缺失值观察与处理
缺失值观察
info()
对一个dataframe对象来说,我们可以使用 info()方法,查看对象的统计信息
例如
#加载数据train.csv
df = pd.read_csv('train.csv')
#查看对象信息
df.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890#这里显示统计
Data columns (total 12 columns):
# Column Non-Null Count(这里是非空个数) Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB我们发现有些列的非空个数不等于总计个数,说明有缺失值
isnull().sum()
pandas库中有一个十分便利的isnull()函数,它可以用来判断缺失值
单独使用的话效果如下
df.isnull()| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | False | False | False | False | False | False | False | False | False | False | True | False |
| 1 | False | False | False | False | False | False | False | False | False | False | False | False |
| 2 | False | False | False | False | False | False | False | False | False | False | True | False |
| 3 | False | False | False | False | False | False | False | False | False | False | False | False |
| 4 | False | False | False | False | False | False | False | False | False | False | True | False |
| … | … | … | … | … | … | … | … | … | … | … | … | … |
| 886 | False | False | False | False | False | False | False | False | False | False | True | False |
| 887 | False | False | False | False | False | False | False | False | False | False | False | False |
| 888 | False | False | False | False | False | True | False | False | False | False | True | False |
| 889 | False | False | False | False | False | False | False | False | False | False | False | False |
| 890 | False | False | False | False | False | False | False | False | False | False | True | False |
这里我们只想要统计后有多少是空值呢?
我们可以添加一个sum()在后面,这样会统计使用isnull()判断为true的个数,效果如下
df.isnull().sum()PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
dtype: int64缺失值处理
使用None比较判断处理
我们可以使用None比较判断处理,示例如下
df[df['Age']==None]=0
df.head(3)| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th… | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
利用isnull()判断
df[df['Age'].isnull()] = 0
df.head(3)DataFrame.dropna()删除空值
删除缺失值
参数:
axis: {0 or ‘index’, 1 or ‘columns’}, default 0
指定如果有空值,按行删除(0/index),还是按列删除(1/columns)
axis=0或axis='index’删除含有缺失值的行 ----默认
axis=1或axis='columns’删除含有缺失值的列
how: {‘any’, ‘all’}, default ‘any’
当我们至少有一个NA时,确定是否从DataFrame中删除行或列
how='all’时表示删除全是缺失值的行(列)
how='any’时表示删除只要含有缺失值的行(列)--默认
thresh: int, 可选
表示保留至少含有n个非空 数值的行
thresh=2 保留至少两个非空 数值的行
subset: 列标签或标签序列,可选
指定在哪些列中查找缺失值
subset=['name', 'born'],删除在'name' 'born'列含有缺失值的行
示例:
df_dropna=df.dropna(how='any')
df_dropna.isnull().sum()PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 0
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 0
Embarked 0
dtype: int64DataFrame.fillna()赋值空值
参数:
| 参数 | 值 | 简介 |
|---|---|---|
| value | scalar, dict, Series, or DataFrame | 固定值填充 |
| method | {‘backfill’, ‘bfill’, ‘ffill’, None}, default None | ‘ffill’ 用前一个非空缺值填充;‘bfill’ 用后一个非空缺值填充 |
| axis | {0 or ‘index’} for Series, {0 or ‘index’, 1 or ‘columns’} for | ‘index’:按行填充;'columns’按列填充 |
| inplace | bool, default False | 是否用新生成的列表替换原列表 |
示例
df_fillna=df.fillna(value=0)
df_fillna.isnull().sum()PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 0
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 0
Embarked 0
dtype: int64重复值观察与处理
duplicated()找重复值
该方法可以找出表中数据的重复值
参数
subset=None/list,是需要标记重复的标签或标签序列
keep='first'/'last'/'False',是重复数据的标记方法。
first将除第一次出现以外的重复数据标记为True,
last将除最后一次出现以外的重复数据标记为True,
False将所有重复数据标记为True。
示例
df[df.duplicated()]drop_duplicates()删除重复值
用于删除表中数据的重复值
参数
subset=None/list,是需要标记重复的标签或标签序列
keep='first'/'last'/'False',是重复数据的标记方法,同duplicated()
inplace=Bool,是是否替代
示例
df = df.drop_duplicates()
df.head()| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th… | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S |
特征观察与处理
我们对特征进行一下观察,可以把特征大概分为两大类:
数值型特征:Survived ,Pclass, Age ,SibSp, Parch, Fare,其中Survived, Pclass为离散型数值特征,Age,SibSp, Parch, Fare为连续型数值特征
文本型特征:Name, Sex, Cabin,Embarked, Ticket,其中Sex, Cabin, Embarked, Ticket为类别型文本特征。
数值型特征一般可以直接用于模型的训练,但有时候为了模型的稳定性及鲁棒性会对连续变量进行离散化。文本型特征往往需要转换成数值型特征才能用于建模分析。
分箱操作是什么?
数据分箱(分桶/离散化)指的是以特定的条件将所有元素分类,实现数据的离散化,增强数据的稳定性。本质上就是把数据进行分组。
进行数据分箱的三种方法。
- loc & between
'''
将column中所有数据大小在bin(r1, r2)中的数据进行增添新label,需要对每个bin编写分箱代码,所以一般都是bin很少时使用。
between()函数中left为左边界,right为右边界,inclusive为是否包含哪个边界。
inclusive='left'/'right'/'both',可省略三个关键词。
'''
df.loc[df['column'].between(left=r1, right=r2, inclusive='both'), 'new_column'] = 'label'- cut
'''
参数说明:
x=df.['column'],是要分箱的column,必须是一维的。
right=Bool,是否包含最右边的边缘。
bins=list/number,list中元素是分箱每个bin的范围或number表示几分位数。
labels=list,list中是指定返回的bin的标签。必须与上面的 bins 参数长度相同(一一对应)。
include_lowest=Bool 第一个区间是否应该是左包含的。
precision=int 精度,表示小数几位。
duplicates=default/'raise'/'drop',如果bin边缘不是唯一的,'raise'则引发 ValueError而'drop'删除非唯一的。
retbins=Bool,是否返回bin的边界list。
ordered=Bool,表示标签是否有序。
'''
# 以下有具体值的为默认值
df['new_column'] = pd.cut(x=df['column'], right=True, bins = [range], labels = [label], include_lowest = False, precision=3, duplicates=default, retbins=False, ordered=True)- qcut
'''
参数说明:
x=df['column'],是要分箱的column,必须是一维的。
q=number/list,number表示几分位数,4表示四分位数等。list是分数list,例如[0, .25, .5, .75, 1.] 四分位数。
labels=list,list中是指定返回的bin的标签。必须与上面的 bins 参数长度相同(一一对应)。
retbins=Bool,是否返回bin的边界list。
precision=int,精度,表示小数几位。
duplicates=default/'raise'/'drop',如果bin边缘不是唯一的,'raise'则引发 ValueError而'drop'删除非唯一的。
'''
# 以下有具体值的为默认值
df['new_column'],cut_bin = pd.qcut(x=df['column'], q=number, labels=[label], retbins=False, precision=3, duplicates=default)查看类别文本变量名及种类
查看columns的数据类型可以使用.dtypes方法或.info(),查看类别文本变量名及分类可以使用.value_counts()方法和.unique()方法(前者可获得统计数量),nunique()方法可获得类别数量。
>>> df.dtypes
'''
输出:
PassengerId int64
Survived int64df
Fare float64
Cabin object
Embarked object
Age group category
dtype: object
'''
>>> df['Sex'].value_counts()
'''
输出:
Sex
male 453
female 261
Name: count, dtype: int64
'''
>>> df['Sex'].unique()
'''
输出:
array(['male', 'female'], dtype=object)
'''
>>>df['Sex'].nunique() # 输出: 2将文本标签替换成数值型标签的三种方法。
- replace
'''
参数说明:
to_replace=None/label/list...,其值是被replace的label或label list...
value=None/label/list...,其值是replace的label或label list...
inplace=Bool,如果True则替换原dataframe
regex=Bool,如果True则开启正则表达式匹配替换
'''
# 以下有具体值的为默认值
series.replace(to_replace=None, value=None, inplace=False, regex=False)- map
'''
参数说明:
arg为映射的字典或函数
na_action=None/'ignore',处理NaN值时,如果是ignore则会传播NaN不对NaN映射
'''
# 以下有具体值的为默认值
series.map(arg, na_action=None)- LabelEncoder
# 引入LabelEncoder
>>> from sklearn.preprocessing import LabelEncoder
# 创建encoder
>>> encoder = LabelEncoder()
# 向encoder中放入list,将n个类别编码为0~n-1之间的整数(包括0和n-1)
>>> encoder.fit([a, b, c])
# 使用encoder (标准化)
>>> answer = encoder.transform([b, c, a, a])
>>> answer # 输出:[1, 2, 0, 0]文本数据提取用.extract()方法。
'''
参数说明:
pat='str'/'正则表达式'
flags=int ,是来自re模块的标志
expand=Bool,True则返回每个捕获组有一列的数据框。False如果有一个捕获组,则返回序列/索引;如果有捕获组,则返回数据框。
'''
# 以下有具体值的为默认值
Series.str.extract(pat='', flags=0, expand=True)合并数据方法
concat()方法
可以沿着指定的轴将多个dataframe或者series拼接到一起,这一点和另一个常用的pd.merge()函数不同,pd.merge()函数只能实现两个表的拼接。
常用于将多个表合并成一张表
官方wiki介绍:点击跳转
参数:
axis:控制根据行/列添加合并
值:{0/’index’, 1/’columns’}, default 0
0为行添加(即上下堆叠),1为列后添加(左右堆叠),默认是行添加(0)
join:控制外连接还是内连接
值:{‘inner’, ‘outer’}, default ‘outer’
默认外连接(outer),保留两个表中的所有信息;如果设置成内连接(inner),拼接结果只保留两个表共有的信息
示例
list_up = [text_left_up,text_right_up]
result_up = pd.concat(list_up,axis=1)
result_up.head()merge()方法
pd.merge()函数只能实现两个表的拼接
官方wiki介绍:点击跳转
参数:
on:列名,join用来对齐的那一列的名字,用到这个参数的时候一定要保证左表和右表用来对齐的那一列都有相同的列名。
left_on:左表对齐的列,可以是列名,也可以是和dataframe同样长度的arrays。
right_on:右表对齐的列,可以是列名,也可以是和dataframe同样长度的arrays。
left_index/ right_index: 如果是True的haunted以index作为对齐的key
how:数据融合的方法。
sort:根据dataframe合并的keys按字典顺序排序,默认是,如果置false可以提高表现
示例:
result_up = pd.merge(text_left_up,text_right_up,left_index=True,right_index=True)
result_down = pd.merge(text_left_down,text_right_down,left_index=True,right_index=True)
result = resul_up.append(result_down)
result.head()DataFrame对象中的join()方法
dataframe内置的join方法是一种快速合并的方法。主要基于两个dataframe的索引进行合并,它默认以index作为对齐的列。
官方wiki介绍:点击跳转
参数(机翻)
other:DataFrame, Series, or a list containing any combination of them
索引应与此列中的一列类似。如果 Series 被传递,必须设置其 name 属性,这将是 用作生成的联接 DataFrame 中的列名。
on:str, list of str, or array-like, optional
调用方中要联接索引的列或索引级别名称 否则,否则联接索引。如果多个 给定的值,则其他 DataFrame 必须具有 MultiIndex。能 将数组作为连接键传递(如果该数组尚未包含在 调用 DataFrame。就像 Excel VLOOKUP 操作一样。
how:{‘left’, ‘right’, ‘outer’, ‘inner’, ‘cross’}, default ‘left’
如何处理这两个对象的操作。
- left:使用调用帧的索引(如果指定了 ON,则使用列)
- right:使用其他索引。
- outer:调用帧索引(如果 on 为 则为列)的并集 指定)与其他人的索引,并按词典排序。
- inner:调用帧索引(或列,如果 on)替换为其他索引,保留顺序 召唤的那个。
- cross:从两个帧创建笛卡尔积,保留顺序 的左键。
lsuffix:str, default ‘’
要从左框架的重叠列中使用的后缀。
rsuffix:str, default ‘’
要从右框架的重叠列中使用的后缀。
sort:bool, default False
按联接键按字典顺序对结果 DataFrame 进行排序。如果为 false, 联接键的顺序取决于联接类型(HOW 关键字)。
示例
resul_up = text_left_up.join(text_right_up)
result_down = text_left_down.join(text_right_down)
result = result_up.append(result_down)
result.head()表格旋转/转置方法
stack和unstack是针对pandas的轴进行重新排列的两个方法,二者互为逆操作:
stack
stack函数的主要作用是将原来的列转成最内层的行索引,转换之后都是多层次索引。
官方wiki介绍:点击跳转
官方原文:
Stack the prescribed level(s) from columns to index.
使用方法为:
pd.stack(level=-1, dropna=True)- level表示的是转换的是最内层(倒数第一级)
- dropna表示的是对缺失值的处理
参数
level:int, str, list, default -1
要从列轴堆叠到索引上的级别 轴,定义为一个索引或标签,或索引列表 或标签。
dropna:bool, default True
是否在生成的帧/系列中删除行 缺失值。将列级别堆叠到索引上 轴可以创建索引值和列值的组合 原始 DataFrame 中缺少的内容。
sort:bool, default True
是否在生成的帧/系列中删除行 缺失值。将列级别堆叠到索引上 轴可以创建索引值和列值的组合 原始 DataFrame 中缺少的内容。
示例
数据集
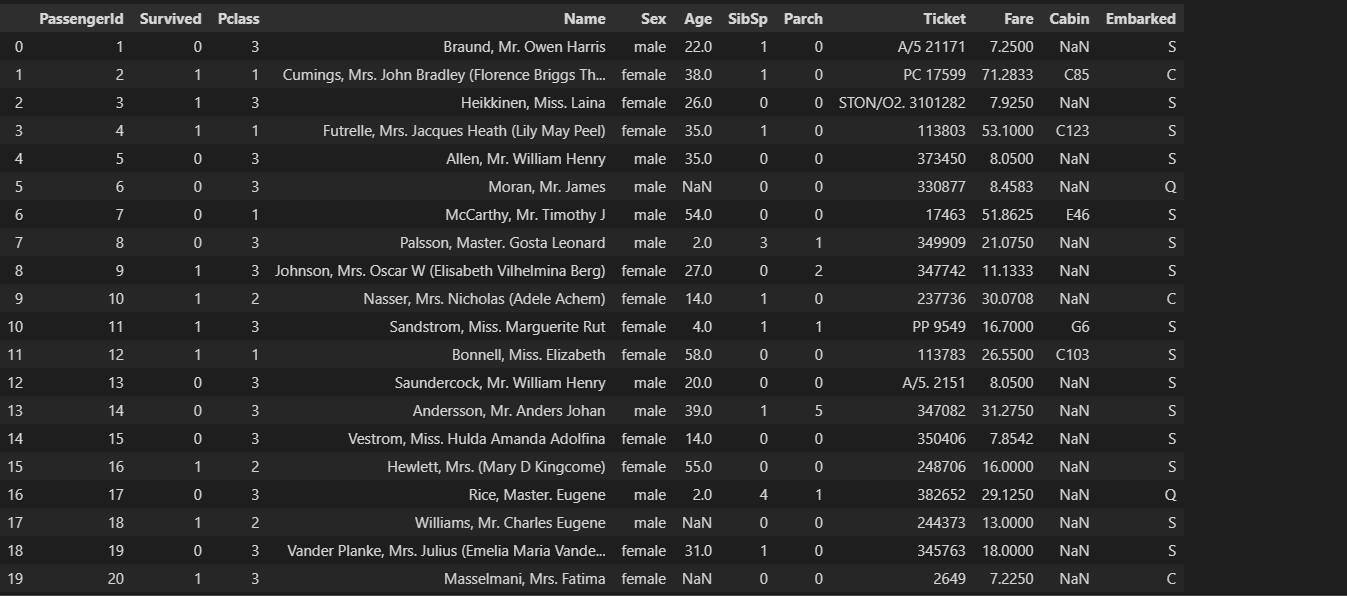
unit_result=text.stack().head(20)
unit_result.head()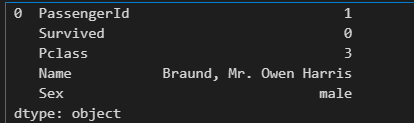
Pandas的GroupBy机制
在数据分析过程中,描述数据是对具有某些特征的列进行的,分析结果也需要对具体的组进行对比分析,GroupBy就是能满足这种需求的一种分组机制。GroupBy的应用包括三个流程:
(split - apply - combine)
- Splitting: 将数据按需求分组;
- Applying: 对每个小组进行函数操作;
- Combining: 合并结果。
按需求分组
my_group1=titanic.groupby('pclass')按分组求平均值
我们以计算泰坦尼克号男性与女性的平均票价为例
df = text['Fare'].groupby(text['Sex'])
means = df.mean()
means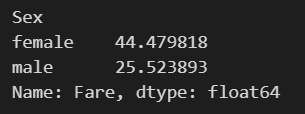
按分组求和
添加sum()方法
例如统计泰坦尼克号中男女的存活人数
survived_sex =text['Survived'].groupby(text['Sex']).sum()
survived_sex.head()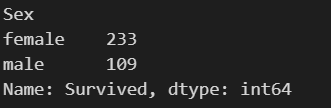
数据可视化
我们使用matplotlib.pyplot 对已处理的数据进行数据可视化生成图表
matplotlib.pyplot
Pyplot 是 Matplotlib 的子库,提供了和 MATLAB 类似的绘图 API。
Pyplot 是常用的绘图模块,能很方便让用户绘制 2D 图表。
Pyplot 包含一系列绘图函数的相关函数,每个函数会对当前的图像进行一些修改,例如:给图像加上标记,生新的图像,在图像中产生新的绘图区域等等。
.bar()绘制柱状图
bar()函数概述
bar()函数用于绘制柱状图。
bar()的返回值为BarContainer对象,其中patche属性为Rectangle列表,即一系列柱子。
bar()函数基础参数
bar()的基础参数如下:
x:柱子在x轴上的坐标。浮点数或类数组结构。注意x可以为字符串数组!height:柱子的高度,即y轴上的坐标。浮点数或类数组结构。width:柱子的宽度。浮点数或类数组结构。默认值为0.8。bottom:柱子的基准高度。浮点数或类数组结构。默认值为0。align:柱子在x轴上的对齐方式。字符串,取值范围为{'center', 'edge'},默认为'center'。
'center':x位于柱子的中心位置。
'edge':x位于柱子的左侧。如果想让x位于柱子右侧,需要同时设置负width 以及align='edge'。
柱子的位置由x以及align确定 ,柱子的尺寸由height和 width 确定。垂直基准位置由bottom确定(默认值为0)。大部分参数即可以是单独的浮点值也可以是值序列,单独值对所有柱子生效,值序列一一对应每个柱子。
示例
2.7.2 任务二:可视化展示泰坦尼克号数据集中男女中生存人数分布情况(用柱状图试试)。
sex = text.groupby('Sex')['Survived'].sum()
sex.plot.bar()
plt.title('survived_count')
plt.show()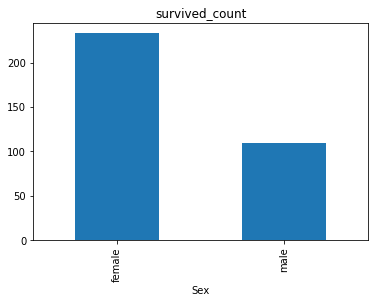
.plot 绘制函数
plot函数的一般的调用形式:
#单条线:
plot([x], y, [fmt], data=None, **kwargs)
#多条线一起画
plot([x], y, [fmt], [x2], y2, [fmt2], ..., **kwargs)可选参数[fmt] 是一个字符串来定义图的基本属性如:颜色(color),点型(marker),线型(linestyle),
具体形式 fmt = '[color][marker][line]'
| 参数 | 说明 |
|---|---|
| label | 用于图例的标签 |
| ax | 要在其上进行绘制的matplotlib subplot对象。如果没有设置,则使用当前matplotlib subplot |
| style | 将要传给matplotlib的风格字符串(for example: ‘ko–’) |
| alpha | 图表的填充不透明(0-1) |
| kind | 可以是’line’, ‘bar’, ‘barh’, ‘kde’ |
| logy | 在Y轴上使用对数标尺 |
| use_index | 将对象的索引用作刻度标签 |
| rot | 旋转刻度标签(0-360) |
| xticks | 用作X轴刻度的值 |
| yticks | 用作Y轴刻度的值 |
| xlim | X轴的界限 |
| ylim | Y轴的界限 |
| grid | 显示轴网格线 |
示例
2.7.3 任务三:可视化展示泰坦尼克号数据集中男女中生存人与死亡人数的比例图(用柱状图试试)。
# 提示:计算男女中死亡人数 1表示生存,0表示死亡
text.groupby(['Sex','Survived'])['Survived'].count().unstack().plot(kind='bar',stacked='True')
plt.title('survived_count')
plt.ylabel('count')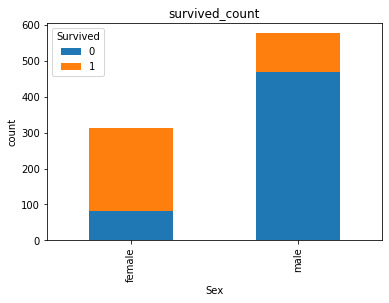
2.7.4 任务四:可视化展示泰坦尼克号数据集中不同票价的人生存和死亡人数分布情况。(用折线图试试)(横轴是不同票价,纵轴是存活人数)
# 计算不同票价中生存与死亡人数 1表示生存,0表示死亡
fare_sur = text.groupby(['Fare'])['Survived'].value_counts().sort_values(ascending=False)
fare_surFare Survived
8.0500 0 38
7.8958 0 37
13.0000 0 26
7.7500 0 22
13.0000 1 16
..
7.7417 0 1
26.2833 1 1
7.7375 1 1
26.3875 1 1
22.5250 0 1
Name: Survived, Length: 330, dtype: int64# 排序后绘折线图
fig = plt.figure(figsize=(20, 18))
fare_sur.plot(grid=True)
plt.legend()#添加图例
plt.show()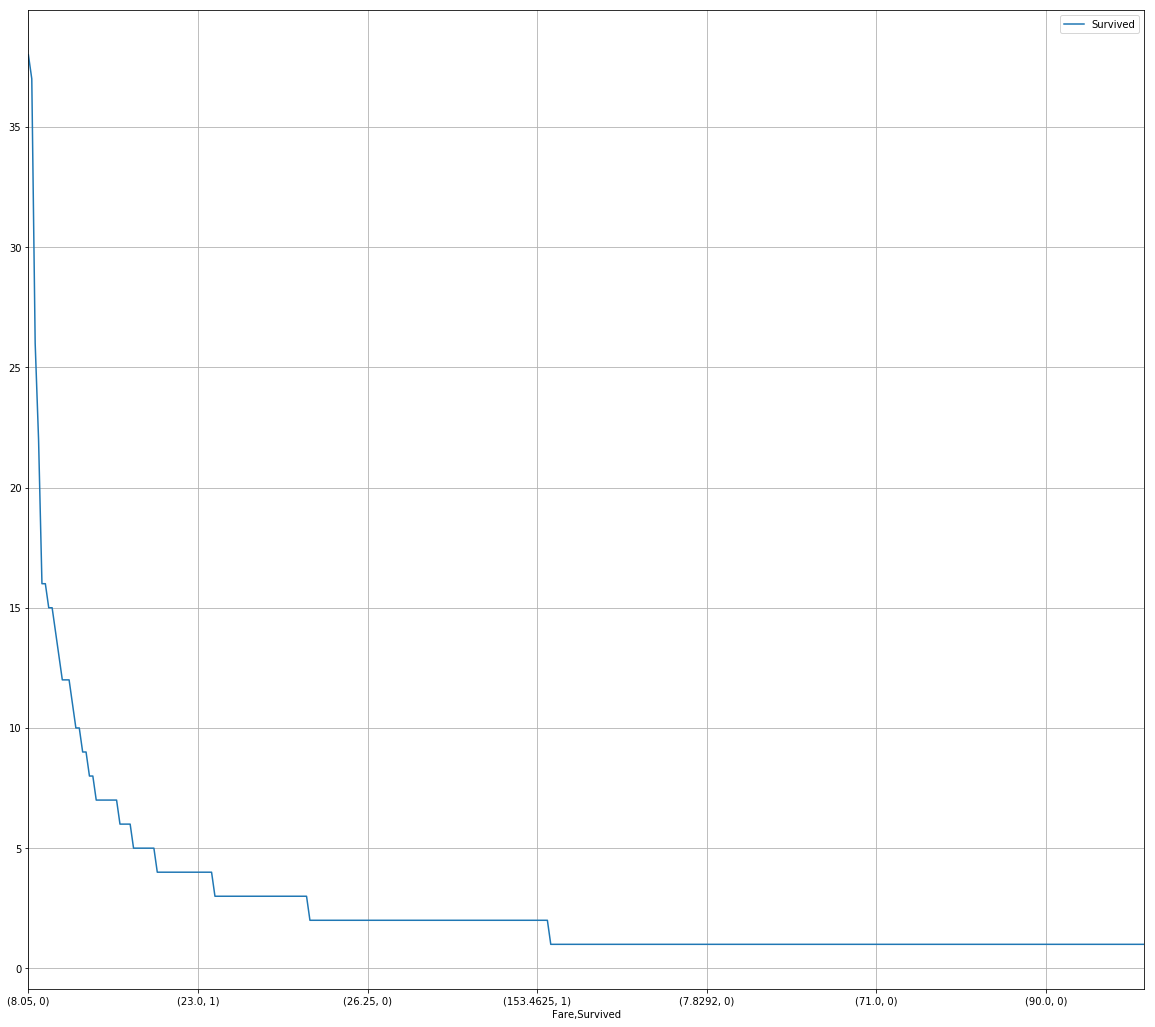
# 排序前绘折线图
fare_sur1 = text.groupby(['Fare'])['Survived'].value_counts()
fare_sur1Fare Survived
0.0000 0 14
1 1
4.0125 0 1
5.0000 0 1
6.2375 0 1
..
247.5208 1 1
262.3750 1 2
263.0000 0 2
1 2
512.3292 1 3
Name: Survived, Length: 330, dtype: int64fig = plt.figure(figsize=(20, 18))
fare_sur1.plot(grid=True)
plt.legend()
plt.show()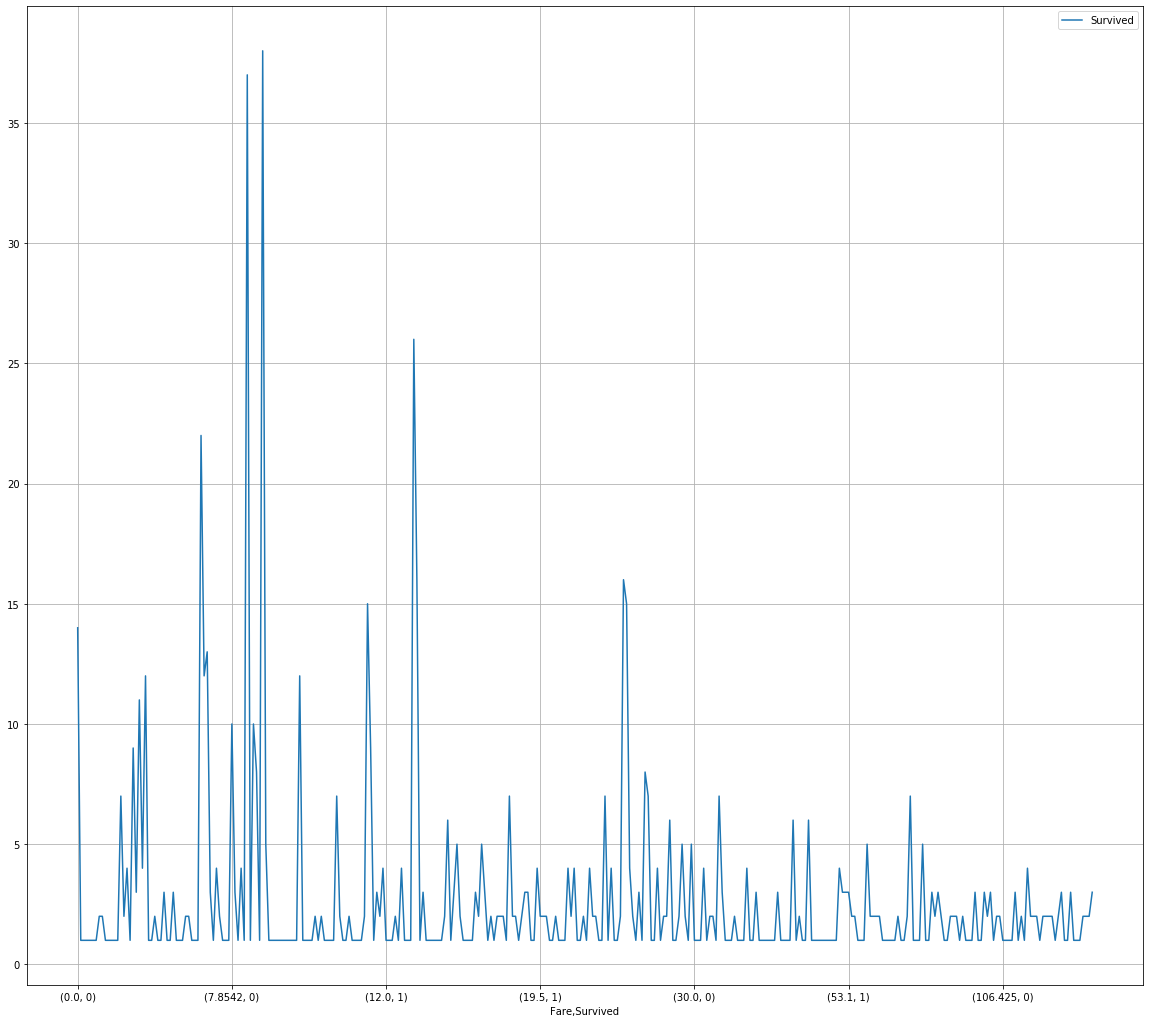
seaborn库的简介
Seabn是一个在Python中制作有吸引力和丰富信息的统计图形的库。它构建在MatPultLB的顶部,与PyDATA栈紧密集成,包括对SIMPY和BANDA数据结构的支持以及SISPY和STATSMODEL的统计例程。
Seaborn 其实是在matplotlib的基础上进行了更高级的 API 封装,从而使得作图更加容易 在大多数情况下使用seaborn就能做出很具有吸引力的图,而使用matplotlib就能制作具有更多特色的图。应该把Seaborn视为matplotlib的补充。Seabn是基于MatPultLB的Python可视化库。它为绘制有吸引力的统计图形提供了一个高级接口。
.countplot() 绘制柱状图
默认参数
seaborn.countplot(x=None, y=None, hue=None,
data=None, order=None, hue_order=None,
orient=None, color=None, palette=None,
saturation=0.75, dodge=True, ax=None, **kwargs)输入数据可以通过多种格式传递:
1.list、numpy数组、pandas
2.long-form DataFrame
3.wide-form DataFrame
4.在大多数情况下,可以使用numpy或Python对象,但推荐使用pandas对象,
因为关联的名称将用于注释轴。
此外,使用分类类型来分组变量来控制绘图元素的顺序。
可选:x,y,hue:数据变量的名称(如上表,date,name,age,sex为数据字段变量名)
用于绘制数据的输入
data: DataFrame,数组或数组列表
用于绘图的数据集,如果x和y不存在,则将其解释为 wide-form,
否则它被认为是 long-form
order, hue_order:字符串列表
指定绘制分类级别,否则从数据对象推断级别
orient: v | h
图的显示方向(垂直或水平,即横向或纵向),这通常可以从输入变量的dtype推断得到
palette:调色板名称,list列表,dict字典
用于对变量调不同级别的颜色
saturation(饱和度):float
用于绘制颜色的原始饱和度的比例,如果希望绘图颜色与输入颜色规格完美匹配,
则将其设置为1
dodge:bool
使用色调嵌套时,是否应沿分类轴移动元素。
示例
2.7.5 任务五:可视化展示泰坦尼克号数据集中不同仓位等级的人生存和死亡人员的分布情况。(用柱状图试试)
# 1表示生存,0表示死亡
pclass_sur = text.groupby(['Pclass'])['Survived'].value_counts()
pclass_surPclass Survived
1 1 136
0 80
2 0 97
1 87
3 0 372
1 119
Name: Survived, dtype: int64import seaborn as sns
sns.countplot(x="Pclass", hue="Survived", data=text)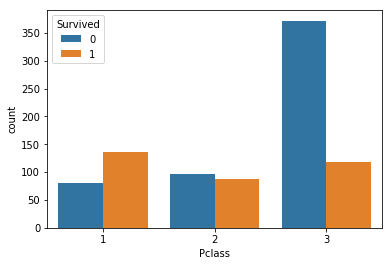
Comments 1 条评论
大佬我来了(doge)