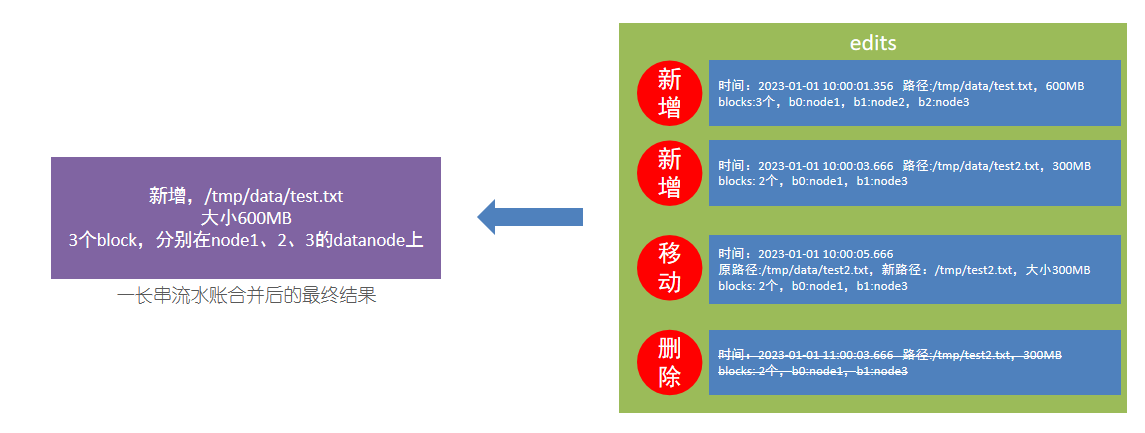
edits文件,是一个流水账文件,记录了hdfs中的每一次操作,以及本次操作影响的文件其对应的block
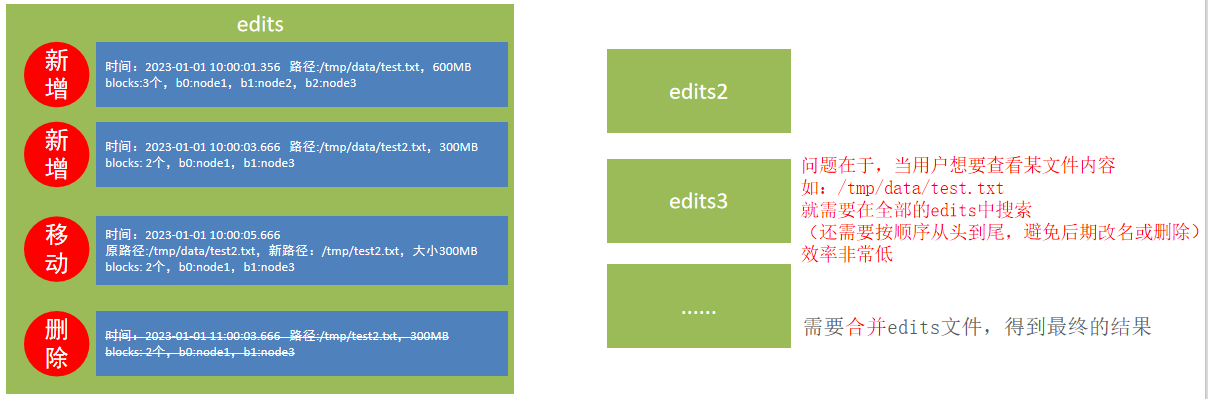
因为edits是日志记录读写,当记录过多时,顺序查询会耗费大量时间,所以需要合并后显示文件的最终结果即可
fsimage文件
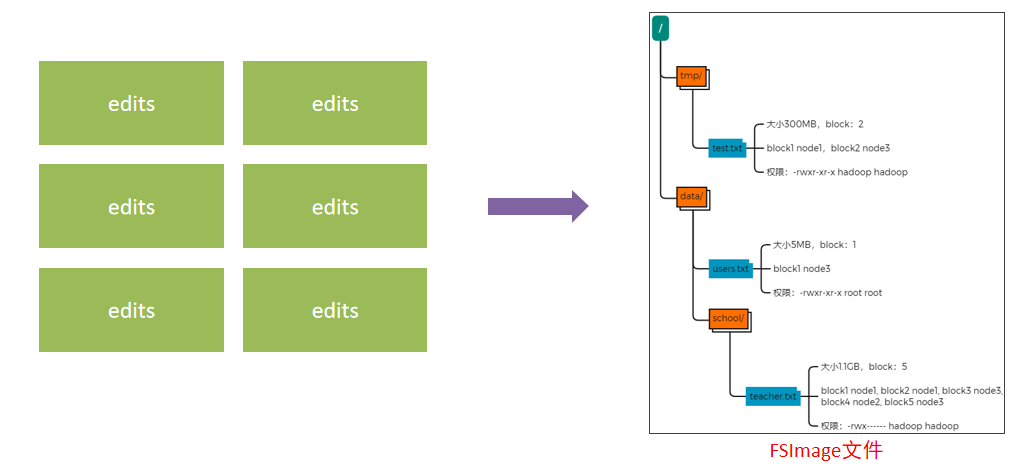
将全部的edits文件,合并为最终结果,即可得到一个FSImage文件
NameNode元数据管理维护
NameNode基于edits和FSImage的配合,完成整个文件系统文件的管理。
1.每次对HDFS的操作,均被edits文件记录
2.edits达到大小上线后,开启新的edits记录
3.定期进行edits的合并操作
- 如当前没有fsimage文件, 将全部edits合并为第一个fsimage
- 如当前已存在fsimage文件,将全部edits和已存在的fsimage进行合并,形成新的fsimage
- 重复123流程
元数据合并控制参数
对于元数据的合并,是一个定时过程,基于:
- dfs.namenode.checkpoint.period,默认3600(秒)即1小时
- dfs.namenode.checkpoint.txns,默认1000000,即100W次事务
只要有一个先达到条件就执行。检查是否达到条件,默认60秒检查一次,基于:
- dfs.namenode.checkpoint.check.period,默认60(秒),来决定
SecondaryNameNode的作用
没错,合并元数据的事情就是它干的
SecondaryNameNode会通过http从NameNode拉取数据(edits和fsimage)
然后合并完成后提供给NameNode使用。
HDFS数据的读写流程
客户端写数据流程
1.客户端向NameNode发起请求
2.NameNode审核权限、剩余空间后,满足条件允许写入,并告知客户端写入的DataNode地址
3.客户端向指定的DataNode发送数据包
4.被写入数据的DataNode同时完成数据副本的复制工作,将其接收的数据分发给其它DataNode
5.如上图,DataNode1复制给DataNode2,然后基于DataNode2复制给Datanode3和DataNode46. 写入完成客户端通知NameNode,NameNode做元数据记录工作
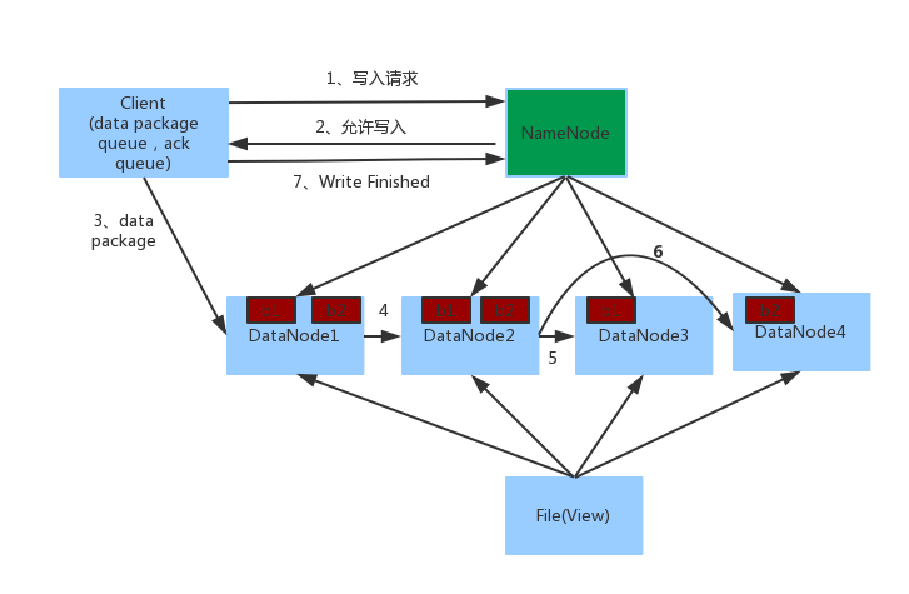
关键信息点:
- NameNode不负责数据写入,只负责元数据记录和权限审批
- 客户端直接向1台DataNode写数据,这个DataNode一般是离客户端最近(网络距离)的那一个
- 数据块副本的复制工作,由DataNode之间自行完成(构建一个PipLine,按顺序复制分发,如图1给2, 2给3和4)
数据读取流程
1、客户端向NameNode申请读取某文件
2、 NameNode判断客户端权限等细节后,允许读取,并返回此文件的block列表
3、客户端拿到block列表后自行寻找DataNode读取即可
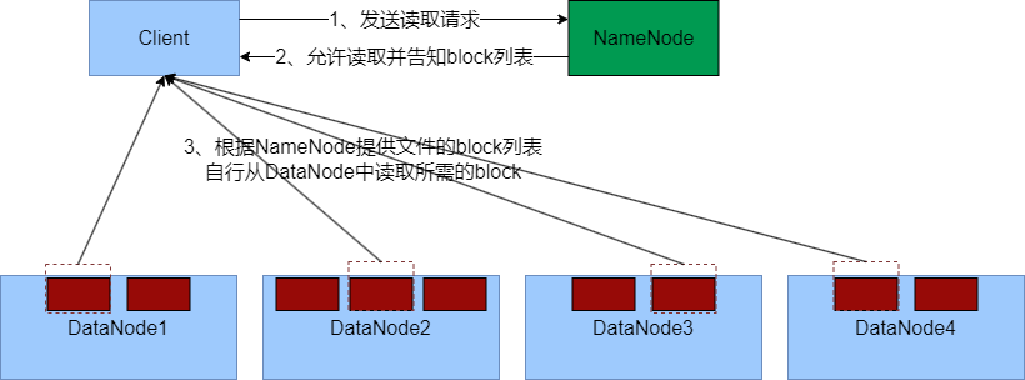
关键点:
1、数据同样不通过NameNode提供
2、NameNode提供的block列表,会基于网络距离计算尽量提供离客户端最近的
这是因为1个block有3份,会尽量找离客户端最近的那一份让其读取
Comments NOTHING