本系列笔记是学习 黑马程序员大数据入门到实战教程,大数据开发必会的Hadoop、Hive,云平台实战 过程中自己总结和记录的笔记,分享出来方便大家学习
前期配置
配置jdk
mkdir -p /export/server
tar -zxvf jdk-8u202-linux-x64.tar.gz -C /export/server
ln -s /export/server/jdk1.8.0_202/ /export/server/jdk编辑/etc/profile文件
export JAVA_HOME=/export/server/jdk
export PATH=$PATH:$JAVA_HOME/bin环境变量生效
source /etc/profile配置java执行程序软链接
rm -f /usr/bin/java
ln -s /export/server/jdk/bin/java /usr/bin/java验证
java -version
javac -version关闭防火墙和SELinux
systemctl stop firewalld.service
systemctl disable firewalld.service vim /etc/selinux/config
SELINUX=disabled大数据概况
1.什么是大数据
狭义上:对海量数据进行处理的软件技术体系
广义上.数字化、信息化时代的基础支撑,以数据为生活赋能
2.大数据的 5 个主要特征
volume 体积 小
variety 种类 多
value 价值 低
velocity 速度 快
veracity 质量 低
3.大数据核心工作:
- 数据存储
- 数据计算
- 数据传输
存储:妥善保存海量待处理数据
计算:完成海量数据的价值挖掘
传输:协助各个环节的数据传输
大数据软件生态

1.数据存储
Apache Hadoop - HDFS

Apache Hadoop 框架内的组件 HDFS 是大数据体系中使用最为广泛的分布式存储技术
Apache HBase

Apache HBase 是大数据体系内使用非常广泛的 NoSQL KV 型数据库技术HBase 是基于 HDFS 之上构建的。
Apache KUDU

Apache Kudu 同为大数据体系中使用较多的分布式存储引擎
云平台存储组件
除此以外,各大云平台厂商也有相应的大数据存储组件,如阿里云的 OSS 、 UCIoud 的 US3 、 AWS 的 S3 、金山云的 KS3 等等
2.数据计算
Apache Hadoop - MapReduce

Apache Hadoop 的 MapReduce 组件是最早一代的大数据分布式计算引擎对大数据的发展做出了卓越的贡献
Apache Hive

Apache Hive 是一款以 SQL 为要开发语言的分布式计算框架。其底层使用了 Hadoop的 MapReduce 技术
Apache Hive 至今仍活跃在大数据一线/被许多公司使用。
Apache Spark

Apache Spark 是目前全球范围内最火热的分布式内存计算引擎。是大数据体系中的明星计算产品
Apache FIink

Apache Flink 同样也是一款明星级的大数据分布式内存计算引擎。特别是在实时计算(流计算)领域, FIink 占据了大多数的国内市场。
3.数据传输
Apache Kafka

Apache Kafka 是一款分布式的消息系统,可以完成海量规模的数据传输工作。Apache Kafka 在大数据领域也是明星产品
Apache PuIsar

Apache PuIsar 同样是一款分布式的消息系统。在大数据领域同样有非常多的使用者。
Apache FIume

Apache FIume 是一款流式数据采集工具/可以从非常多的数据源中完成数据采集传输的任务。
Apache Sqoop

Apache sqoop 是一款 ETL 工具,可以协助大数据体系和关系型数据库之间进行数据传输。
Apache Hadoop 概述
1.Apache Hadoop 框架
Hadoop 是 Apache 软件基金会下的顶级开源项目,用以提供:
- 分布式数据存储
- 分布式数据计算
- 分布式资源调度
为一体的整体解决方案。
Apache Hadoop 是典型的分布式软件框架,可以部署在 1 台乃至成千上万台服务器节点上协同工作。个人或企业可以借助 Hadoop 构建大规模服务器集群,完成海量数据的存储和计算。
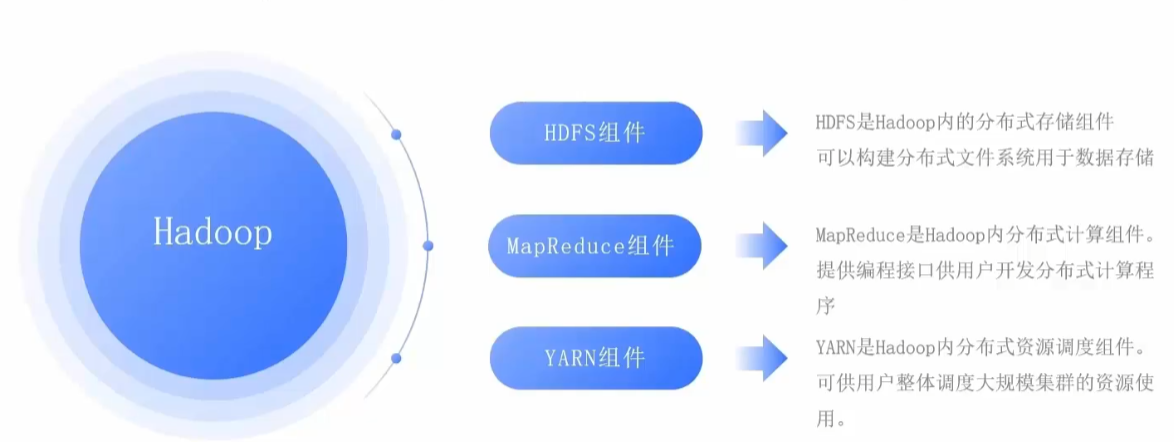
通常意义上, Hadoop 是一个整体,其内部还会细分为三个功能组件,分别是:
- HDFS组件: HDFS 是 Hadoop 内的分布式存储组件可以构建分布式文件系统用于数据存储
- MapReduce组件: MapReduce 是 Hadoop 内分布式计算组件。提供编程接口供用户开发分布式计算程序
- YARN组件: YARN 是 Hadoop 内分布式资源调度组件。可供用户整体调度大规模集群的资源使用。
2.Hadoop 的发展

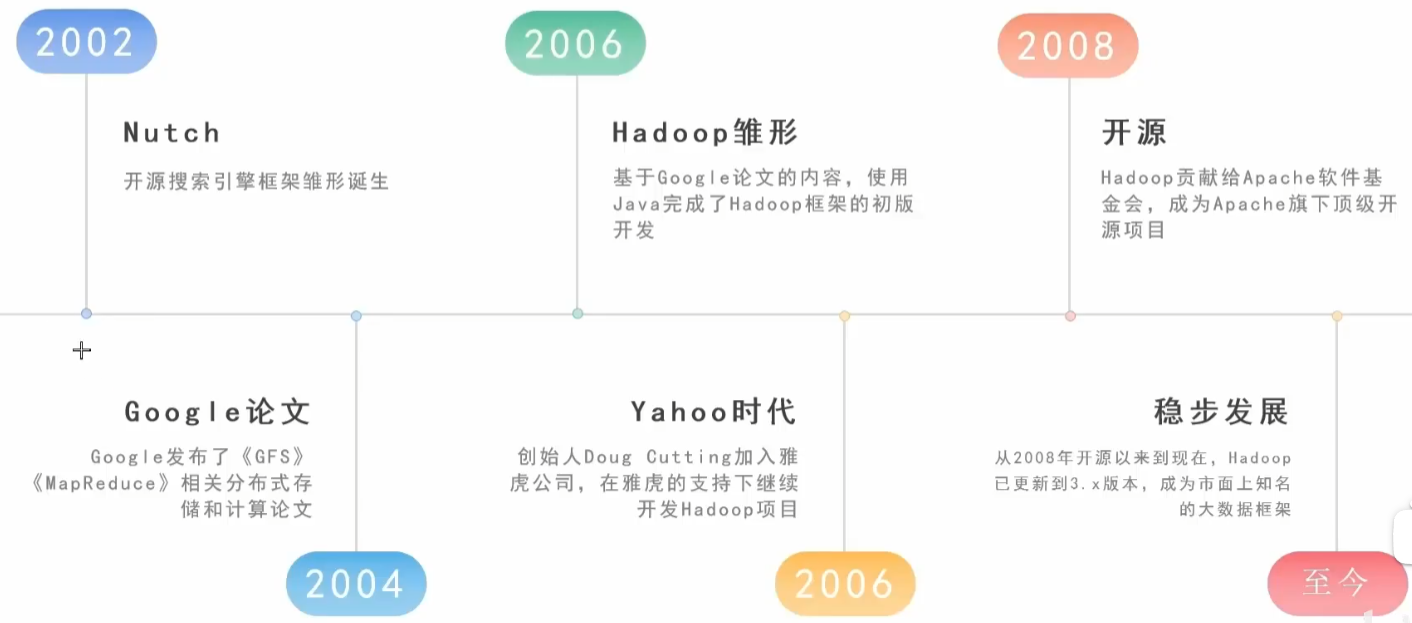
lladoop 创始人: Doug Cuttinglladoop
起源于 Apache Lucenef 项目: Nutch
Nutch 的设计目标是构建一个大型的全网搜索引擎。
遇到瓶颈:如何解决数十亿网页的存储和索引问题
Google 三篇论文
《 The Google file system 》:谷歌分布式文件系统 GFS
《 MapReduce : Simplified Data Processing on Large Clusters 》:谷歌分布式计算框架 MapReduce
Bigtable: A Distributed Storage System for Structured Data 》:谷歌结构化数据存储系统
Hadoop 发行版本

Apache 开源社区版本
http://hadoop.apache.org/
商业发行版本
- CDH (CIoudera's Distribution, including Apache Hadoop) Cloudera 公司出品目前使用最多的商业版
- HDP (Hortonworks Data PIatform )/ Hortonworks 公司出品/目前被 Cloudera 收购
- 星环/国产商业版,星环公司出品,在国内政企使用较多
Comments NOTHING